La precisión en la analítica de texto crece a medida que sumamos recursos. Se incrementa igualmente el valor de lo que recogemos. Veamos cómo todo esto se parece a una de esas tartas de boda con varios niveles.

Comparte esta imagen en tu sitio
Alrededor del 80% de los datos está en forma de texto. Como todos queremos entender mejor tanto a los clientes como a los empleados, el texto es un factor clave para que cualquier organización pueda comprender los «porqués» y actuar sobre ellos.
En particular, el texto libre puede ser utilizado en la toma de decisiones. La actividad de extraer ideas de textos de forma manual es en el mejor de los casos, tediosas y caras, y en el peor, imposibles de realizar debido a los grandes volúmenes.
Para superar este desafío, las tecnologías de análisis de texto procesan y analizan automáticamente el contenido textual y proporcionan información valiosa, transformando estos datos «crudos» en información estructurada y manejable.
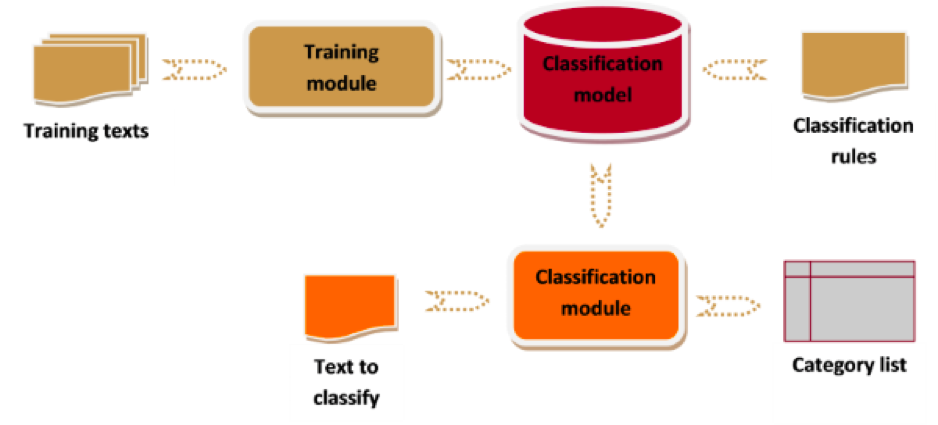
Text Analytics, un concepto aproximadamente equivalente a la minería de texto, se refiere a la extracción automática de información de alto valor desde el texto. Esta extracción suele implicar un proceso de estructuración del texto de entrada, el descubrimiento de patrones en el texto estructurado y, finalmente, la evaluación e interpretación de los resultados. Para lograrlo, se utilizan técnicas de aprendizaje automático, lingüística computacional, minería de datos y recuperación de información, lo que da a la minería de textos un fuerte carácter multidisciplinar.
El lenguaje natural es un territorio complicado. La ambigüedad, la ironía, los errores de ortografía y algunas trampas más lo hacen muy difícil de entender. Obtener descubrimientos valiosos a partir del lenguaje natural tampoco es una tarea fácil. La precisión y el valor en el análisis de texto crecen a medida que agregamos diferentes capas de recursos al procedimiento analítco. Vamos a ver por qué nos atrevemos a decir que todo esto se parece a uno de esos pasteles de boda con varios niveles.
1. Para empezar, los algoritmos de aprendizaje automático
Aprendizaje automático (machine learning) es el enfoque más comúnmente utilizado en el análisis de texto, y se basa en modelos estadísticos y matemáticos. Las técnicas más comunes incluyen el clustering con k-means, Bayes Naive y la clasificación con SVM. Deep Learning (AKA redes neuronales) se está utilizando últimamente con notable éxito.
2. Recursos lingüísticos: una necesidad
Si queremos agregar precisión al análisis, el conocimiento de un idioma y de su estructura es una necesidad. Hoy día es esencial aplicar reglas específicas del lenguaje para resolver problemas de ambigüedad, polisemia o ironía.
Actualmente, aunque los algoritmos se utilizan generalmente para el procesamiento del lenguaje natural (PLN), los recursos lingüísticos siguen siendo esenciales para aumentar la precisión de un modelo. Los algoritmos de aprendizaje automático pueden alcanzar el umbral del 60% -70% de precisión. A partir de ahí, es necesario recurrir a los recursos lingüísticos para resolver las dificultades que nos plantea el lenguaje natural.
Dado que los recursos lingüísticos como las gramáticas, las ontologías y las taxonomías son costosos, esta capa de lenguaje es mucho menos frecuentemente utilizada que la basadas en algoritmos. Ambas son de hecho complementarias y es posible utilizar ambas para añadir precisión.
3. Capas de personalización
Las herramientas de análisis de texto son extraordinariamente valiosas para extraer significado del contenido no estructurado, pero el uso de recursos lingüísticos genéricos limita su precisión.
Por ejemplo, un sistema automático nunca identificará los productos de una empresa si éstos no han entrado previamente en los diccionarios de la herramienta.
La inclusión de recursos lingüísticos específicos del dominio lingüístico aplicación (diccionarios o modelos) permite que estas herramientas alcancen altos niveles de precisión. Pero, en general, se trata de un proceso costoso que requiere una profunda competencia en estas tecnologías.
Hay dos capas adicionales de mejora relacionadas con la personalización:
- Lingüistas computacionales. Cuando los lingüistas expertos adaptan el software para crear una taxonomía específica de la empresa, estas herramientas se acercan a su efecto máximo
- Personalización del cliente para actualizar diccionarios y modelos a realidades que cambian en el tiempo.
4. Al final de la cadena: extractor de insights
Para obtener el máximo valor no deberíamos conformarnos con la detección de entidades y categorías generales. La analítica debería extraer patrones complejos y relaciones semánticas que agreguen valor.
Por ejemplo. Imaginemos que estamos en el campo de la inteligencia de mercado. Queremos detectar oportunidades de negocio para las organizaciones que buscan empresas que recientemente obtuvieron una inversión considerable en la ronda A o la ronda B. Etiquetar los textos y clasificar los documentos sería el primer paso. Necesario, pero no suficiente. Más allá de esa tarea básica, tenemos que descubrir las relaciones semánticas, para entender quién se financió, dónde, quién invirtió su dinero, a qué sector profesional pertenece la empresa financiada, cuánto dinero se invirtió y el propósito de la inversión. Todo ello se vuelve extremadamente valioso para encontrar y seleccionar las oportunidades adecuadas entre millones de potenciales oportunidades.
