Gracias a todos por vuestro interés en nuestro webinar “Una nueva herramienta para resolver problemas complejos de categorización de texto” que celebramos el pasado 18 de junio y donde explicamos cómo utilizar nuestra herramienta de personalización de Categorización Profunda para resolver escenarios de clasificación de texto donde las tecnologías tradicionales de aprendizaje automático presentan limitaciones.
En la sesión cubrimos estos puntos:
- Desarrollando modelos de categorización en el mundo real
- Categorización basada en aprendizaje automático puro
- API de Categorización Profunda. Modelos predefinidos y packs verticales
- La nueva Herramienta de Personalización de Categorización Profunda. Lenguaje de reglas semánticas
- Caso real: desarrollo de un modelo de categorización
- Categorización Profunda – Clasificación de Texto. ¿Cuándo usar una u otra?
- Proceso ágil de desarrollo de modelos. Combinación con aprendizaje automático
IMPORTANTE: este artículo es un tutorial basado en la demostración que realizamos y que incluye los datos a analizar y los resultados del análisis.
¿Interesado? A continuación tienes la presentación y la grabación del webinar.
(This webinar was also delivered in English. Please find the recording here.)
Continuar leyendo
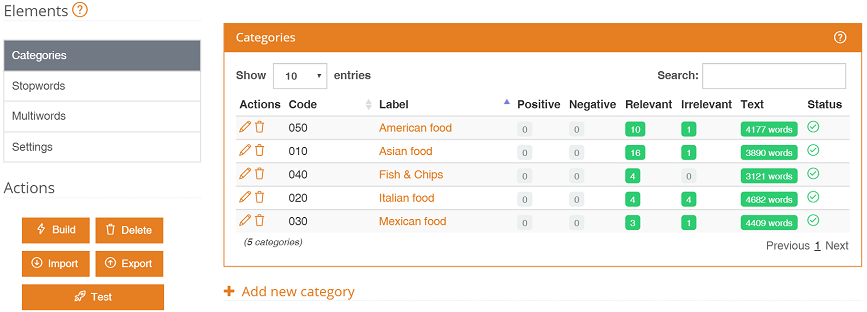


 La incorporación de recursos lingüísticos personales (modelos, diccionarios) permite a estas herramientas alcanzar altos niveles de precisión y cobertura, pero en general es un proceso caro, que exige un conocimiento profundo de estas tecnologías.
La incorporación de recursos lingüísticos personales (modelos, diccionarios) permite a estas herramientas alcanzar altos niveles de precisión y cobertura, pero en general es un proceso caro, que exige un conocimiento profundo de estas tecnologías.