
Checking your results
We have mentioned three different tools we can use to understand the sentiment analysis results obtained from the APIs: polarity_term_list, tag_stack and the syntactic image output.
Polarity terms
The polarity_term_list shows the polarity terms that are taken into account to determine the polarity of a segment. In other words, they will show which entries from the sentiment model are being used to determine the sentiment of a text.
There are two significant fields in the polarity_term element: the text and the tag_stack:
The text contains an abreviated text that represents the entry/subentry definition. These are the abreviations used to describe subentries:
- entry:condition, the form/lemma of the entry WITH the context condition.
- entry:~condition, the form/lemma of the entry WITHOUT the context condition.
- entry<condition, the form/lemma of the entry AFTER the context condition.
- entry>condition, the form/lemma of the entry BEFORE the context condition.
- entry@X, the form/lemma of the entry with a morphological condition. The values of X will depend on the specific condition: N for NOUN, A for ADJECTIVE, V for VERB, Q for QUANTIFIER and E for ADVERB.
If the entry has aliases, they will appear concatenated to the form/lemma using pipes, "|". The same applies when there is more than one context condition.
Let's see some examples with entries from the example model we provide. If we analyze the sentence "The food was very good although there were no bathrooms.", we see the following output:

In this case there are two polarity terms, "good" from MeaningCloud's general model, and "bathroom<no" from the entry in the Restaurants model where we defined a subentry for bathroom when it goes after "no".
Did you notice...?
When an entry is affected by a modifier or a negator, it appears in the text field between parentheseses.
Important
The polarity terms include only terms with polarity. This implies that entries with polarity NONE will not appear even when they are being applied. The same thing happens when negators and modifiers in the cases when there's not anything with polarity in the text.
Tag stack
When the verbose parameter is enabled, an additional field is shown in the output: tag_stack. This field shows the polarity associated to a polarity term (an entry/subentry from the model), and how it's modified. To show this, tag_stack will contain the polarity associated to the term preceeded by the modifications it receives.
There's an example in the polarity terms shown before. The first term found in the sentence, "good" is modified by "very". We know that:
- "good" has a positive polarity, P
- "very" is a modifier with a value +
We see that in the text, as it is a modifier, "very" appears between parentheses. We can also see how in tag_stack the polarity P associated to "good" is preceeded by "+" the modifier value of "very". The result of this modification is the value that appears in score_tag, that is, P+.
Through this process you will be able to see what exactly is being taken into account for the sentiment analysis of a given text and to modify your sentiment model accordingly.
Did you notice...?
When an entry or a subentry is a multiword, the polarity information associated will be shown in its first word.
Syntactic image output
As a complementary feature, the Lemmatization, PoS and Parsing API provides an output in which the morhosyntactic tree is drawn. This is very helpful in order to identify how the text is being analyzed. When the request to the API includes a sentiment model, then the sentiment behavior of the different nodes of the tree will be shown through different colors.
In the following images you can see the syntactic tree obtained for the example sentence we used before.
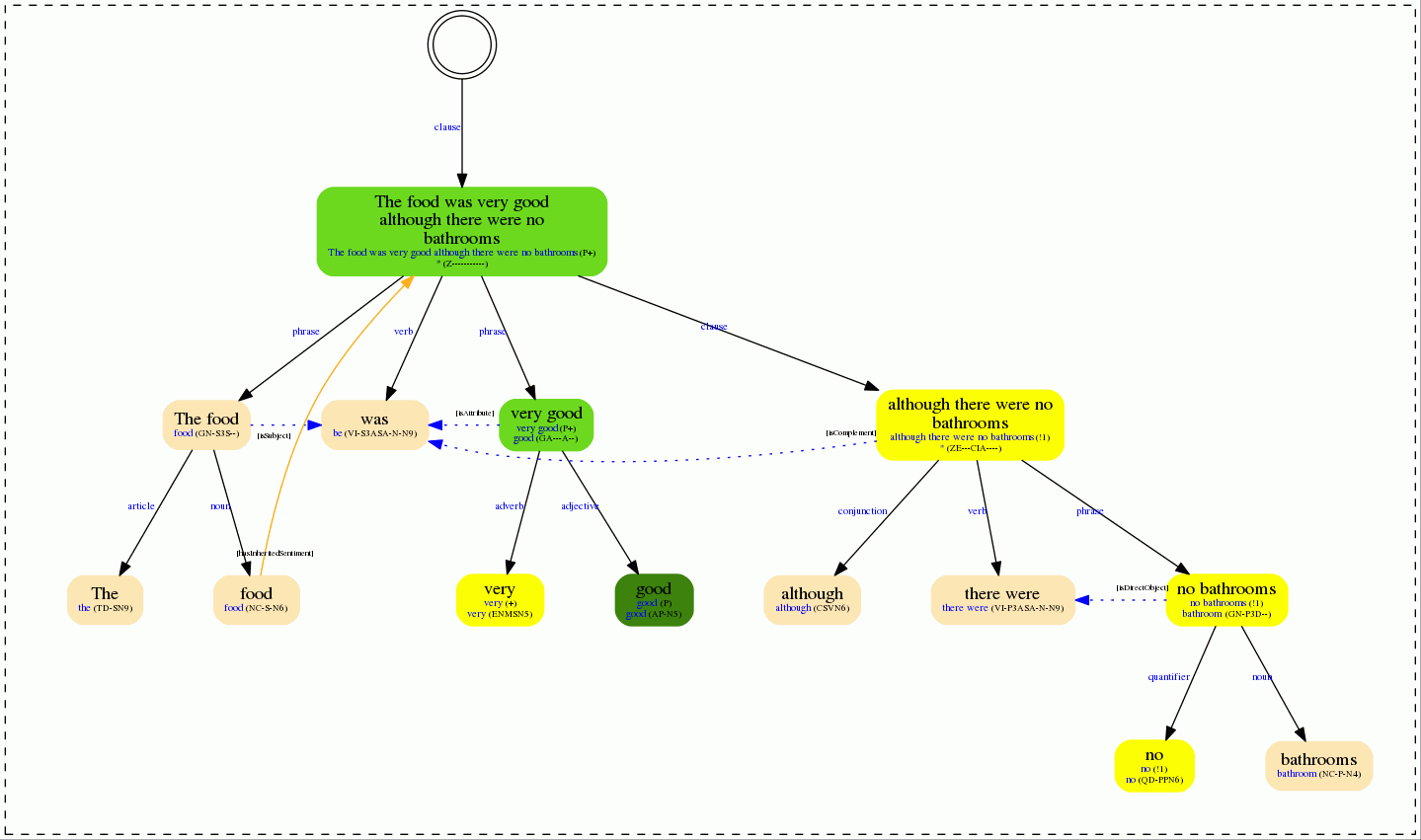
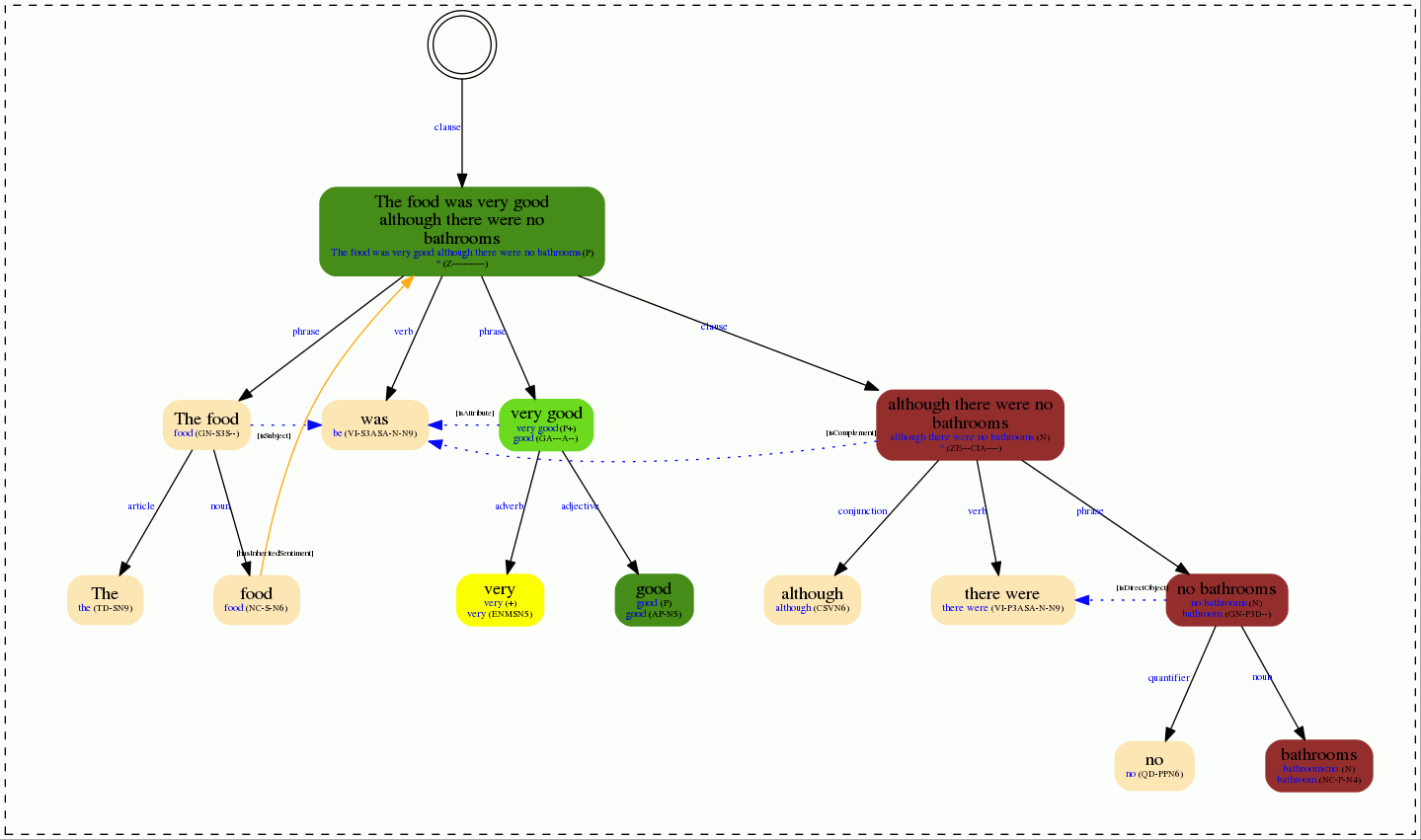
On the left you can see the results when the general sentiment model is used; on the right, you can see the same sentence, but using the example model provided.
The syntactic tree is specially useful to identify when the polarity changes. It allows you to see from a glance if the polarity has been correctly identified at a lower level, and how it evolves as it goes up the syntactic tree.
- Voice of the Customer in Retail: Beyond price 09/Jul/2019
- Tutorial: create your own deep categorization model 20/Jun/2019
- The leading role of NLP in Robotic Process Automation 11/Jun/2019
- Vertical packs: trial and subscription 09/Apr/2018

2024 © All Rights Reserved | Data protection policy | Terms and conditions | Data Processing Agreement MeaningCloud is a a trademark by MeaningCloud LLC