Los proyectos de análisis de texto muy a menudo utilizan fuentes públicas de Internet. Estos proyectos generalmente comienzan extrayendo datos de varios sitios web. Llamamos a este proceso «web scraping» (o «scraping», que significa «raspar»). Aunque una persona puede llevar a cabo este proceso de manera manual, el término «web scraping» a menudo se refiere a métodos automatizados ejecutados utilizando un rastreador web («web crawler»).
Como ejemplos de proyectos donde el proceso de web scraping añade una valiosa cantidad de información podemos mencionar los de experiencia del cliente (o también los de experiencia del paciente o la experiencia del empleado), la optimización dinámica de los precios, el monitoreo de la competencia o la verificación del cumplimiento normativo.
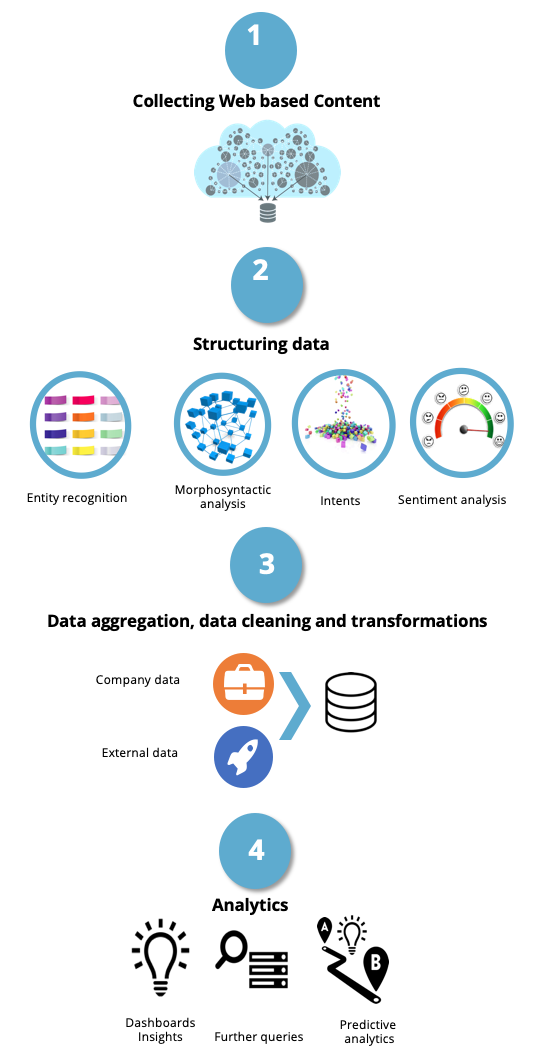
Un proyecto de analítica de texto normalmente consta de los siguientes procesos:
1) Recogemos información no-estructurada. Cuando trabajamos en el entorno web, utilizamos web scraping.
2) Convertimos las fuentes no-estructuradas en estructuradas y/o semi-estructuradas.
3) Combinamos los datos externos con los internos de la compañía.
Luego hacemos transformaciones a medida, que incluyen a menudo filtrado personalizado, coincidencia difusa, deduplicación en grandes conjuntos de datos, etc.
4) Aplicamos cualquiera de las técnicas estándar de análisis predictivo para extraer descubrimientos.
También utilizamos algoritmos basados en Inteligencia Artificial para predecir y optimizar los ingresos y márgenes, así como para expandir el descubrimiento de nuevas oportunidades de negocios.
Web scraping y rastreo de web
Web scraping es una forma de copia, en la que los datos se recopilan y copian de la web, generalmente para recogerlos en una base de datos local central, para su posterior recuperación o análisis.
El web scraping de una página web implica capturarla y extraer datos de ella. La captura es el equivalente a descargar una página. Los navegadores web descargan las páginas para poder mostrárnoslas. En consecuencia, el rastreo web es el ingrediente principal del web scraping: se trata de descargar páginas para su procesamiento posterior.
Una vez descargado, se puede hacer la extracción. El contenido de una página puede a partir de ahí transformarse, filtrarse o copiarse.
Web scraping es necesario
Las organizaciones deben reunir y estructurar grandes cantidades de contenido publicado en sitios web públicos.
El scraping se ha convertido en una de las herramientas más beneficiosas para las empresas que necesitan recopilar información competitiva de Internet. Debido al volumen de datos del que las empresas necesitan extraer información, no es razonable contratar a personas para hacer esta tarea tediosa de navegar por las páginas web.
Aquí es donde los servicios automatizados de rastreo de datos se vuelven valiosos.
El negocio de los servicios de scraping se basa fundamentalmente en el creciente mercado de inteligencia empresarial. Juega un papel importante en dar a las organizaciones una ventaja competitiva sobre sus competidores.
Puede proporcionar además conocimientos sobre las necesidades y demandas de los usuarios finales de manera eficiente, junto con información sobre las próximas tendencias del mercado.
Desde el scraping a la toma de decisiones para fijación de precios
Para tomar decisiones de precios acertadas y rentables, una empresa necesitaba tener acceso a fuentes de datos de alta calidad. El objetivo era proveer a sus equipos de inteligencia empresarial con los datos necesarios para tomar mejores decisiones.
A continuación del scraping viene la estructuración de datos con herramientas de procesamiento de lenguaje natural, principalmente para propósitos de desambiguación. Luego combinamos las fuentes públicas con los datos privados de la compañía. Posteriormente, realizamos transformaciones complejas, que incluyen filtrados personalizados, coincidencia difusa de nombres y deduplicación.
La inteligencia de precios de los competidores en tiempo real les ayuda a establecer precios óptimos y facilita una mejora sustancial de ingresos y márgenes. Asegura asimismo que siempre están un paso por delante de las estrategias de precios de sus competidores.
