
Deep Categorization
Deep Categorization assigns one or more categories to a text. The definition and criteria of those categories — that is, the taxonomy used in the classification — is determined by the model used.
There are two types of models you can use: predefined models, which are the ones MeaningCloud provides, and user-defined models, which you can develop using your own criteria in the deep categorization models console.
These are the settings for this recipe:
- Input parameters:
- Text column: the column names available in the dataset used as input source will be loaded, so you can select the one with the texts to analyze.
- Language: list of supported languages for predefined models.
- Predefined model: list of predefined models available.
- API configuration preset: license key and server to use in the API requests. It can be set using one of the presets defined in the plugin Settings or they can be manually defined.
- Number of categories: how many categories should be shown for a text. This determines the number of columns that will be added in the output dataset. Maximum value allowed is 10 and categories in the results will always be ordered by relevance.
- User model: user-defined model ID to use in the classification (instead of the value set in predefined model).
Important
Some of the predefined models are part of our vertical packs. You need to have access to them to use them in the classification successfully. If you don't have access to them, make sure to request the free trial or to subscribe to them!
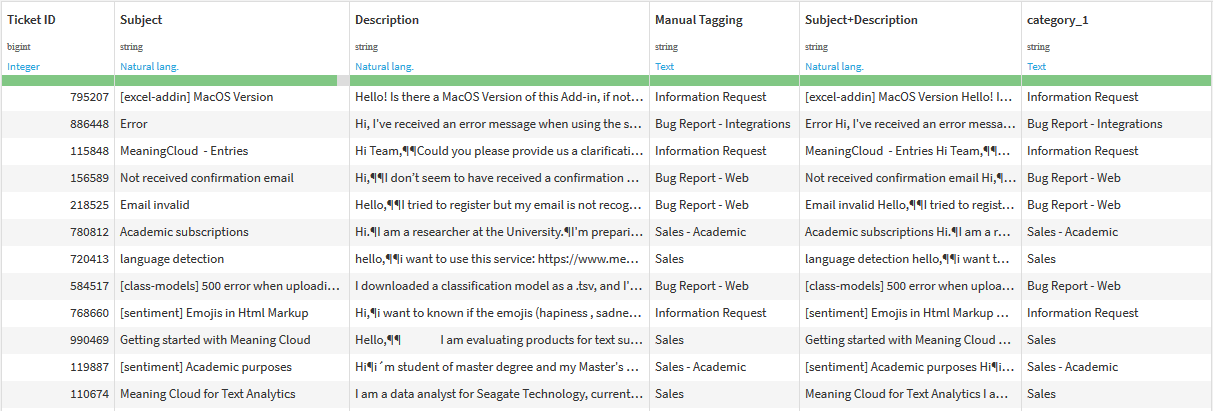
The new columns added to the output dataset will be named using the format "Category [N]", where N is the number of category. The following example uses the dataset and the user-defined model described in this tutorial. The number of categories selected is '1'.
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2024 © All Rights Reserved | Data protection policy | Terms and conditions | Data Processing Agreement MeaningCloud is a a trademark by MeaningCloud LLC