At MeaningCloud we aim to provide the most advanced text analytics product with the broadest language coverage in the market. That’s why before we finish 2019 we have worked on launching several new language packs to increase the coverage given by our standard pack — English, Spanish, French, Italian, Portuguese and Catalan — and our Nordic pack — Swedish, Danish, Norwegian and Finnish.
The first pack we are launching is the Chinese pack. Chinese, the official language of the People’s Republic of China. It’s the language with the most native speakers, almost a 16% of the global population.
Chinese (in all its varieties) is a group of languages based on ideograms, traditionally arranged in vertical columns, read from top to bottom down a column and right to left across columns. The variety covered by MeaningCloud is simplified Chinese.
MeaningCloud now provides coverage for Chinese for the following functionality:
- Topics Extraction: covers the detection of entities and partially, expressions of time.
- Text Clustering: full coverage.

This coverage will be extended through the successive product releases depending on the market demand. Find detailed information on our new language coverage page.
So, what are these text analytics tasks and what are they used for?
Topics Extraction is MeaningCloud’s product for “automatically extracting structured information from unstructured and/or semi-structured machine-readable documents” [1]. In other words, Topics Extraction extracts specific pieces of information from collections of text, anything from names of people to locations or amounts of money.
There are a number of ways to refer to this task some, such as Named Entity Recognition are derived from its most popular subtasks. However, the objective is the same: extracting structured information from text.
In these images, you can see an example of the entities detected for this article.
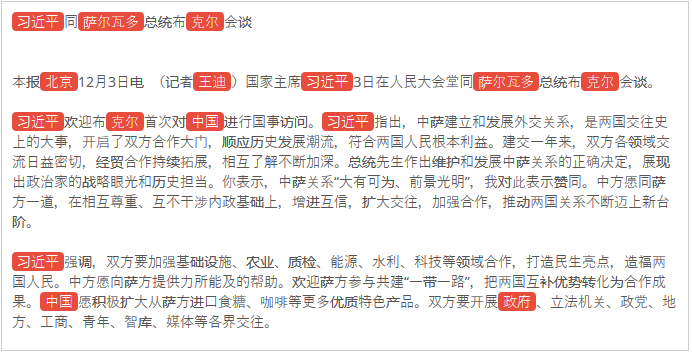
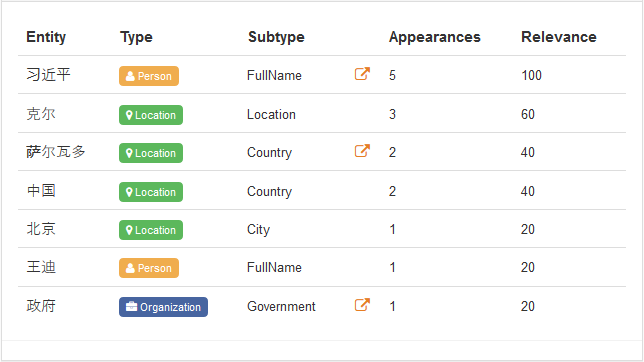
At first, it may seem that it’s just a matter of finding the names that appear in the text, but there’s a little more to it. There are many ways to refer to the same person, nicknames and variants of their name that you need to take into account. Sometimes, identifying all the named entities in a text is more than enough. For those instances, entities have a type associated, so you can choose to extract only locations, people, organizations, etc. You can check all the different types we detect in our ontology.
These are some scenarios in which Topics Extraction can be applied:
- Automatic tag suggestions for news articles or blog posts and semantic publishing
- Popularity analysis according to mentions
- Key data entity extraction
Text Clustering provides cluster analysis, the task of “grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters)” [2].
In this case, the objects in question are texts, and the different types of analysis provided can help us discover patterns in them, either to visually sort the data or to learn new information about it and use it as feedback for other types of analysis. A possible use of Text Clustering is to apply it over the texts we are classifying using Text Classification in order to identify new categories to add to our model.
On the right, we can see the result using the “document grouping” mode that we would obtain for some of the text we used to illustrate Topics Extraction.
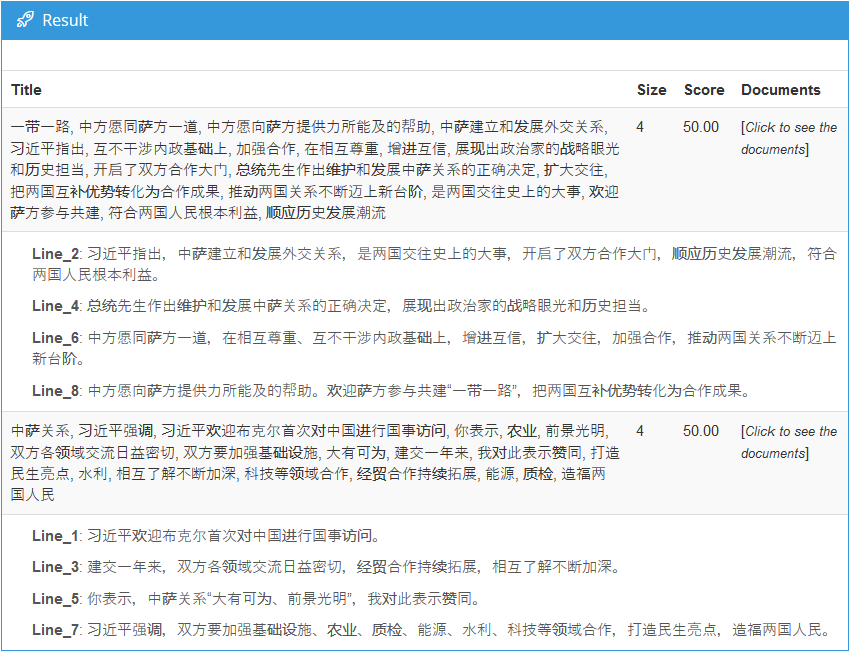
Text Clustering is generally used as a way to discover previously unknown information or new trends in text collections.
There are two possible ways to test all the functionality in Chinese:
- Requesting the 30 day free trial period that we offer for all our packs.
- Subscribing to the pack you are interested in.
And if you upgrade to this pack for a year, you get 50% off!. Just select the “Chinese Annual” pack in the upgrade process and you are set. Only available until January 31 February 29, 2020!
For any questions, we are available at support@meaningcloud.com.
