Integrations with third-party software are something extremely useful: they allow you to use technology outside the tool you are using, giving you additional features outside its core functionality or just providing auxiliary tools to make your day to day easier.
One of the downsides is that you are limited by the functionality the integration provides. Usually, this is not much of a problem as standard integrations tend to cover the most common use cases, but in the case of tools that can be used in many scenarios, these uses cases may not be exactly what you need or want for your application.
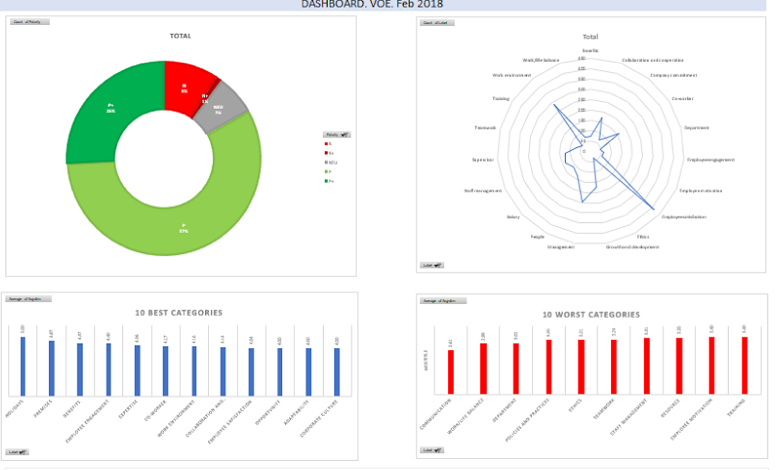
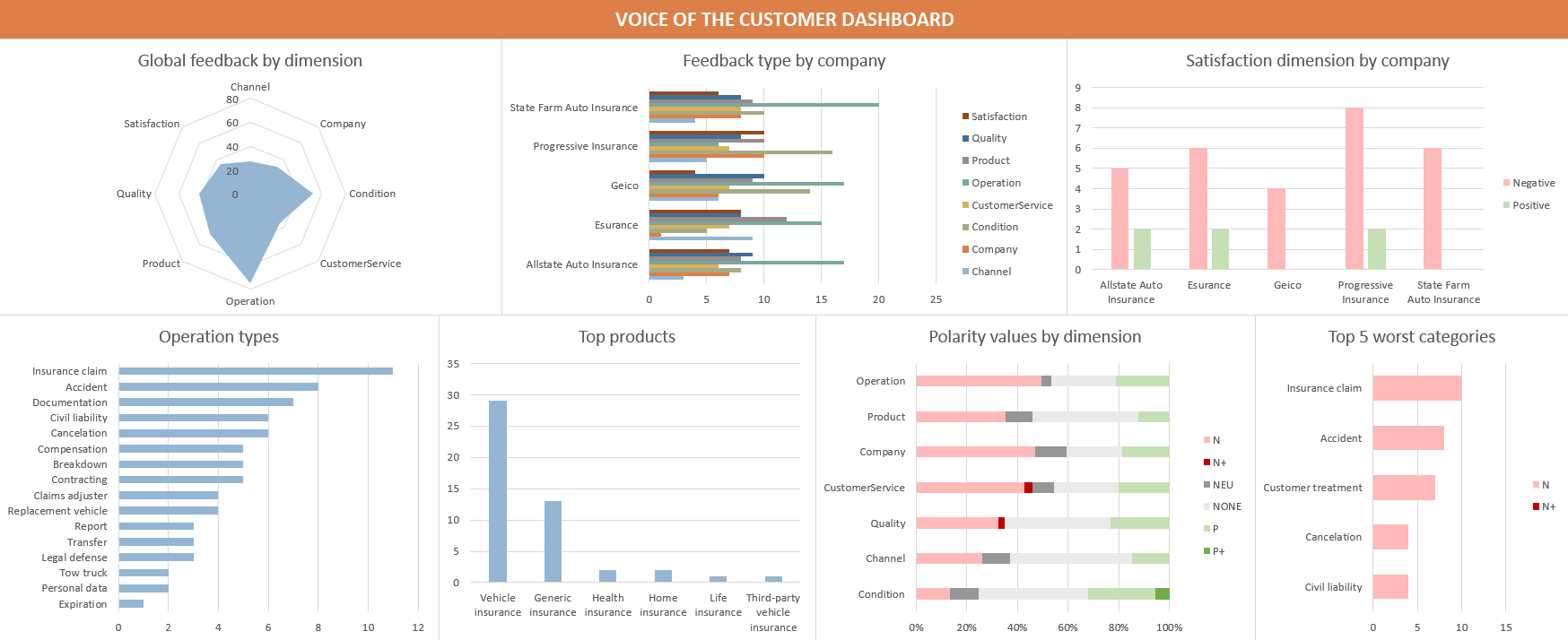
MeaningCloud is not an exception to this. We provide many different APIs, each one of them with several types of analyses and with tons of possible applications. It’s not surprising that not all of them are included in MeaningCloud’s extension for RapidMiner.
If you want something like the global polarity Sentiment Analysis provides, then the extension for RapidMiner has you covered, but it may not be the case for other analyses. It can go from wanting to use a MeaningCloud API not included in the extension such as the Summarization API or to something as small as needing the label of the resulting categories in an automatic classification process instead of the code the extension provides.
Last year, RapidMiner published a new Python scripting extension: Execute Python. This operator allows you to run a Python script in RapidMiner, which enables you to include any processing you want and can code in a Python script in your RapidMiner process.
Using this new functionality and MeaningCloud’s Python SDK, we can create a Python script to use any of MeaningCloud APIs directly from RapidMiner. The SDK enables us to work with the API output easily and to extract whatever information we want to add to our RapidMiner processes.
Let’s see how we can do this! Continue reading