
Topics Extraction in Excel 365
Topics Extraction integrates the functionality provided by the Topics Extraction API. It allows to extract different kinds of topics from a text, easily and without any development.
On the right, you can see the sidebar that appears when you click the Extract topics button.
There are two sections in the interface: Select cells with texts to analyze, which we have already covered in the corresponding section, and Analysis settings.
In Analysis settings there are two elements to configure:
- Language, to select the language of the texts. Refer to the list of supported languages to learn about the languages available.
- User dictionary, to select one of your user dictionaries for the analysis. The dictionaries that will appear in this menu are the ones created through the dictionaries customization console that are associated to the license key configured in the settings panel.


Important
To be able to use any of our language packs, you need to have access to them! You can request access in the developer home or in the language packs section. You can read more about it here.
Advanced settings
The Advanced settings menu contains additional options for Topics Extraction. There are two differentiated sections: Input configuration, with the options with which you will call Topics Extraction, and Output configuration, to configure the output.
- Input configuration allows you to select which types of topics to extract from the text. There are six different types:
- Entities: named entities.
- Concepts: concepts.
- Time expressions: dates and times.
- Money expressions: amounts of money.
- Quantity expressions: quantities.
- Other expressions: alphanumeric patterns.
- Output configuration allows you to select the fields which you can obtain in the output:
- Form: displays the name by which the topic extracted is identified. It's not configurable, so it always appears in the results.
- Topic category: shows the type of topic extracted.
- Rank: contains the order in which the topics have been detected. It's specific for each type of topic, that is, the first entity detected will be ranked 1, and the first concept will be ranked 1 too, and so on.
- Type: shows the type associated to the topic according to our ontology.
- Theme: theme of the topic according to the ones described in our ontology.
- Frequency: number of times the topic appears in the text.
- Mentions: mentions of the topic in the text separated by commas.
- Sense ID: id of the topic (sense ID in the user dictionaries).

Output
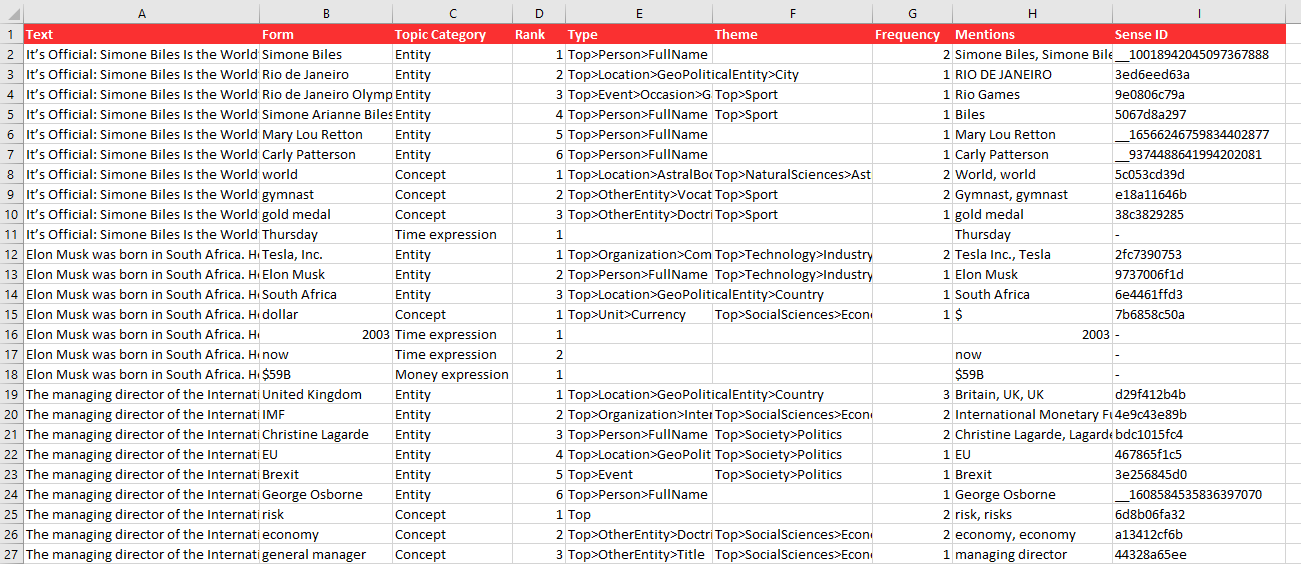
The results obtained from the analysis will be shown in a new spreadsheet called "Topics Extraction". This sheet will include a column with the source text, a column with the IDs if enabled, and a column for each of the output fields configured in the advanced settings.
This is an example of a possible output. It's configured to extract all the possible topic types from several texts in English without using IDs. All the fields available in the output are shown:
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2024 © All Rights Reserved | Data protection policy | Terms and conditions | Data Processing Agreement MeaningCloud is a a trademark by MeaningCloud LLC