Getting meaningful insights from natural language is no easy task. Text analytics value and accuracy grow as we add different layers of resources to the procedure. We explain how text analytics is like a multi-tiered wedding cake.

Getting meaningful insights from natural language is no easy task. Text analytics value and accuracy grow as we add different layers of resources to the procedure. We explain how text analytics is like a multi-tiered wedding cake.
Before setting out on a quest to discover customer expectations, preferences, and aversions, you must know your allies, enemies, and weapons.
But, be on guard, since dangers lurk in the horizon…

For insurance companies, it is vital to listen and understand the feedback that their current and potential customers express through all kinds of channels and touch points. All this valuable information is known as the Voice of the Customer. By the way, we had already dedicated a blog post to Text mining in the Insurance industry.
(This post is a based upon the presentation given by Meaning Cloud at the First Congress of Big Data in the Spanish Insurance Industry organized by ICEA. We have embedded our PPT below).
More and more insurance companies have come to realize that, as achieving product differentiation at the industry is not easy at all, succeeding takes getting satisfied customers.
Listening, understanding and acting on what customers are telling us about their experience with our company is directly related to improving the user experience and, as a result, the profitability. In the post on Voice of the Customer and NPS, we saw in more detail this correlation between customer experience and benefits.
In the last decade, sentiment analysis (SA), also known as opinion mining, has attracted an increasing interest. It is a hard challenge for language technologies, and achieving good results is much more difficult than some people think. The task of automatically classifying a text written in a natural language into a positive or negative feeling, opinion or subjectivity (Pang and Lee, 2008), is sometimes so complicated that even different human annotators disagree on the classification to be assigned to a given text. Personal interpretation by an individual is different from others, and this is also affected by cultural factors and each person’s experience. And the shorter the text, and the worse written, the more difficult the task becomes, as in the case of messages on social networks like Twitter or Facebook.
You have enough to worry about. You know your industry inside and out. You know your products and services and how they compare with the competition’s strengths and weaknesses. In business, you have to be an expert in a range of topics. What you don’t need to worry about are the ins and outs of every technology, algorithm and software program.
This is especially true of an inherently complex technology such as natural language processing. As a business owner you have enough to worry about. Do you really have time to understand morphological segmentation? Text analytics should be just another tool in your toolbox to achieve your business goals. The only thing you need to know is what problems you have that can be solved by natural language processing. Anaphoric referencing? Don’t worry about it. We have it covered it, along with anything else you might need from language technology.

Text analytics goes by many names: natural language processing (NLP), text analysis, text mining, computational linguistics. There are shades of difference in these terms, but let the expert work that out. What you need to know is that these terms describe a variety of algorithms and technology that is able to process raw text written in a human language (natural language) to provide enriched text. That enrichment could mean a number of things:
We have just published a new release of MeaningCloud with some new features that will change your way of doing text analytics. As a complement to the most common analytical techniques -which extract information or classify a text according to predefined dictionaries and categories- we have included unsupervised learning techniques that enable to explore a series of documents to discover and extract unexpected insights (subjects, relationships) from them.
In this new release of MeaningCloud we have published a Text Clustering API that allows to discover the implicit structure and the meaningful subjects embedded in the contents of your documents, social conversations, etc. This API takes a set of texts and distributes them in groups (clusters) according to the similarity between the contents of each document. The aim is to include in each cluster documents that are very similar to each other and, at the same time, highly different from the ones included in other clusters.
Clustering is a technology traditionally used in the analysis of structured data. What is so special about our API is that its pipelines are optimized for analyzing unstructured text.

We agree that it is not typical at all for an Information Technology company to talk about antidepressants and pregnancy in its own blog. But here at MeaningCloud we have realized that health issues have a great impact on social networks, and the companies from that industry, including pharmas, should try to understand the conversation which arises around them. How? Through text analysis technology, as discussed below.
Looking at the data collected by our prototype for monitoring health issues in social media, we were surprised by the sudden increase in mentions of the term ‘pregnancy’ on July 10. In order to understand the reason of this fact, we analyzed the tweets related to pregnancy and childbearing. It turned out that the same day a piece of news on a study issued by the British Medical Journal about the harmful effects that antidepressants can have on the fetus had been published.
Continue reading
According to IBM, “Cognitive Computing systems learn and interact naturally with people to extend what either humans or machines could do on their own. They help human experts make better decisions by penetrating the complexity of Big Data.” Dharmendra Modha, Manager of Cognitive Computing at IBM Research, talks about cognitive computing as an algorithm being able to solve a vast array of problems.
With this definition in mind, it seems that this algorithm requires a way to interact with humans in order to learn and to think as they do. Nice, great words! Anyway, it is the same well-known goal of Artificial Intelligence (AI), a more common name that almost everybody has heard about. Why change it? Ok, when a company is investing at least $1 billion in something, it must be cool and fancy enough to draw people’s attention, and AI is quite old-fashioned. Nevertheless, machines still cannot think! And I believe it will take some time.
How does Cognitive Computing work? According to the given definition, to enable the human-machine interaction, some kind of voice and image processing solutions must be integrated. I am not an expert on image processing, but voice recognition systems, dialog management models and Natu ral Language Processing techniques have been studied for a while. Even Question Answering methods (i.e. the ability of a software system to return the exact answer to a question instead of a set of documents as traditional search engines do) have been deeply studied. We ourselves have been doing (and still do) research on this topic since 2007, which resulted in the development of virtual assistants, a combination of dialogue management and question answering techniques. Do you remember Ikea’s example called Anna? In spite of the fame she gained at that time, she is not working anymore. Perhaps, for users, that kind of interaction through a website was not effective enough. On the other hand, virtual assistants like Siri, supported by an enormous company as Apple, are gaining attention. There are other virtual assistants for environments different from iOS but they are far less known, perhaps because the companies behind them are quite smaller than Apple.
ral Language Processing techniques have been studied for a while. Even Question Answering methods (i.e. the ability of a software system to return the exact answer to a question instead of a set of documents as traditional search engines do) have been deeply studied. We ourselves have been doing (and still do) research on this topic since 2007, which resulted in the development of virtual assistants, a combination of dialogue management and question answering techniques. Do you remember Ikea’s example called Anna? In spite of the fame she gained at that time, she is not working anymore. Perhaps, for users, that kind of interaction through a website was not effective enough. On the other hand, virtual assistants like Siri, supported by an enormous company as Apple, are gaining attention. There are other virtual assistants for environments different from iOS but they are far less known, perhaps because the companies behind them are quite smaller than Apple.
Several aspects of the thinking capabilities required by the mentioned algorithm have to do with the concept of Machine Learning. There are a lot of well-known algorithms which are able to generate models from a set of examples or even from raw data (in the case of unsupervised processes). This enables a machine to learn how to classify things or to group items together, like a baby piling up those coloured geometric pieces. So, combining Machine Learning and NLP models it is possible for a machine to understand a text. This process is what we call Structuring Unstructured Data (much less fancy than Cognitive Computing). That is, making your information actionable. We have been working on this during several years, but now it is called cognitive computing.
So, as you might imagine, Cognitive Computing techniques are not different from the ones we have already developed; a lot of researchers and companies have been combining them. And, if you think about it, does it really matter if a machine thinks or not? The relevant added value of this technology is helping humans to do their job with all the relevant information at hand, at the right moment, so they can make thoughtful and reasonable decisions. This is our goal at MeaningCloud.
Seth Grimes is one of the leading industry analysts covering the text analytics sector. As part of his annual year-past/look-ahead report on this technology and market developments, Seth polled a group of industry executives, asking their thoughts on the state of the market and prospects for the year ahead.
is one of the leading industry analysts covering the text analytics sector. As part of his annual year-past/look-ahead report on this technology and market developments, Seth polled a group of industry executives, asking their thoughts on the state of the market and prospects for the year ahead.
José Carlos González, CEO of Daedalus / MeaningCloud, was one of the selected executives. In the interview, Seth and José Carlos discuss industry perspectives, technology advances and the “breadth vs depth” dilemma faced by many text analytics vendors.
This is an excerpt from the interview:
What should we expect from your company and from the industry in 2015?
Voice of the Customer (VoC) analytics — and in general, all the movement around customer experience — will continue being the most important driver for the text analytics market.
The challenge for the years to come will consist in providing high-value, actionable insights to our clients. These insights should be integrated with CRM systems to be treated along with structured information, in order to fully exploit the value of data about clients in the hands of companies. Privacy concerns and the difficulties to link social identities with real persons or companies, will be still a barrier for more exploitable results.
———
Interested? Read the rest of the interview –featuring market developments and company and product strategies- on Seth Grimes’ blog.

The traditional access channels to the public emergency services (typically the phone number 112 in Europe) should be extended to the real-time analysis of social media (web 2.0 channels). This observation is the starting point of one of the lines which the Telefónica Group (a reference global provider of integrated systems for emergency management) has been working in, with a view to its integration in its SENECA platform.
At Daedalus (now MeaningCloud) we have been working for Telefónica in the development of a social dashboard that analyzes and organizes the information shared in social networks (Twitter, initially) before, during and after an incident of interest to emergency care services. From the functional point of view, this entails:

Love Parade Duisburg
Anticipation of events which, due to their unpredictability or unknown magnitude, should be object of further attention by the emergency services. Within this scenario are the events involving gatherings of people which are called, spread or simply commented through social networks (attendance to leisure or sport events, demonstrations, etc.). Predicting the dimensions and scope of these events is fundamental for planning the operations of different authorities. We recall in this respect the case of the disorders resulting from a birthday party called on Facebook in the Dutch town of Haren in 2012 or the tragedy of the Love Parade in Duisburg.

Flood in Elizondo, Navarre, 2014
Social networks enable the instant sharing of images and videos that are often sources of information of the utmost importance to know the conditions of an emergency scenario before the arrival of the assistance services. User-generated contents can be incorporated to an incident’s record in real time, in order to help clarify its magnitude, the exact location or an unknown perspective of the event.

For the analysis of social content, the text analytics semantic technology (text mining) of MeaningCloud is employed. Its cloud services are used to:
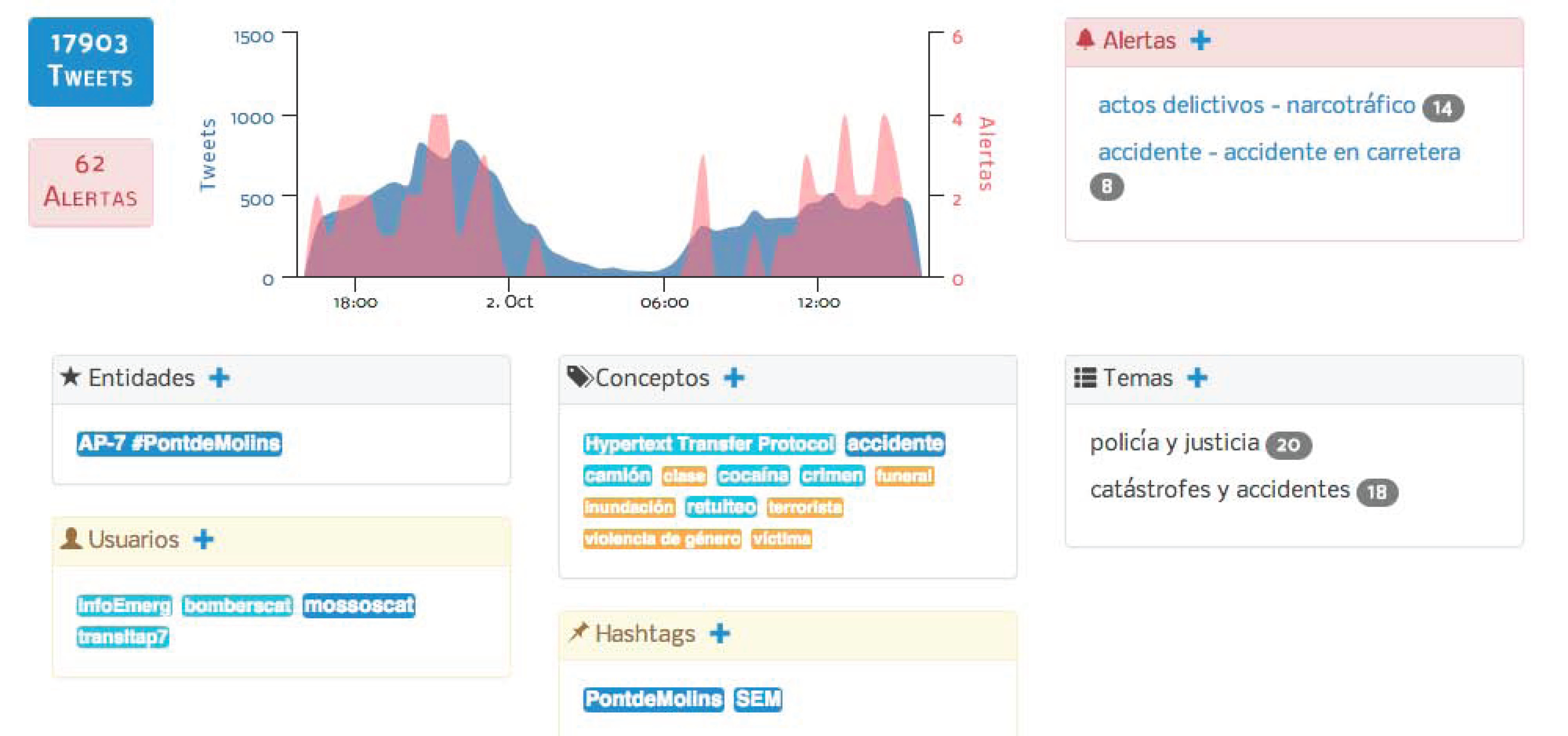
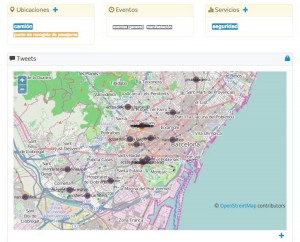 A multidimensional social perspective
A multidimensional social perspectiveText analytics components are integrated into a web application that constitutes a complete social dashboard offering three perspectives:


Telefónica and Daedalus (now MeaningCloud) will jointly present these solutions at the LT-Accelerate conference (organized by LT-Innovate and Seth Grimes), which will be held in Brussels, on December 4 and 5, 2014. We invite you to join us and visit our stand as sponsor of this event. We will tell you how we use language processing technologies for the benefit of our customers in this and other industries.
Register at LT-Accelerate. It is the ideal forum in Europe for the users and customers (current or potential) of text analysis technologies.
![]()

Jose C. Gonzalez (@jc_gonzalez)
[Translation from Spanish by Luca de Filippis]

2024 © All Rights Reserved | Data protection policy | Terms and conditions | Data Processing Agreement MeaningCloud is a trademark by MeaningCloud LLC

{kind=link}