En raison de l’essor des technologies de traitement automatique du langage naturel, l’analyse de texte est sur toutes les lèvres. Cependant, la plupart des services dans ce domaine sont fournis en anglais et, en fonction de la langue qui vous intéresse, il est parfois difficile de trouver les fonctionnalités que vous recherchez.
Ne vous inquiétez pas, nous sommes là pour vous aider. Par exemple, le français est une langue utilisée sur les cinq continents avec plus de 300 millions de locuteurs, mais c’est également la première ou la deuxième langue de communication de nombreuses organisations internationales [1]. Ce n’est donc pas un hasard si elle figure dans notre Pack standard de langues !

Si le concept « d’analyse automatique de texte » vous semble plutôt flou ou si vous recherchez un élément plus spécifiquement lié à la langue, ce billet vous est destiné. Nous tenons compte de la diversité des langues et nous voulons vous présenter toutes les fonctionnalités que nous fournissons en français.
L’analyse de texte consiste à extraire des informations utiles à partir de textes ou à les classer de façon efficace selon vos objectifs. Dans cette optique, nous offrons avec MeaningCloud une couverture complète de l’analyse de texte de plusieurs capacités clés : reconnaissance d’entités nommée, analyse de sentiment, classification et catégorisation des textes, clustering de textes, identification de la langue, lemmatisation, étiquetage morphosyntaxique et analyse syntaxique, résumé automatique, analyse de la structure du document, réputation des entreprises et catégorisation approfondie. Nous vous expliquons aujourd’hui ce à quoi correspondent ces concepts, ce qu’ils peuvent faire pour vous et aussi comment vous pouvez profiter pleinement de leur potentiel.
Reconnaissance d’entités nommées
Nous allons commencer avec la reconnaissance d’entités nommées. Dans un texte donné, cette fonctionnalité extrait des instances spécifiques qui entrent dans l’une de ces catégories prédéfinies :
- Entités : les gens, les organisations, les lieux, etc. ;
- mots-clés : concepts significatifs ;
- expressions temporelles comme « le 3 octobre 2018 » ;
- expressions monétaires comme « 48 € » ;
- expressions de quantité comme « 9 chiens » ;
- d’autres expressions : des schémas alphanumériques, comme les ID, les numéros de téléphone, etc.
Il s’agit d’une solution puissante et très utile si vous souhaitez identifier les mots-clés à différents niveaux. Pour voir comment cela fonctionne plus en détail, nous allons prendre ce texte en exemple :
Le prix Nobel de physique a été attribué à Arthur Ashkin, Gérard Mourou et Donna Strickland
Ce mardi 2 octobre, le prix Nobel de physique a été attribué pour moitié à l’Américain Arthur Ashkin (96 ans), et pour l’autre moitié au Français Gérard Mourou (74 ans) et à la Canadienne Donna Strickland (59 ans). Cette dernière est la troisième femme au monde à recevoir le prix Nobel de physique (après Marie Curie en 1903 et Maria Goeppert-Mayer en 1963). Ils recevront ainsi chacun un peu plus de 200.000 euros.
Leurs recherches sur les lasers ont permis de développer des outils utilisés dans l’industrie et la médecine. Ces découvertes ont «révolutionné les la physique des lasers» et la conception «d’instruments de précision avancée qui ouvrent des champs inexplorés de recherche et une multitude d’applications industrielles et médicales», a indiqué l’Académie royale des sciences à Stockholm.
Ils succèdent à Rainer Weiss, Barry Barish et Kip Thorne, trois astrophysiciens américains qui avaient reçu le prix Nobel de physique en 2017, pour leurs recherches sur l’observation des ondes gravitationnelles, ouvrant une nouvelle fenêtre sur la connaissance de l’univers.
Nous allons voir comment la fonctionnalité de reconnaissance d’entités nommées fonctionne :

Comme indiqué précédemment, non seulement cette solution reconnaît les entités, mais aussi les dates, les quantités, les expressions monétaires. En outre, la reconnaissance d’entités nommées assure une désambiguïsation des entités et relie ses résultats à Wikipédia, une source de savoir externe. Ainsi, comme Wikipédia contient des identificateurs uniques qui correspondent à des entités du monde réel, nous avons accès à un plus grand nombre d’informations relatives à notre texte.
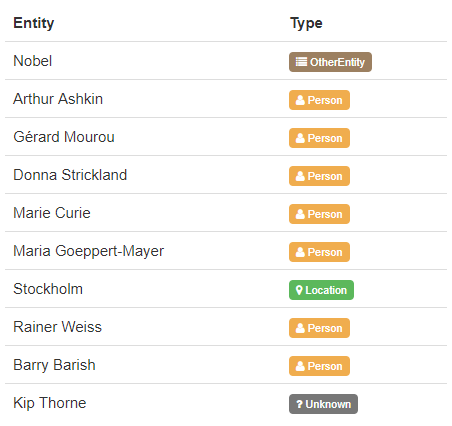
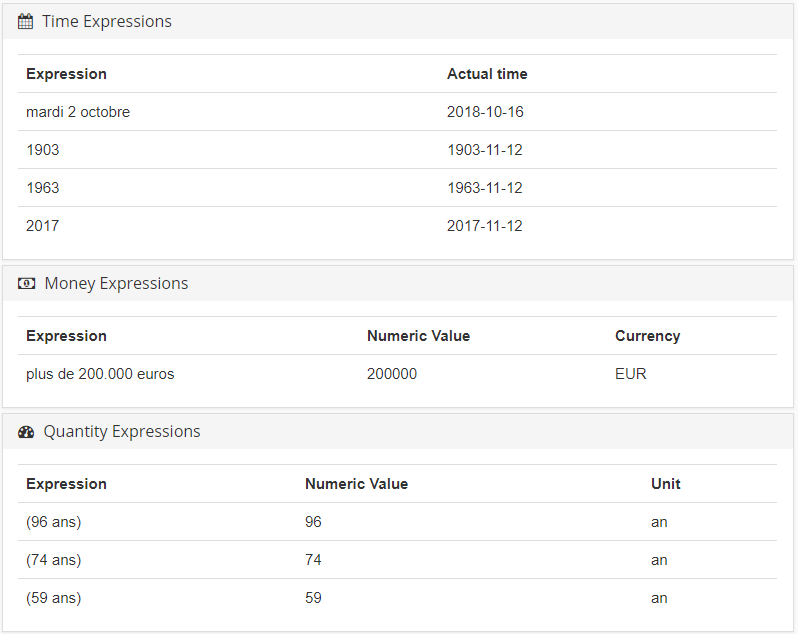
Concernant la reconnaissance d’entités nommées, un type d’extraction est associé à des entités individuelles telles que l’emplacement, l’organisation ou un produit, etc., pour sélectionner celles qui vous intéressent. Pour cela, nous nous appuyons sur une riche et prolifique ontologie qui est la nôtre.
Enfin, pour tirer pleinement parti de l’extraction des entités nommées, nous proposons un outil de personnalisation qui vous permet de créer des dictionnaires de l’utilisateur. Ces dictionnaires vous permettent d’adapter son potentiel dans votre domaine avec votre propre ontologie. La même puissance avec des résultats plus affinés.
Classification et catégorisation des textes
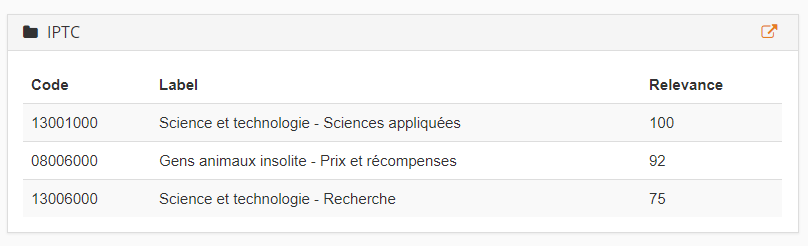
Si vous recherchez plutôt un produit qui permette de classer un document dans une ou plusieurs catégories, l’outil de classification et de catégorisation des textes de MeaningCloud est la solution parfaite qu’il vous faut. Cet outil fonctionne avec plusieurs modèles génériques de catégories prédéfinies, ou comme nous les appelons, des modèles de classification.
Deux de ces modèles sont les normes IAB (un ensemble standard de catégories de l’industrie de la publicité) et IPTC (une norme internationale pour classer les actualités).
Cette solution est le moyen le plus rapide de saisir de quoi parle un texte. La longueur du texte utilisé dans cet outil varie, allant d’un simple tweet à l’ensemble d’un article d’actualité.
En fonction de l’exemple français cité précédemment, le modèle IPTC a classé le texte comme parlant des « Sciences appliquées », des « Prix et récompenses », de la « Recherche » et de la « Physique », termes qui correspondent bien aux thèmes.
Tout comme avec l’extraction d’entités nommées, la classification et la catégorisation de textes offre la possibilité de définir votre propre modèle de classification à l’aide de notre moteur de personnalisation. Nous avons également un tutoriel montrant comment créer un modèle personnalisé dans Excel.
Analyse de sentiment
L’analyse de sentiment extrait les sentiments et exécute la tâche d’opinion mining (fouille d’opinions). Sa fonction est d’extraire les informations subjectives et également la polarité dans n’importe quel texte donné, soit au niveau du document, soit en se focalisant sur un aspect. Chez MeaningCloud, nous prenons les nuances de sentiments en considération et nous couvrons jusqu’à 6 niveaux de polarité : fortement négatif, négatif, neutre, positif, fortement positif et absence de sentiment.
Associant l’analyse morphosyntaxique et l’analyse de sentiment, notre solution d’analyse de sentiment assure l’identification des sentiments et des opinions non seulement au niveau global, mais aussi au niveau de la phrase, en analysant chaque phrase individuellement pour acquérir une compréhension plus profonde de la polarité du texte.
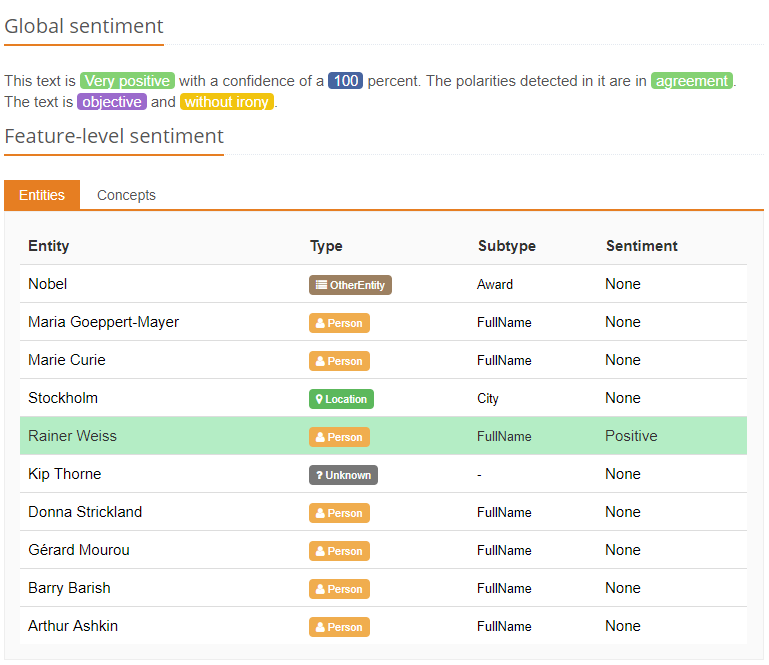
Tout comme les deux premiers produits, l’analyse de sentiment peut être personnalisée grâce à notre moteur de personnalisation, aussi bien pour les sentiments associés aux termes, que pour les entités et les concepts à analyser au niveau de chaque aspect.
Si vous voulez consulter un scénario d’application de cette fonctionnalité, consultez notre tutoriel sur la façon d’adapter l’analyse de sentiment à votre propre domaine.
Le clustering de textes
Le clustering de textes permet de réunir des groupes de textes dénommés clusters (partitions) qui sont plus ressemblants les uns par rapport aux autres que par rapport à ceux des autres groupes. En d’autres termes, la solution de clustering de textes de MeaningCloud porte sur le clustering automatique des documents. Ce type d’analyse nous permet de découvrir des schémas par le biais d’éléments communs, c’est-à-dire des similarités présentes dans tous les textes analysés.
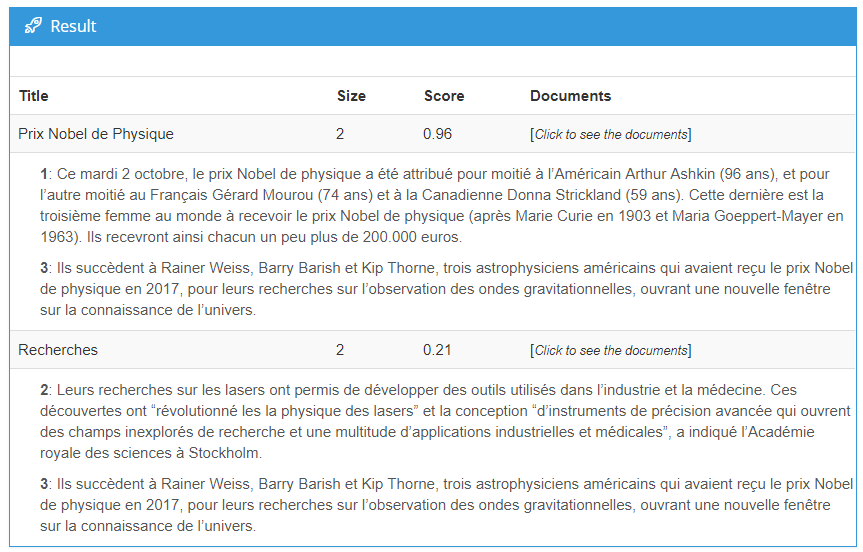
Nous pouvons voir que les paragraphes 1 et 3 ont la recherche comme thème commun alors que les paragraphes 2 et 3 ont le Prix Nobel comme le point de convergence.
En plus de regrouper des textes similaires, le clustering de textes peut aussi être utilisé afin de rechercher les tendances significatives parmi des textes apparemment sans rapport.
L’identification de la langue
MeaningCloud propose également un service très utile dans un monde de plus en plus globalisé : l’identification de la langue. Il détecte la langue dans laquelle un texte est écrit parmi 160 langues. Bien que cette tâche soit perçue comme moins significative, son importance est cruciale dans les scénarios multilingues auxquels nous faisons face tous les jours, où il est essentiel de connaître la langue que nous allons utiliser dans tous les autres processus de linguistique informatique.

Lemmatisation, étiquetage morphosyntaxique et analyse syntaxique
La solution MeaningCloud est ce qu’il vous faut en matière d’analyse morphosyntaxique, de lemmatisation, d’étiquetage morphosyntaxique (part-of-speech tagging) et d’analyse syntaxique. Elle se décompose en trois opérations :
- La lemmatisation est une tâche dans laquelle toutes les formes fléchies d’un mot sont ramenées à une forme neutre (c’est-à-dire leur lemme), afin d’analyser l’ensemble des formes comme une seule unité.
- L’étiquetage morphosyntaxique est le processus de marquage de chaque mot du texte avec sa catégorie grammaticale correspondante. Ces étiquettes (tags) sont très pratiques pour créer des schémas de reconnaissance fixe.
- L’analyse syntaxique analyse tous les éléments d’une phrase et les fonctions qu’ils remplissent.
Ici, nous pouvons voir un exemple indiquant comment se déroule cette analyse morphosyntaxique dans l’API de lemmatisation, d’étiquetage morphosyntaxique et d’analyse syntaxique :
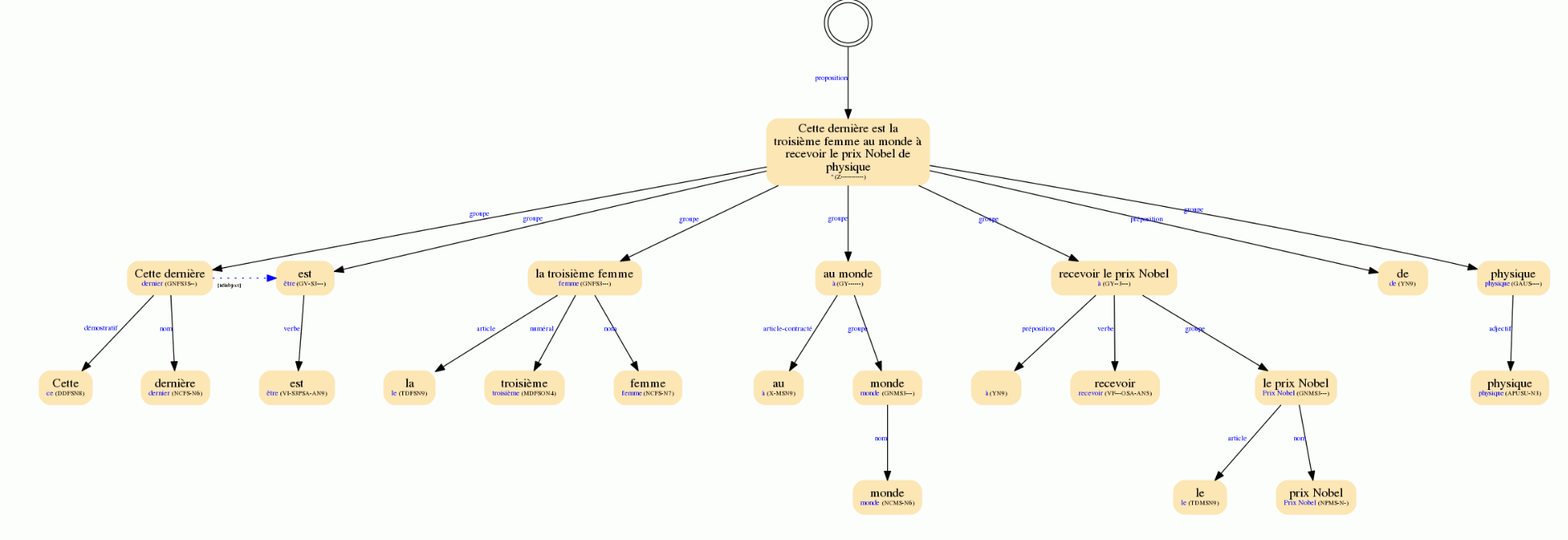
Ce produit MeaningCloud unique fournit des données morphologiques, syntaxiques et sémantiques à la fois. Cela vous permet de combiner une énorme quantité d’informations et de détecter les schémas qui correspondent à votre cas d’utilisation spécifique.
Par exemple, si vous souhaitez détecter les entreprises qui investissent de l’argent dans d’autres sociétés, vous pouvez combiner la détection de l’entité et celle de l’argent pour trouver les entreprises et les sommes d’argent. Les données morphologiques permettent de réduire les résultats aux cas où le texte indique que l’argent a été investi et les données syntaxiques étudient qui a effectué l’investissement et qui a reçu des fonds. C’est une solution très polyvalente pour ceux qui souhaitent une recherche approfondie.
Résumé automatique
Le résumé automatique fournit des instruments utiles afin de saisir l’essentiel d’un document. Le résumé automatique sélectionne les phrases les plus pertinentes d’un texte donné et en résume le sujet. Sa force réside dans son indépendance vis-à-vis de la langue, de sorte qu’il fonctionne avec des documents dans n’importe quelle langue.
Notre fonctionnalité de résumé vous permet de sélectionner en combien de phrases vous souhaitez résumer votre document. Ce texte d’exemple réduit à une seule phrase donnerait cela :

Analyse de la structure du document
De même que pour l’extraction d’entités nommée, qui extrait des éléments spécifiques d’information, l’analyse de la structure du document identifie et extrait les différentes sections d’un document donné avec le contenu du balisage (comme dans les PDF, les fichiers Microsoft Word ou les pages Wikipédia). La fonctionnalité MeaningCloud d’analyse de la structure du document cible les titres, les en-têtes, les résumés et les e-mails.
Les tâches ciblant l’extraction d’informations détaillées tirées de documents officiels standards (tels que les rapports financiers ou les appels d’offres publics) gagnent de plus en plus en notoriété. Ces documents sont publiés périodiquement et contiennent des informations importantes que vous voudriez peut-être extraire.
Ce sont en général des documents volumineux, la connaissance de leur structure peut donc vous aider à consulter la section qui vous intéresse sans avoir à passer par l’ensemble du document.
Autres produits
MeaningCloud va plus loin et fournit deux services rares d’analyse de texte. La réputation de l’entreprise et la catégorisation approfondie. Le premier est disponible en espagnol et le second est disponible en espagnol et en anglais actuellement. Dites-nous si vous souhaitez que ces fonctionnalités soient disponibles en français dans un avenir proche.
La réputation de l’entreprise
La réputation de l’entreprise vise à analyser les sentiments et les opinions associés aux organisations mentionnées dans un texte selon les différentes catégories définies dans un modèle de réputation. Ce modèle de réputation prend en compte plusieurs dimensions de la réputation ou des variables telles que l’innovation, la responsabilité sociale, etc.
Ce service complexe allie les fonctionnalités de trois de nos produits en un seul : la reconnaissance d’entités nommées, l’analyse de sentiments et la classification et la catégorisation de textes. Vous pouvez en apprendre plus sur ses processus sous-jacents ici.
Deep Categorization (catégorisation approfondie)
La catégorisation approfondie affecte une ou plusieurs catégories à un texte, à l’aide d’un ensemble détaillé et complet de règles. Elle vous permet d’identifier des scénarios très spécifiques à l’aide d’une combinaison de caractéristiques morphologiques, sémantiques et de règles de texte. La catégorisation approfondie se distingue de la classification et de la catégorisation des textes en matière de performances et de précision. Alors que cette dernière fonctionne avec peu de taxonomies dépendantes de la langue et une grande composante statistique, ce qui conduit à d’excellents résultats en matière de performance pour les grandes taxonomies, la première utilise des critères linguistiques détaillés comme éléments clés, ainsi que notre analyse morphosyntaxique. L’API de catégorisation approfondie est le fondement de nos packs verticaux, qui comportent la voix du client et la voix de l’employé. Ces deux cas concernent des textes écrits soit par les clients soit par les employés qui font part de plusieurs problèmes liés à l’entreprise. En outre, nous offrons ce service pour différents secteurs : le commerce de détail, les services bancaires, les télécommunications, le secteur de la restauration, etc. Chacun d’entre eux est hautement spécialisé en raison des règles détaillées concernant chaque secteur.
Une autre différence entre la catégorisation approfondie et la classification et la catégorisation des documents réside dans le fait que cette dernière travaille avec le modèle de classification IAB 1.0 alors que la catégorisation approfondie fonctionne avec sa version 2.0, ce qui donne des résultats plus précis.
Tous ces services sont accessibles via nos API ou en utilisant l’une de nos intégrations pratiques, dont notre addin portable pour Excel, notre ingénieuse App pour Zapier ou notre tout nouveau add-on pour Google Sheets. Pour toute question, n’hésitez pas à nous écrire ! Nous serons heureux de pouvoir vous aider.
