Getting meaningful insights from natural language is no easy task. Text analytics value and accuracy grow as we add different layers of resources to the procedure. We explain how text analytics is like a multi-tiered wedding cake.

Share this Image On Your Site
Text Analytics Value
Around 80% of data is found in the form of text. Because we all want to better understand both customers and employees, text analysis is key to enabling any organization to figure out the whys and act upon them.
Having humans read and extract insights is tedious and expensive in the best-case scenario, but more often, it is simply impossible due to the large volume of content.
To overcome this challenge, text analytics technology automatically analyzes textual content and provides valuable insights, transforming this “raw” data into manageable, structured information.
Text Analytics, nearly the same as text mining, refers to the automatic extraction of high-value information from text. This extraction usually involves input text, discovering patterns in the structured text and, finally, evaluating and interpreting the results. Machine learning, computational linguistics, data mining, and information retrieval techniques are all used to carry out the process, giving text mining a strong, multidisciplinary character.
Natural language is anything but simple. Ambiguity, irony, misspellings, and more make it very difficult for a computer to process and understand. So, getting meaningful insights from natural language is even more challenging. Text analytics value and accuracy grow as we add different layers with complementary resources to the procedure. Below, we explain how we dare to compare text analytics to a multi-tiered wedding cake.
1. A solid base of Machine Learning algorithms
Machine Learning based on statistical and mathematical models is the most common approach used in text analysis. Common techniques include k-means clustering, Naive Bayes, and linear SVM classification. Deep Learning (AKA neural networks) is also being used lately with remarkable success.
2. Linguistic resources: a must
To add precision to the analysis, knowledge of a language and its structure is a must. It is essential to apply language-specific rules to solve problems of ambiguity, polysemy, or irony.
Currently, although algorithms are generally used for Natural Language Processing (NLP), linguistic resources are still critical for increasing a model’s accuracy. Machine learning algorithms can reach a threshold of 60 -70% accuracy. For higher accuracy, linguistic resources must be employed to solve the difficulties posed by natural language.
Because language resources such as grammars, ontologies, and taxonomies are costly to create and maintain, this layer of language is used far less frequently than ones based on algorithms alone. We use both, one on top of the other.Customization layers
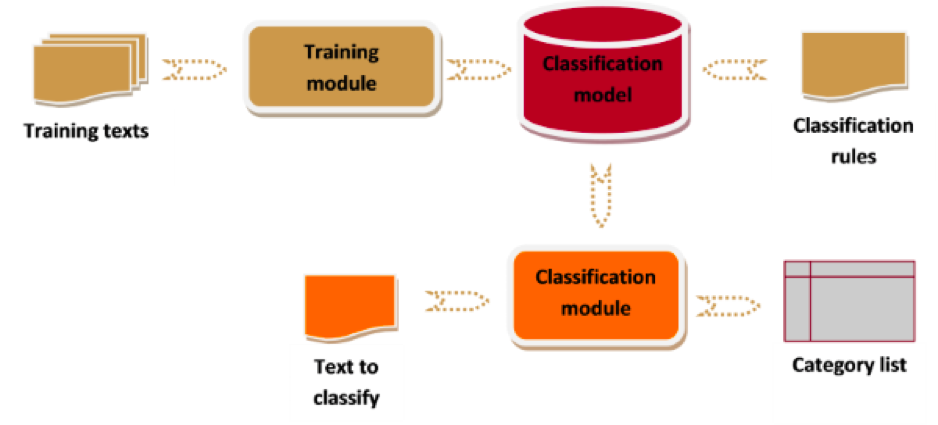
3. Customization layers
Text analytics tools are extraordinarily valuable for extracting meaning from unstructured content, but using generic linguistic resources limits their accuracy. For instance, an automatic system will never identify the names of a company’s products if they aren’t previously inputted into the tool’s dictionaries.
Including application-specific linguistic resources (dictionaries and models) allows these tools to reach high levels of precision and recall, but, in general, this is an expensive process that requires a deep proficiency in these technologies.
This customization has two layers to maximize precision::
- Computational linguists in which skilled linguists adapt the software to create a company-specific taxonomy
- Client-side customization so that clients can update dictionaries and models to realities that change over
4. On top. Insight Extractor.
Once the text has been structured, do not settle for detecting entities and defining general categories. Go further by extracting valuable insights found in complex patterns and semantic relationships.
Imagine that in the field of market intelligence we want to detect business opportunities for firms that look for companies that recently got a sizeable investment in round A or round B.
Tagging and classifying the texts was the first step. But beyond that necessary task, structuring semantic relationships such as who got funded, where, who invested the money, the professional sector of the funded firm, how much money was invested, and the purpose of the investment is exceedingly valuable for finding and selecting the right opportunities. By a deep semantic analysis, insight extractor is capable of assigning a business role (“founder,” “investor,” “money for round A”, …) to each entity, which allows extracting the maximum value for companies detecting opportunities.
