
This page refers to a previous version of the add-in for Excel (2007 to 2016)
For Excel 365, use the lastest add-in version
Sentiment Analysis in Excel
The Sentiment Analysis integrates part of the functionality provided by the Sentiment Analysis API. It provides two levels of analysis to the user: a global, more general sentiment analysis of the whole text and a feature level analysis, where entities and concepts are extracted and their aggregated polarity in the text is obtained.
This is the interface that will appear when you click the Sentiment Analysis button:

We can see there are two areas in the interface: Input, which we have already covered in the corresponding section, and Analysis Settings.
In the Analysis Settings there are three values to select:
- Language, to select the language of the texts. By default, the language set as preferred in the General Settings will be preselected. The possible values are: Spanish, English, French, Catalan, Portuguese and Italian as well as the languages included in the Nordic pack, Danish, Swedish, Norwegian and Finnish.
- Model, with the model that will be used to measure the sentiment of the texts. The models listed are determined by the language selected in the previous menu. Currently, the only model available for English, Spanish and French is General but all the languages support user sentiment models defined in the sentiment models customization console with the user with the
keyconfigured in the addin. - User dictionary, to select if you want to use one of your user dictionaries in the analysis. The dictionaries that will appear in this menu are the ones created through the dictionaries customization console with the user with the
keyconfigured in the addin.

If no models are listed for the selected language, then you may not have access to any models for it. If it's a language that belongs to a language pack, make sure you have access to that pack!

Did you notice...?
All the resources that are part of any of our vertical or language packs appear with the cubes icon before the name. If you don't have access to them, make sure to request the free trial!
Advanced Settings
We've seen in the Settings section that there's an advanced settings menu with additional configuration options for the Sentiment Analysis. These are the options for Sentiment Analysis and their default values:

There are three different aspects of the output configuration that you will be able to customize:
- Analysis: where you can select which type of sentiment analysis you want to carry out. There are two possible values and at least one of them must be selected:
- Document, to extract the global sentiment analysis of a text.
- Topics, to extract the topics of a text and find the polarity associated to each one of them.
- Document Analysis: In this section you can configure which fields you want to output when you analyze the sentiment of a document. There are five possibilities:
- Polarity: shows the polarity tag obtained for the text. If no polarity has been detected, its value will be NONE; each value will have associated one of the following colors:

- Agreement: shows the agreement between the polarities detected in the text.
- Subjectivity: shows the subjectivity value obtained for the text.
- Confidence: shows the confidence value associated to the polarity detected for the text.
- Irony: shows if the text is considered ironic.
- Polarity: shows the polarity tag obtained for the text. If no polarity has been detected, its value will be NONE; each value will have associated one of the following colors:
- Topic Analysis: In this section you can configure which fields you want to output when you analyze the sentiment of the topics in a document. There are six options:
- Form: with the name by which the topic extracted is identified. It's non-configurable, so it always appears in the results.
- Topic category: shows the type of topic extracted, that is, if it's an entity or a concept.
- Rank: contains the order in which the topics have been detected. It's specific for each type of topic, that is, the first entity detected will be ranked 1, and the first concept will be ranked 1 too.
- Type: shows the type associated to the topic according to our ontology.
- Polarity: shows the polarity tag obtained for the topic. It behaves the same way as the polarity tag we've shown for Document Analysis.
- Sense ID: shows the ID of the topic detected.
There's more information about each one of these fields in the response section of the API documentation.
Output
There are two different types of sentiment analysis that can be carried out. Both of them will be shown in a new separate Excel sheet:
- the document-level analysis will be displayed in a sheet called "Global Sentiment Analysis".
- the feature-level analysis in a sheet called "Topics Sentiment Analysis".
This means that if both analyses are configured, Sentiment Analysis will result in two new Excel sheets.
Both sheets will include a column with the source text, a column with the IDs if enabled, and then a column for each one of the output fields configured in the advanced settings.
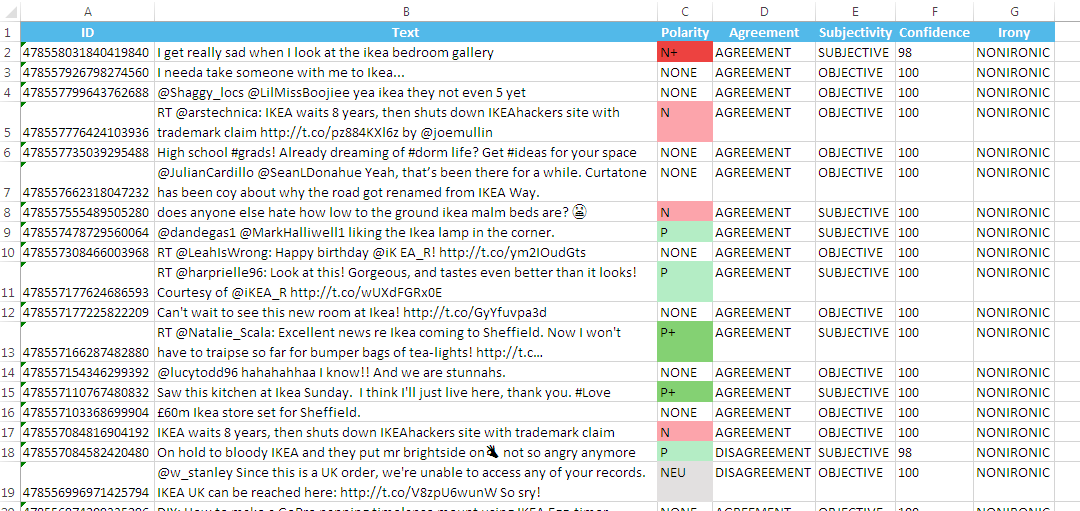
This is an example of a possible output of the document-level polarity of texts in English using the model General. The configuration is set to show all the possible output fields available with the IDs option enabled:
The following example will show a possible output of the sentiment analysis at a feature level, which will show the topics found in the text analyzed and also if each of those topics has a polarity associated. The analysis of the example has been carried out over a theater review in English, using the General model, and setting all the possible fields available to be shown in the output. In this case, we have not selected IDs in the input.
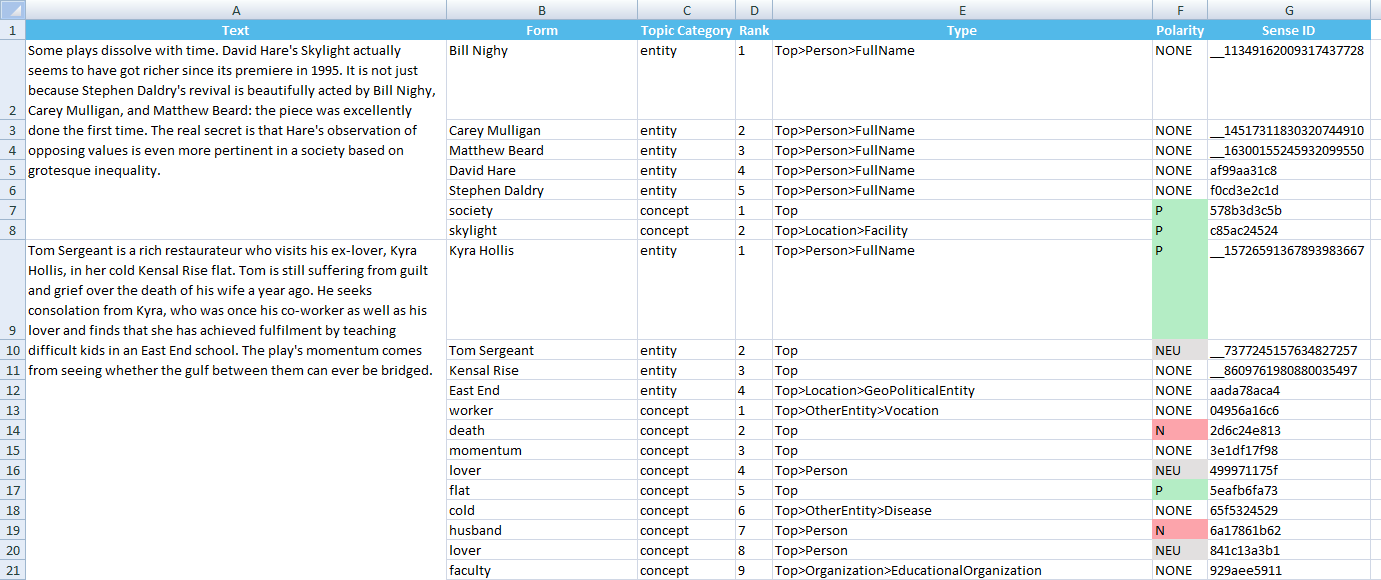
You can see in the image how each new topic found for a text is inserted in a new row, combining the cell where the text would go with the one that already contains it, letting you know easily from which text that topic has been extracted without the need to repeat it.
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2024 © All Rights Reserved | Data protection policy | Terms and conditions MeaningCloud is a a trademark by MeaningCloud LLC