在MeaningCloud,我们的目标是以市场上最大的语言覆盖面,提供最先进的文本分析产品。因此在2019年结束之前,我们努力工作,推出了多项新的语言包,以扩大我们标准语言包(英语、西班牙语、法语、意大利语、葡萄牙语和加泰罗尼亚语)与北欧语言包(瑞典语、丹麦语、挪威语和芬兰语)的覆盖面。
我们推出的第一个语言包是中文语言包。中文,是中华人民共和国的官方语言。这种语言的母语者数量最多,占全球人口的近16%。
中文(包含其所有种类在内)是一类基于表意文字的语言,传统上是竖版排列,从上至下、自右向左逐列阅读。MeaningCloud所支持的中文种类是简体中文。
MeaningCloud目前对中文提供以下功能:

这一功能将根据市场需求在后续产品发布中进一步扩展。您可以在我们新上线的语言覆盖面网页上获取详细信息。
那么这些文本分析任务是什么,它们有何用处呢?
主题抽取是MeaningCloud的产品,用于“从非结构化和/或半结构化的机器可读文件中自动抽取结构化信息”[1]。换言之,主题抽取是从文本的集合中抽取特定信息,从人名到地段或钱款金额,无一不包。
涉及这项任务的方式有很多种,比如从其最受欢迎的子任务中可以产生命名实体识别。然而它们的目标都是相同的:从文本中抽取结构化信息。
这些图片展示了一个例子,展示这篇文章中的实体是怎样被探测出来的。
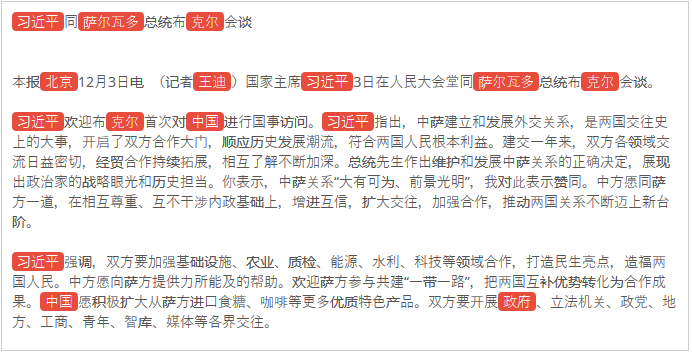
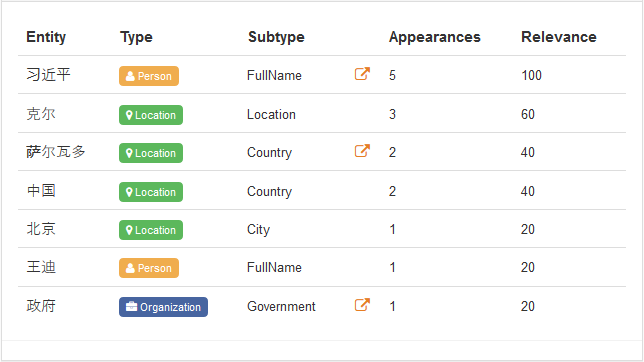
乍一看,这项任务看起来似乎只是找出文本中出现的任命,但还不仅是这样。要指代一个人有很多方式,他们的绰号或是别名都是需要考虑进去的。有时候识别出文本中的所有命名实体就已经绰绰有余了。对于这些情况,各实体都有一个相关的类型,因此可以选择只抽取地点、人、组织等等。您可以查看在我们的本体论体系中检测出的所有不同类型。
主题抽取有以下可应用场景:
- 对新闻文章或博客贴文的自动标签建议和语义出版
- 根据提及数据进行流行度分析
- 关键数据实体抽取
文本聚类能提供聚类分析,即“把一组对象聚在一起,使得同在一组中的对象(称为一个聚类)彼此之间的相似性(在某种意义上)强于与其他组中对象的相似性”[2]。
在这种情况下,所涉及的对象是文本,所提供的不同类型的分析能帮助我们发现其中的模式,以从视觉上对数据进行分类整理,或是了解与其相关的新信息并将其用作其他分析类型的反馈。文本聚类的一种可能用途是应用于我们正在使用文本分类进行分类的文本,从而识别出新的类别以添加至我们的模型。
在右侧,我们可以看到使用“文件分组”模式的结果,这一结果将于我们用来说明主题抽取的部分文本。
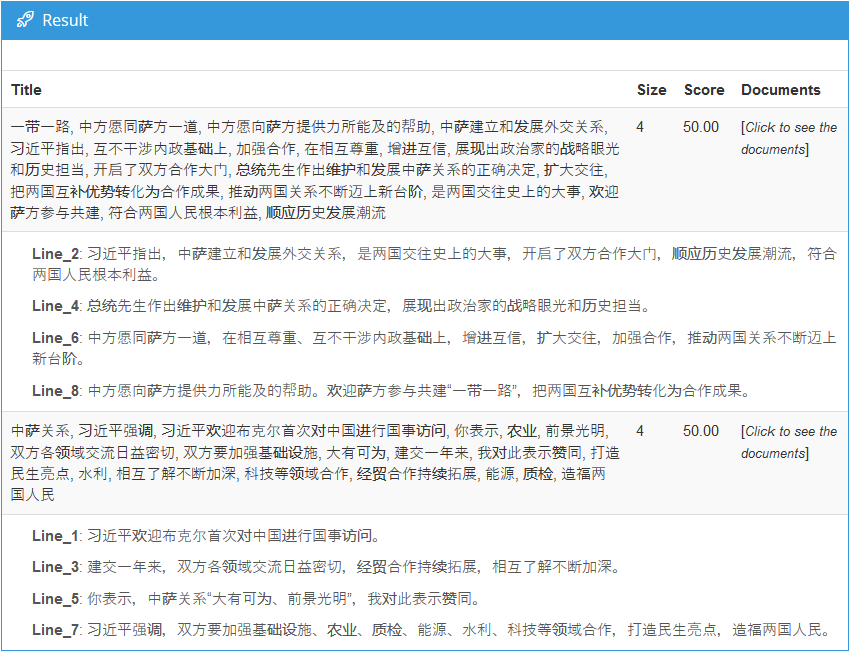
文本聚类通常的利用方式是用来发现文本集合中以前未知的信息或新趋势。
要测试中文中的所有功能,可通过以下两种方式:
如果您对此语言包升级至一年订阅,还可获得50%折扣!只需在升级过程中选择“中文年度订阅”套餐即可。优惠期只到2020年1月31日2020年2月29日!
如有任何问题,欢迎通过support@meaningcloud.com联系我们。
