
This page refers to a previous version of the add-in for Excel (2007 to 2016)
For Excel 365, use the lastest add-in version
Text Clustering in Excel
The Text Clustering analysis integrates the functionality provided by the Text Clustering API. It allows automatic clustering of documents in order to group them by similarity and discover significant subjects.
This is the interface that will appear when you click the Text Clustering button:

You can see that there are two areas in the interface: Input, which we have already covered in the corresponding section, and Analysis Settings.
In Analysis Settings there are three elements to configure:
- Language, to select the language of the texts.
- Mode, to select the mode to use in the clustering process.
- Stopwords, to add terms that are not to be taken into account in the clustering process. To add a new stopword you just need to click on the button "Add" and write the new word. To remove a stopword, select it on the list and click on the button "Remove". The list will be saved from one analysis to the next.
Advanced Settings
We've seen in the Settings section that there's an advanced settings menu with additional configuration options for Text Clustering. These are the options for Text Clustering and their default values:

In this section you will be able to configure which fields are shown in the output:
- Cluster: displays the title assigned to the cluster. This field is not configurable, so it's always shown.
- Size: shows the size of the cluster.
- Rank: shows the order by relevance of the cluster for the document.
- Score: shows the relevance value assigned to the cluster.
There's more information about each one of these fields in the response section of the API documentation.
Output
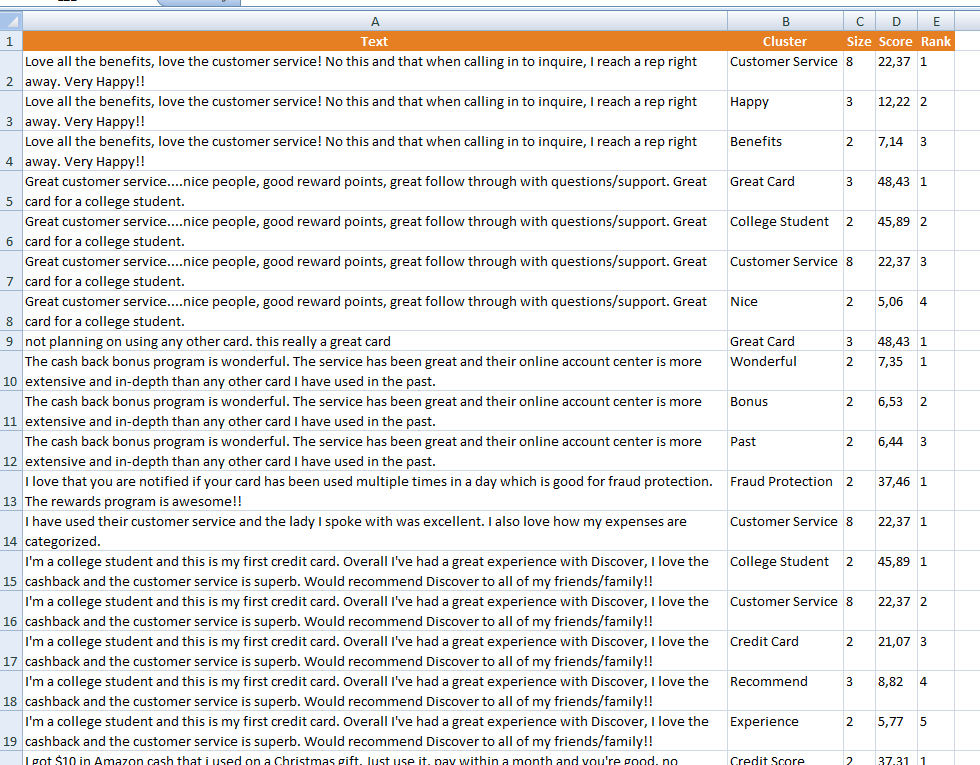
The results obtained from the analysis will be shown in a new Excel sheet called "Text Clustering". This sheet will include a column with the source text, a column with the IDs if enabled, and then a column for each of the output fields configured in the advanced settings.
When the document is included in more than one cluster, each additional cluster will be inserted as a new row. The original text and the ID will be behave as specify in the "Combine cells in the output" option in the Settings section.
This is an example of a possible output of a number of texts. We are not using IDs, the configuration is set to show all the possible output fields and the "Combine cells in the output" option is disabled:
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2024 © All Rights Reserved | Data protection policy | Terms and conditions | Data Processing Agreement MeaningCloud is a a trademark by MeaningCloud LLC