В MeaningCloud мы стремимся предоставить наиболее прогрессивный продукт для интеллектуального анализа текста с самым широким на рынке охватом языков. Именно поэтому до конца 2019 года мы работали над выпуском нескольких новых языковых пакетов для расширения охвата, обеспечиваемого нашим стандартным пакетом: английский, испанский, французский, итальянский, португальский и каталанский – а также нашим скандинавским пакетом: шведским, датским, норвежским и финским.
Вторым выпущенным пакетом стал русский. Русский является официальным языком в Российской Федерации, Белоруссии, Казахстане и Киргизии. Фактически он был разговорным языком в Советском Союзе, поэтому продолжает использоваться в странах Балтики, на Кавказе и в Центральной Азии. Это самый распространенный славянский язык, на котором говорят 144 миллиона человек.
В русской письменности используется кириллица, и хотя транслитерация на латиницу получила широкое распространение в связи с техническими ограничениями, связанными в отсутствием кириллической клавиатуры за рубежом, потребность в ней возникает все реже и реже благодаря расширению Юникод, включающему русский алфавит, которое обеспечивает работу множества программ.
MeaningCloud теперь предлагает охват русского языка для следующего функционала:
- Извлечение предметов: охватывает обнаружение объектов и частично выражений времени.
- Кластеризация текстов: полный охват.

Этот охват будет расширяться при последующих выпусках продуктов в зависимости от рыночного спроса. Более подробная информация представлена на нашей новой странице охвата языков.
Что же такое задачи интеллектуального анализа текста, и для чего они используются?
Извлечение предметов представляет собой продукт MeaningCloud для «автоматического извлечения структурированный информации из неструктурированных и (или) полуструктурированных машиночитаемых документов» [1]. Иными словами, извлечение предметов позволяет вычленить конкретные фрагменты данных из совокупности текстов: все, что угодно, от имен людей до мест и денежных сумм.
Существует множество названий этой задачи. Некоторые из них, например, выделение именованных сущностей, образовались из ее наиболее популярных подзадач. Однако цель остается неизменной: извлечение структурированной информации из текста.
На данных изображениях представлен пример объектов, обнаруженных в этой статье.

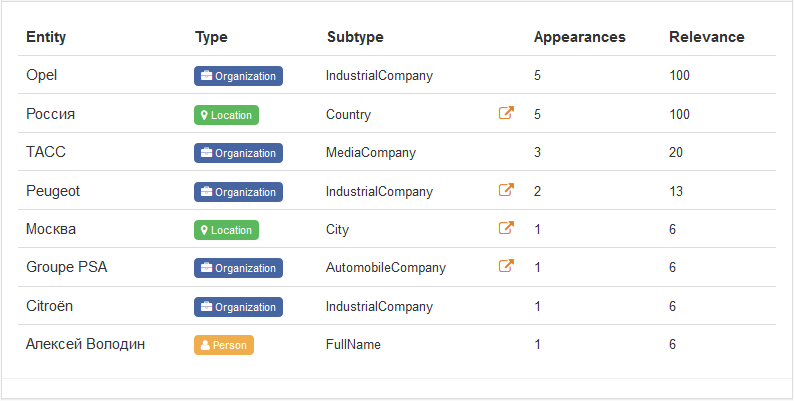
Поначалу может показаться, что все дело в поиске названий и имен, встречающихся в тексте, но этим все не ограничивается. Существует множество способов упоминания одного и того же человека, прозвищ и вариантов написания имени, которые следует учитывать. Иногда более чем достаточно обнаружения всех обозначенных в тексте объектов. Для таких случаев объекты имеют ассоциированный с ними тип, позволяющий выбрать извлечение исключительно мест, людей, организаций и пр. Можно проверить все типы, обнаруженные в нашей объектной модели.
Ниже представлено несколько сценариев, в которым может применяться извлечение предметов:
- Автоматическое предложение тегов для новостных статей или сообщений в блогах и семантические публикации
- Анализ популярности исходя из упоминаний
- Извлечение объектов ключевых данных
Кластеризация текстов осуществляет анализ кластеров, выполняет задачу «группировки набора объектов таким образом, чтобы объекты в одной группе (называемой кластером) были в большей степени похожи (в том или ином смысле) друг на друга, чем на объекты в других группах (кластерах)» [2].
В данном случае рассматриваемыми объектами являются тексты, и предлагаемые различные виды анализа могут помочь обнаружить в них паттерны либо для того, чтобы визуально рассортировать данные, либо, чтобы получить о них новые сведения, которые будут использоваться в качестве обратной связи для других видов анализа. Возможным путем использования кластеризации текстов является применение ее в отношении текстов, классифицируемых с помощью классификации текстов для выявления новых категорий с целью добавления к нашей модели.
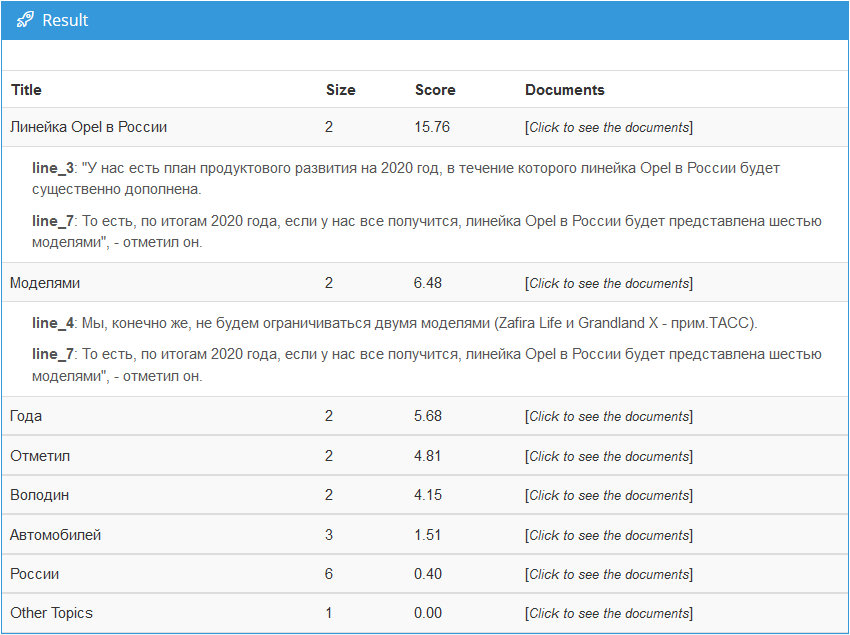
Справа представлен результат, полученный с помощью режима «моделирование предметов», который мы получим для некоторых частей текста, использованных для иллюстрации извлечения предметов.
Кластеризация текстов обычно используется как способ обнаружить ранее неизвестную информацию или новые тенденции в накоплении текстовых данных.
Существует два возможных способа протестировать весь функционал на русском:
- Запросить 30-дневный бесплатную пробную версию, которую мы предлагаем для всех пакетов.
- Подписаться на интересующий пакет.
И при обновлении до этого пакета на год вы получите скидку 50%! Просто выберите пакет «Russian Annual» (Русский годовой) в процессе обновления, и все готово. Только до 31 января 29 февраля 2020 года!
По любым вопросам обращайтесь по адресу support@meaningcloud.com.
