On May-23, 2018 we delivered the webinar “A gentle introduction to Artificial Intelligence in Pharma. Text-based sources”. Although it’s hard to believe, the level of marketing hype around Artificial Intelligence has even surpassed the one about digital transformation or Big Data.
Artificial intelligence (AI) is the ability of a computer program or a machine to think and learn.
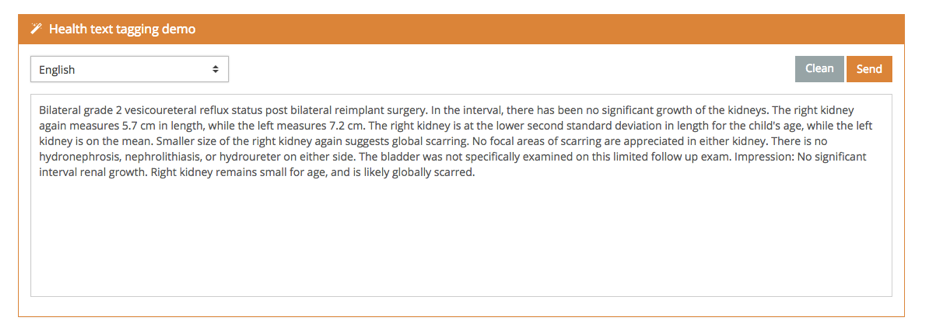
Did you know that in the Pharma industry, up to 80% of business-relevant information is made up of text?
We see that AI is transforming the Pharma industry from top to bottom.
During the session we covered these items:
- Introduction to Artificial Intelligence.
- How they create value with text-based sources.
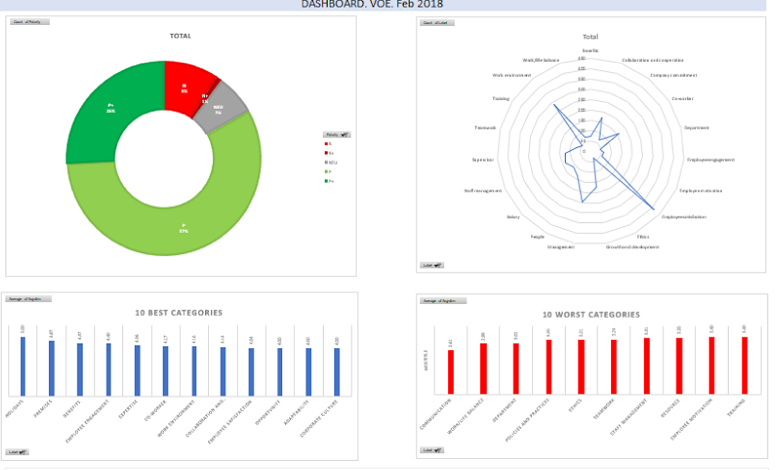
- Case study: analysis of the Voice of the Patient.
Interested? Here you have the presentation and the recording of the webinar.