Algumas semanas atrás falamos sobre o desempenho da análise de texto do MeaningCloud em textos franceses. Chegou a hora do português!
O Português, junto com o espanhol, tem uma presença enorme na América do Sul. É falado por mais de 200 milhões de pessoas apenas no Brasil. Não só tem uma influência imensa na economia na América do Sul, mas também na Europa, onde é usado por mais de 10 milhões de pessoas. A África também tem nativos do português. A Angola, que tem uma população de mais de 24 milhões de pessoas, reconhece o português como seu idioma oficial. A sua presença nesses três continentes o torna difícil de esquecer no nosso pacote de idiomas padrão. No MeaningCloud, oferecemos duas variantes de português: Português do Brasil e da Europa.

Se o conceito de “análise de texto” parece um pouco vago ou se você está procurando por algo mais especificamente relacionado à linguagem, este post é ideal para você. Mantemos uma diversidade de idiomas e queremos mostrar todas as funcionalidades que fornecemos em português.
A ferramenta de análise de textos extrai informações úteis de textos ou os classifica em formas eficazes para suas finalidades. Com isto em mente, no MeaningCloud oferecemos cobertura completa de várias funcionalidades-chave de análise de texto: Extração de tópicos, análise de sentimentos, classificação de texto, agrupamento de texto, identificação de idioma, lematização, PoS e parsing, compactação, análise da estrutura do documento, reputação empresarial e categorização profunda. Hoje, estamos explicando cada um deles, o que eles podem fazer por você e como você pode beneficiar-se integralmente do potencial deles.
Extração de tópicos
Começaremos com a extração de tópicos. Dado um texto, essa funcionalidade extrai casos específicos que pertencem a uma dessas categorias pré-definidas:
- Entidades: pessoas, organizações, lugares, etc.
- Conceitos: palavras-chave importantes
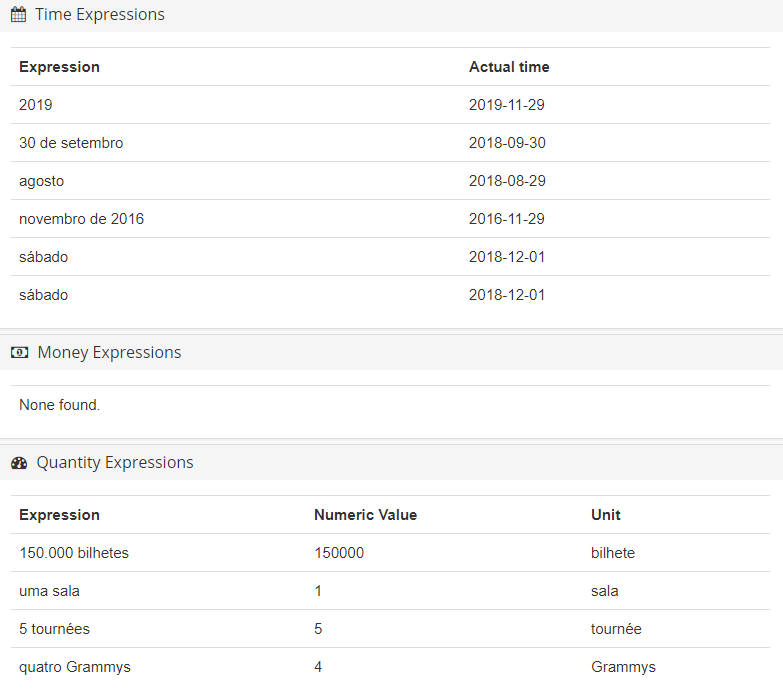
- Expressões temporais como “em 3 de outubro de 2018”
- Expressões monetárias como “48€”
- Expressões de quantidade como “9 cães”
- Outras expressões: padrões alfanuméricos como documentos de identidade, números de telefone, etc.
Esta é uma solução muito útil e poderosa se você procura identificar palavras-chave em diferentes esferas. Para ver um funcionamento mais profundo, vamos utilizar este texto como exemplo:
Michael Bublé vai cantar em Portugal em 2019
O concerto será na Altice Arena, em Lisboa, no dia 30 de setembro. O cantor regressou aos palcos em agosto, depois de um período de afastamento, com espetáculos em Dublin, Londres e Sidney para os quais foram vendidos mais de 150.000 bilhetes.
O cantor canadiano afastou-se dos palcos em novembro de 2016, quando soube do cancro do filho, tendo depois anunciado que iria lançar um álbum, “Love”, que será lançado no próximo sábado. No entanto, numa entrevista à revista US Weekly, o agente do cantor desmentiu a reforma do cantor e disse que Bublé não tem planos de se retirar.
Bublé volta assim à Altice Arena onde já atuou cinco vezes para uma sala esgotada. Os bilhetes serão colocados à venda no próximo sábado. O cantor já completou 5 tournées mundiais, ganhou quatro Grammys e vendeu mais de 60 milhões de álbuns.
Vamos ver como o recurso de extração de tópicos funciona:

Como já dito, essa solução reconhece entidades, datas, quantidades e expressões monetárias. Além disso, a extração de tópicos fornece desambiguação da entidade e vincula seus resultados à Wikipédia, uma fonte de conhecimento externa. Dessa forma, já que a Wikipédia contém identificadores únicos que correspondem a entidades reais, temos acesso a uma maior quantidade de informações relacionadas ao nosso texto.
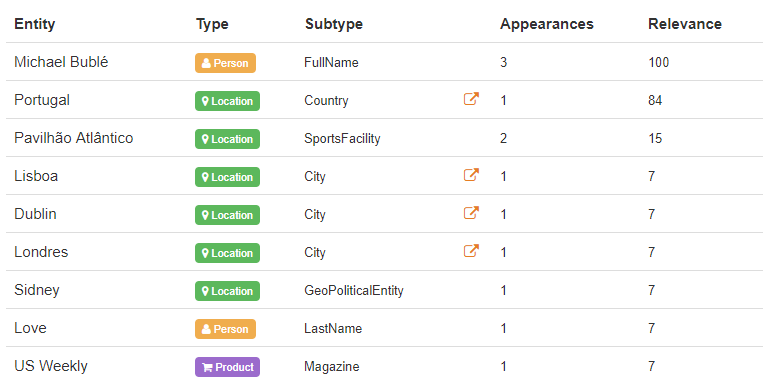
Em relação à extração de entidades, uma modalidade é associada a entidades individuais, como local, organização ou produto, etc., para facilitar a seleção daqueles de seu interesse. Para isso, dependemos de uma ontologia abundante e prolífera.
Por último, para aproveitar ao máximo a extração de tópicos, oferecemos uma ferramenta de personalização que permite que você crie dicionários do usuário. Esses dicionários permitem que você acomode o potencial da ferramenta ao seu domínio com sua própria ontologia. Mesma potência, resultados mais detalhados.
Text Classification
Se busca um produto que classifique um documento em uma ou mais categorias, a classificação de texto do MeaningCloud é a solução perfeita para você. Esta ferramenta funciona com vários modelos genéricos de categorias pré-definidas, os chamados modelos de classificação. Dois desses modelos são IAB (um conjunto padrão de categorias da indústria publicitária) e IPTC (um padrão internacional para classificar notícias).

Essa solução é o jeito mais rápido de compreender o assunto do texto. O comprimento do texto que pode ser usado por essa ferramenta varia de um tweet simples a um artigo completo.
De acordo com o exemplo em português supramencionado, o modelo IPTC rotulou o texto como “Arte, cultura e espetáculos”, que encaixa-se perfeitamente no tema.
Assim como a extração de tópicos, a classificação de texto oferece a possibilidade de definir seu próprio modelo de classificação usando o nosso mecanismo de personalização. Também temos um tutorial sobe como criar um modelo personalizado no Excel.
Análise de sentimentos
A análise de sentimentos extrai o sentimento e executa a mineração das opiniões. Sua função é extrair as informações subjetivas, além da polaridade, em qualquer texto, seja a nível global ou baseado em aspectos. No MeaningCloud, levamos as nuances de sentimentos em consideração e cobrimos 6 níveis de polaridade: Muito negativo, negativo, neutro, positivo, muito positivo e sem sentimento.
Ao combinar a análise morfossintática e a informação de sentimento, nossa solução de análise de sentimentos permite a identificação de sentimentos e opiniões, não apenas a nível global, mas também no nível da frase, analisando cada frase individualmente para conseguir um melhor entendimento da polaridade do texto.
Assim como nos dois últimos produtos, a análise de sentimentos pode ser personalizada através do nosso mecanismo de personalização, tanto o sentimento associado aos termos, quanto as entidades e conceitos a serem analisados a um nível de aspecto.
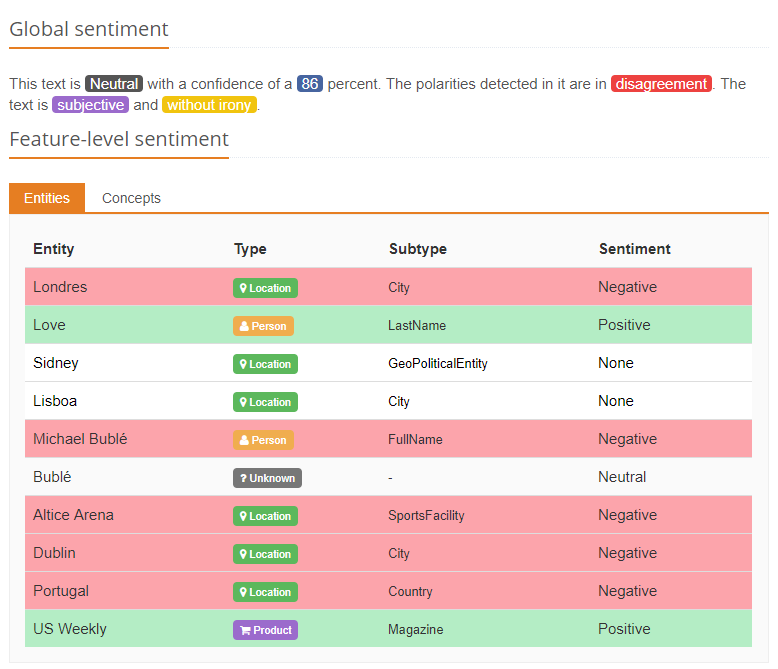
Se quiser conferir um cenário onde aplicamos isso, consulte nosso tutorial sobre como adaptar a análise de sentimentos ao seu próprio domínio.
Agrupamento de texto
O agrupamento de texto ajuda a reunir grupos de textos, chamados de agrupamentos, que são mais semelhantes entre si do que aqueles em outros grupos. Ou seja, o agrupamento de texto é uma solução do MeaningCloud para o agrupamento automático de documentos. Esse tipo de análise nos ajuda a descobrir padrões por meio de elementos comuns, ou seja, semelhanças, presentes em todos os textos analisados.
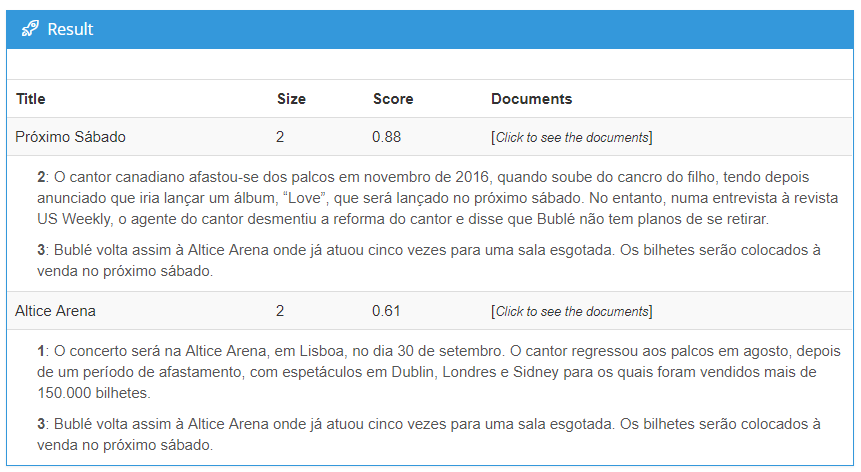
Podemos ver que o “próximo sábado” é uma semelhança entre os parágrafos dois e três, enquanto os parágrafos um e três têm a Altice Arena como um elemento convergente.
Além de agrupar textos semelhantes, o agrupamento de textos também pode ser utilizado para descobrir padrões significativos entre textos aparentemente distintos.
Identificação do idioma
O MeaningCloud também oferece um serviço muito útil em um mundo cada vez mais globalizado: Identificação do idioma. Detecta o idioma no qual o texto é escrito dentre 160 idiomas. Embora essa tarefa seja considerada menos relevante, sua importância se dá pelos cenários multilíngües que enfrentamos diariamente, nos quais é crucial saber o idioma no qual vamos operar todos os demais processos lingüísticos computacionais.

Lematização, PoS e parsing
Quando se trata de análise morfossintática, lematização, PoS (Part of Speech – categoria gramatical) e parsing é a solução ideal do MeaningCloud. Resume-se a estas operações:
- Lematização é a tarefa na qual todas as formas flexionadas de uma palavra se reúnem em uma forma neutra (ou seja, seu lema), para analisar todas elas como uma única unidade.
- PoS tagging é o processo de marcar cada palavra do texto com sua categoria gramatical correspondente. Essas tags/marcações são úteis ao criar padrões fixos de reconhecimento.
- Parsing, também chamada de análise sintática, é a análise de cada elemento de uma frase e as funções que eles preenchem.
Aqui podemos ver um exemplo de como ser parece uma análise sintática completa na nossa API de lematização, PoS e parsing:
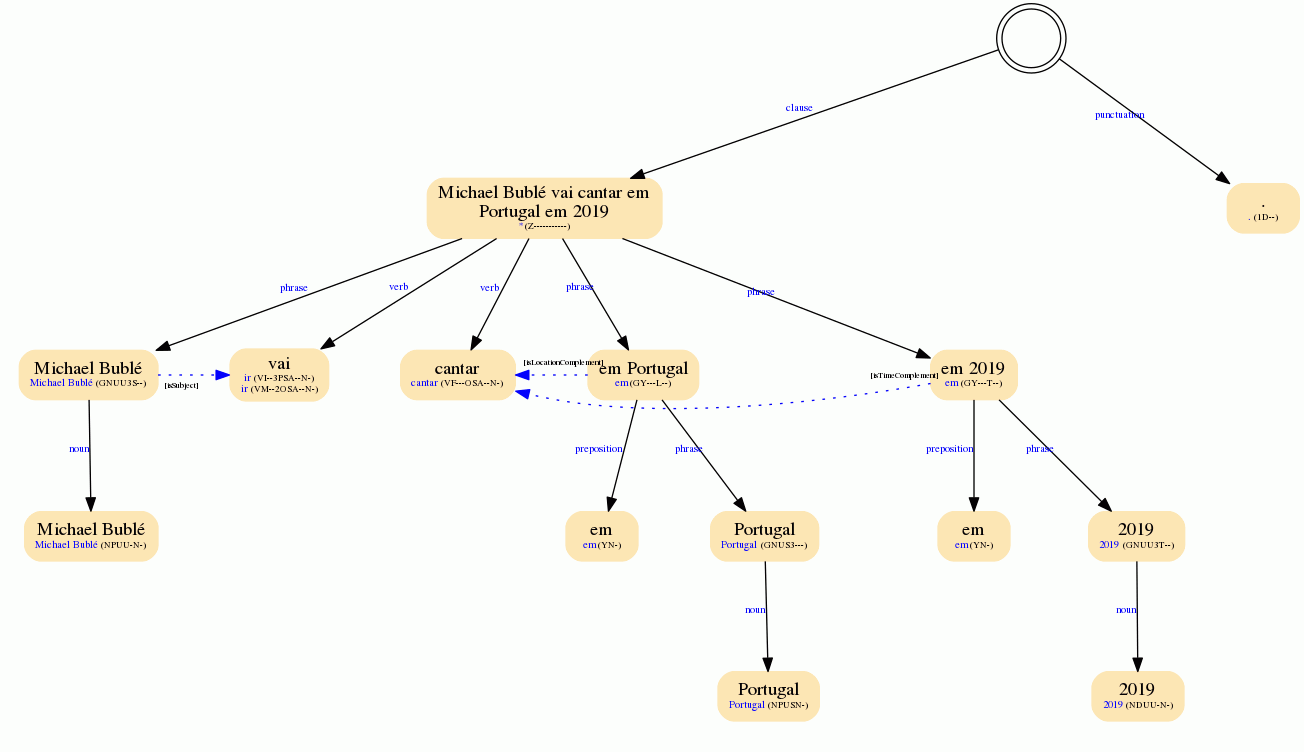
Este produto único do MeaningCloud fornece informações morfológicas, sintáticas e semânticas, tudo de uma só vez. Isso permite que você combine uma grande quantidade de informações e identifique os padrões que se encaixam ao seu caso de uso específico.
Por exemplo, se quiser identificar empresas investindo dinheiro em outras empresas, você pode combinar identificação de entidade e dinheiro para encontrar as empresas e as quantias de dinheiro, as informações morfológicas para reduzi-las aos casos onde o texto indica que o dinheiro foi investido e as informações sintáticas para saber quem fez o investimento e quem recebeu os fundos. É uma solução muito versátil para aqueles que buscam uma pesquisa minuciosa.
Compactação
A compactação fornece um meio útil de entender a essência de um documento. A compactação seleciona as frases mais relevantes de um texto específico e resume sobre o que se trata. Sua força reside na independência do idioma, então funciona com documentos em qualquer idioma.
Nossa funcionalidade de compactação permite que você selecione o número de frases em que deseja compactar seu documento. O texto do exemplo, reduzido a uma frase, seria:

Análise da estrutura do documento
Assim como a extração de tópicos, que extrai partes específicas das informações, a análise da estrutura do documento identifica e extrai seções diferentes de um determinado documento com conteúdo de marcação (como em PDF, arquivos do Microsoft Word ou páginas da Wikipédia). A análise da estrutura do documento do MeaningCloud atinge títulos, cabeçalhos, abstratos e e-mails.
Cada vez mais, tarefas focadas na extração de informações detalhadas de documentos oficiais padronizados (como relatórios financeiros ou licitações públicas) estão ganhando notoriedade. São documentos publicados periodicamente e contêm informações importantes que você pode querer extrair.
São, geralmente, documentos extensos, portanto, conhecer sua estrutura pode auxiliá-lo a ir para a seção na qual você está interessado sem ter que percorrer o documento inteiro.
Outros produtos
O MeaningCloud vai além e fornece dois serviços incomuns de análise de texto: Reputação empresarial e categorização profunda. O primeiro está disponível em espanhol e o segundo em espanhol e inglês, por enquanto. Informe-nos se tem interesse em ver essas funcionalidades em português em um futuro próximo.
Reputação empresarial
A reputação empresarial visa analisar o sentimento e a opinião associados com as organizações mencionadas em um texto de acordo com as diferentes categorias definidas em um modelo de reputação. Este modelo de reputação considera diversas dimensões reputacionais ou variáveis, como inovação, responsabilidade social, etc.
Esse serviço complexo combina a capacidade de três de nossos produtos em um só: Extração de tópicos, análise de sentimentos, e classificação de texto. Você pode aprender mais sobre seus processos subjacentes aqui.
Categorização profunda
A categorização profunda atribui uma ou mais categorias a um texto, usando um conjunto detalhado e abrangente de regras. Permite que você identifique cenários muito específicos usando uma combinação de regras morfológicas, semânticas e textuais. A categorização profunda diferencia da classificação de texto em desempenho e precisão. Enquanto a segunda trabalha com poucas taxonomias dependentes de idioma e um componente estatístico significativo, que leva a grandes resultados de desempenho para grandes taxonomias; a primeira emprega critérios detalhados de idioma como o elemento-chave, além da nossa análise morfossintática. A API de categorização profunda é a base para os nossos pacotes verticais, incluindo a voz do cliente e a voz do funcionário. Esses dois casos dizem respeito a textos escritos por clientes ou funcionários que abordam vários assuntos relacionados a negócios. Além disso, oferecemos este serviço para diferentes indústrias: varejo, serviços bancários, telecomunicações, hospitalidade, etc. Todos são altamente especializados devido às regras detalhadas relacionadas a cada campo.
Outra diferença entre categorização profunda e classificação de texto é que a segunda trabalha com o modelo de classificação IAB 1.0, enquanto a primeira funciona com a versão 2.0, o que leva a resultados mais refinados.
Todos esses serviços podem ser acessados pelas nossas APIs ou pelo uso de quaisquer das nossas integrações convenientes, incluindo nosso útil Add-in para Excel, nosso criativo App para Zapier ou nosso novo Google Sheets add-on. Se tiver qualquer dúvida, entre em contato conosco! Ficaremos felizes em ajudar.
