Text analytics projects are often dependent on Internet-based public sources such as the World Wide Web. These projects usually begin by extracting data from a variety of websites. We call this process “web scraping” (or “web harvesting”). While users can handle web scraping manually, the term often refers to automated methods executed utilizing a web crawler.
Examples of projects that offer a valuable wealth of information include customer experience (in the same way as patient experience or employee experience), dynamic pricing and revenue optimization, competitor monitoring, or compliance checking.
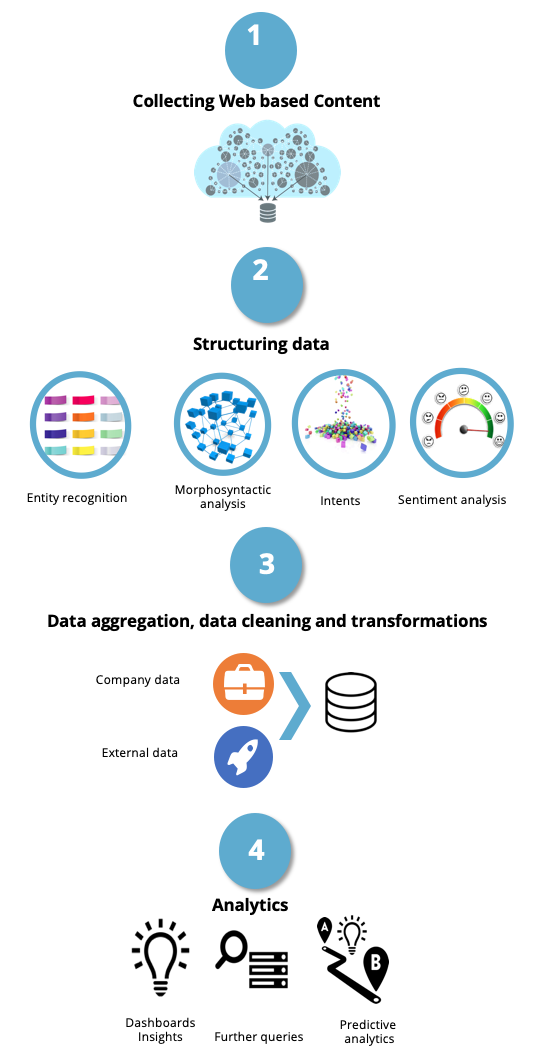
A text analytics project typically consists of four steps:
1) We gather unstructured information, which, when working on the WWW, is dealt using scraping.
2) We convert the raw source into a structured or semi-structured format.
3) We combine the data we gather with the company’s private data.
We then perform complex and custom transformations – including custom filtering, fuzzy product matching, and fuzzy de-duplication on large sets of data.
4) Subsequently, we apply any standard predictive analytics or data mining techniques to extract insights.
We also use Artificial Intelligence-based algorithms to predict and to optimize revenue and margins, as well as to expand the discovery of new business opportunities.
We have now a dedicated business exclusively focused on the health and pharmaceutical sectors
Konplik.Health begins operations with the health-related assets from MeaningCloud, including its leading natural language processing, deep semantic analysis, AI platform, and adaptations specific to the life sciences.
Web scraping and web crawling
Web scraping, put simply, is a form of copying, in which data is collected and copied from the web, typically into a central local database, for later retrieval or analysis.
Web scraping a page involves fetching it and extracting data from it. Fetching is the equivalent of downloading a page. A web browser downloads pages when you view them. Consequently, web crawling is considered the main ingredient of web scraping: it centers on downloading pages for later processing.
Once downloaded, then extraction can take place. The content and data of a page may be searched, transformed, copied and so on, as a part of this process.
Web scraping is a must
Organizations need to gather and structure vast amounts of content published and managed on public websites.
Scraping has become one of the most beneficial tools for companies that need to gather information from the Internet at a low-cost. Due to the volume of information at which businesses need to carry out scraping, it is not feasible to employ people to conduct this dull task of browsing through web pages.
This is where automated data crawling services become invaluable.
The market for web scraping services is fundamentally driven by the increasing market for business intelligence. It plays an important role in giving organizations a competitive advantage over its competitors.
It can provide knowledge on end-user needs and demands efficiently, along with intelligence on upcoming market trends.
From web scraping to decision making at pricing
To make profitable pricing decisions, a company needs to have access to timely, trustworthy sources of high-quality data. They need to empower their business intelligence teams with data which allows them to make better decisions.
Web scraping is followed by data structuring which uses Natural Language Processing tools mostly for disambiguation purposes. We, then, combine public sources with the company’s private data. Afterward, we perform complex and custom transformations – including custom filtering, insights, fuzzy product matching and fuzzy de-duplication on large sets of data.
Real-time competitor pricing intelligence helps companies to set optimal prices, facilitating their revenue and margin optimization; which in turn, ensures they are always one step ahead of their competitors’ pricing strategies.

One thought on “Web scraping and text analytics”
Great information. Web scraping, of course, is linked to data scraping, as the former refers to a technique of extracting data from websites in particular.