A few weeks ago we talked about MeaningCloud’s text analytics performance on French texts. Now it’s Portuguese time!
Portuguese, together with Spanish, has an enormous presence in South America. It is spoken by more than 200 million people in Brazil alone. Not only does it have an immense influence on the economy in South America but throughout Europe too, where it is used by more than 10 million speakers. Africa also has Portuguese-speakers. Angola, which has a population of more than 24 million people, recognizes Portuguese as their official language. Its presence in these three continents makes it hard to miss in our Standard Languages Pack. At MeaningCloud, we offer two Portuguese varieties: Brazilian Portuguese and European Portuguese.

Whether the concept “Text Analytics” sounds rather hazy or you are looking for something more specifically language-related, this post is for you. We keep in mind the language diversity and we want to show you all the functionalities we provide in Portuguese.
Text Analytics is about extracting useful information from texts or classifying them in ways that are effective to your purpose. With this in mind, at MeaningCloud we offer full coverage of several of Text Analytics’ key capabilities: Topics Extraction, Sentiment Analysis, Text Classification, Text Clustering, Language Identification, Lemmatization, PoS and Parsing, Summarization, Document Structure Analysis, Corporate Reputation, and Deep Categorization. Today, we are explaining what each of them is, what they can do for you and how you can fully profit from their potential.
Topics Extraction
We are going to start off with Topic Extraction. Given a text, this functionality extracts specific instances that fall into one of these predefined categories:
- Entities: people, organizations, places, etc.
- Concepts: significant keywords
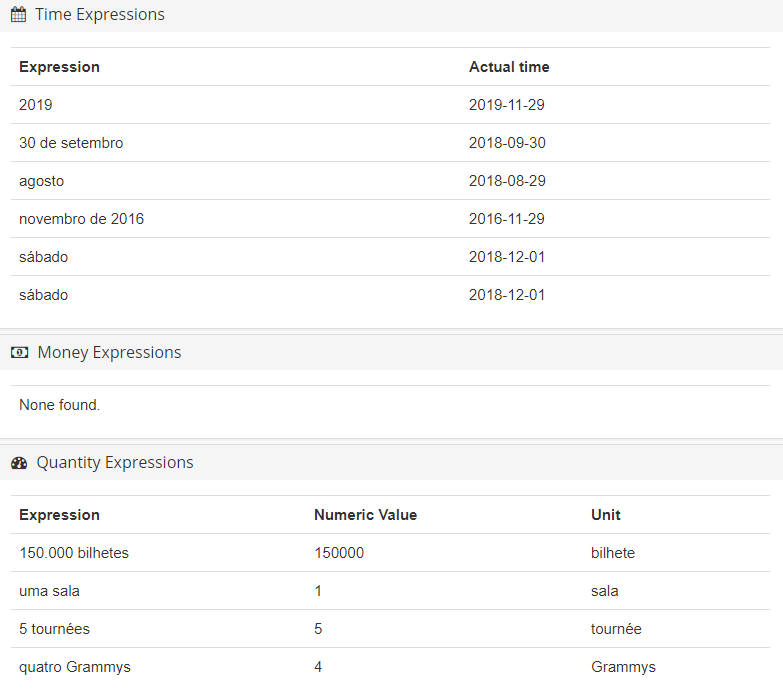
- Time expressions as “em 3 de outubro de 2018”
- Money expressions as “48€”
- Quantity expressions as “9 cães”
- Other expressions: alphanumeric patterns such as IDs, telephone numbers, etc.
This is a very helpful and powerful solution if you are looking to identify keywords at different levels. In order to see it function in more depth, let’s take this text as an example:
Michael Bublé vai cantar em Portugal em 2019
O concerto será na Altice Arena, em Lisboa, no dia 30 de setembro. O cantor regressou aos palcos em agosto, depois de um período de afastamento, com espetáculos em Dublin, Londres e Sidney para os quais foram vendidos mais de 150.000 bilhetes.
O cantor canadiano afastou-se dos palcos em novembro de 2016, quando soube do cancro do filho, tendo depois anunciado que iria lançar um álbum, “Love”, que será lançado no próximo sábado. No entanto, numa entrevista à revista US Weekly, o agente do cantor desmentiu a reforma do cantor e disse que Bublé não tem planos de se retirar.
Bublé volta assim à Altice Arena onde já atuou cinco vezes para uma sala esgotada. Os bilhetes serão colocados à venda no próximo sábado. O cantor já completou 5 tournées mundiais, ganhou quatro Grammys e vendeu mais de 60 milhões de álbuns.
Let’s see how the Topics Extraction feature works:

As said before, this solution recognizes not only entities but also dates, quantities, and money expressions. Moreover, Topics Extraction provides entity disambiguation and links its results to Wikipedia, an external knowledge source. This way, as Wikipedia contains unique identifiers that match with real-world entities, we have access to an even greater amount of information related to our text.
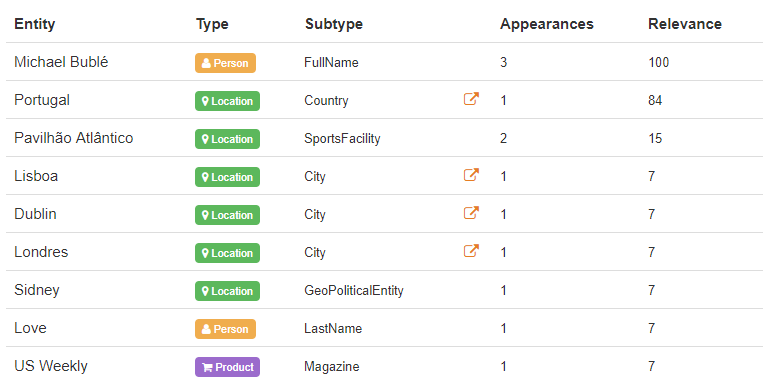 Concerning the entities extraction, a type is associated to individual entities, such as location, organization or product, etc., to make the selection of those you are interested in easier. For that, we rely on a rich and prolific ontology of ours.
Concerning the entities extraction, a type is associated to individual entities, such as location, organization or product, etc., to make the selection of those you are interested in easier. For that, we rely on a rich and prolific ontology of ours.
Lastly, in order to take full advantage of Topic Extraction, we offer a customization tool that allows you to create user dictionaries. These dictionaries allow you to accommodate its potential to your domain with your own ontology. Same power, more fine-tuned results.
Text Classification
If what you want is rather a product that classifies a document into one or more categories, MeaningCloud’s Text Classification is the perfect solution for you. This tool works with several generic models of predefined categories, or as we call them, classification models. Two of these models are IAB (a standard set of categories from the advertising industry) and IPTC (an international standard to classify news).

This solution is the fastest way to grasp what a text is about. The length of a text that can be used in this tool is varied, ranging from a simple tweet to an entire news article.
According to the Portuguese example shown previously, the IPTC model has labeled the text as “Arte, cultura e espetáculos”, which perfectly fits the theme.
Just like with Topics Extraction, Text Classification offers the possibility of defining your own classification model using our customization engine. We also have a tutorial on how to create a customized model in Excel.
Sentiment Analysis
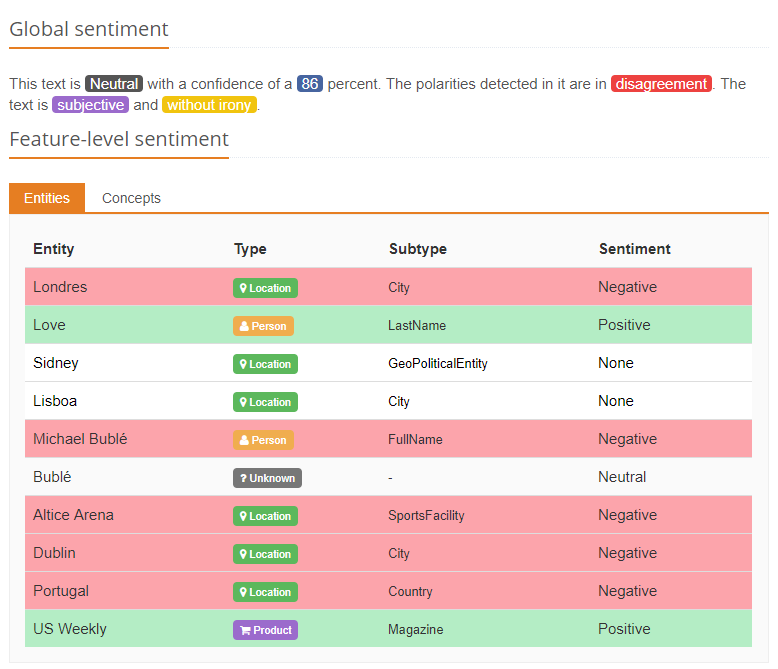
Sentiment Analysis extracts sentiment and performs opinion mining. Its function is to extract subjective information, as well as the polarity, in any given text either at global level or aspect-based level. At MeaningCloud, we take the nuances of the sentiments into consideration and we cover up to 6 levels of polarity: Strong Negative, Negative, Neutral, Positive, Strong Positive and No Sentiment.
By combining the morphosyntactic analysis and sentiment information, our Sentiment Analysis solution allows the identification of sentiments and opinions not only at a global level but also at a sentence level, analyzing each sentence individually to gain a deeper understanding of the text’s polarity.
Just like the last two products, Sentiment Analysis can be customized through our customization engine, both the sentiment associated to terms, as well as the entities and concepts to analyze at an aspect level.
If you want to check out a scenario where we apply this, check out our tutorial about how to adapt the sentiment analysis to your own domain.
Text Clustering
Text Clustering helps gathering groups of texts, named clusters, that are more similar to each other than those in other groups. In other words, Text Clustering is MeaningCloud’s solution for automatic document clustering. This type of analysis allows us to discover patterns through common elements, i.e. similarities, present in all the analyzed texts.
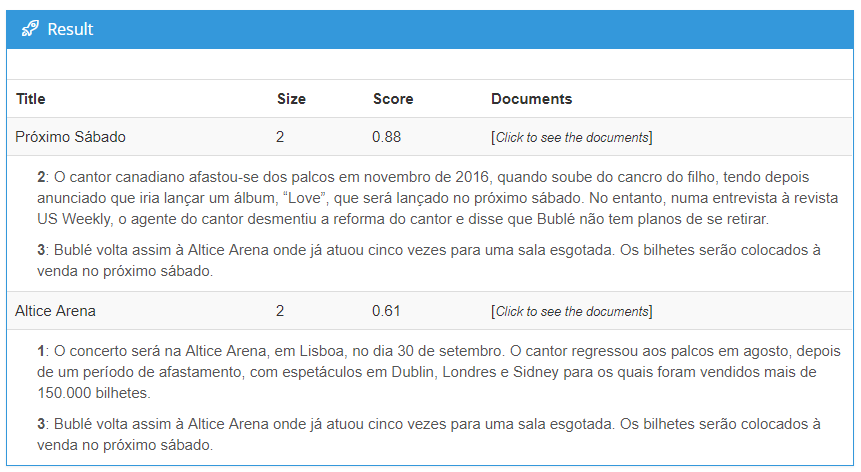
We can see that “next Saturday” (Próximo Sábado) is a commonality across paragraphs two and three, whereas paragraphs one and three have the Altice Arena as a converging element.
Besides grouping similar texts, Text Clustering can also be used to discover meaningful patterns between apparently unrelated texts.
Language Identification
MeaningCloud also offers a very useful service in an increasingly globalized world: Language Identification. It detects the language in which a text is written among 160 languages. Although this task is considered less significant, its importance is held in the multilingual scenarios we face daily, in which it is crucial to know the language we are going to operate all the remaining computational linguistic processes in.

Lemmatization, PoS and Parsing
When it comes to morphosyntactic analysis, Lemmatization, PoS (Part of Speech) and Parsing is MeaningCloud’s solution you are looking for. It breaks down into these operations:
- Lemmatization is the task in which all the inflected forms of a word reassemble into one neutral form (i.e. their lemma), in order to analyze all of them as a single unit.
- PoS tagging is the process of marking each word of the text with its corresponding grammatical category. These tags come in handy when creating fixed recognition patterns.
- Parsing, also called syntactic analysis, is the analysis of each element of a sentence and the functions they fulfill.
Here we can see an example of how a full syntactic analysis looks like in our Lemmatization, PoS and Parsing API:
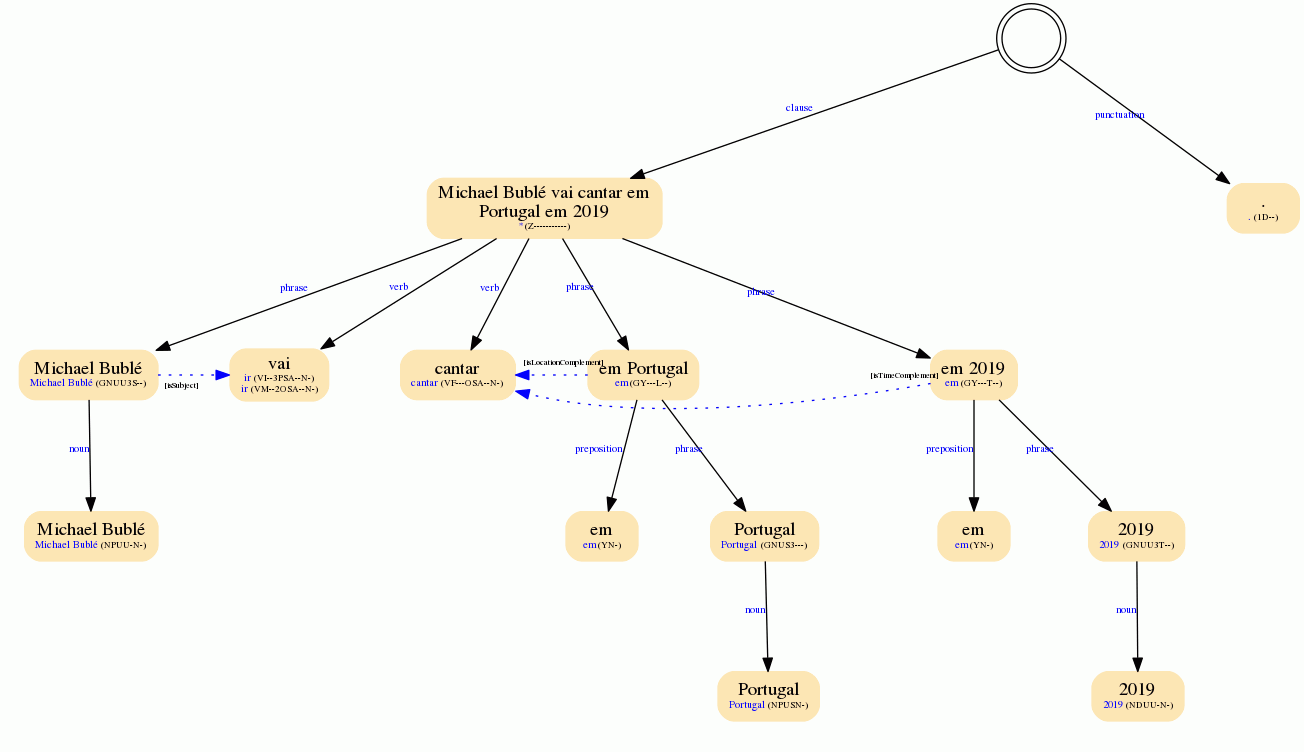
This single MeaningCloud product provides morphological, syntactical and semantic information all at once. This allows you to combine a huge amount of information and detect the patterns that fit your specific use case.
For instance, if you want to detect companies investing money in other companies, you can combine entity and money detection to find the companies and the amounts of money, the morphological information to narrow it down to those cases where the text indicates that money has been invested and the syntactic information to know who has made the investment and who has received funds. It is a very versatile solution for those looking for thorough research.
Summarization
Summarization provides a useful means of grasping the gist of a document. Summarization selects the most relevant sentences of a given text and sums up what it is about. Its strength is that it is language independent, so it works with documents in any language.
Our Summarization functionality allows you to select the number of sentences into which you want to summarize your document. The exemplary text, narrowed to one sentence, would become:

Document Structure Analysis
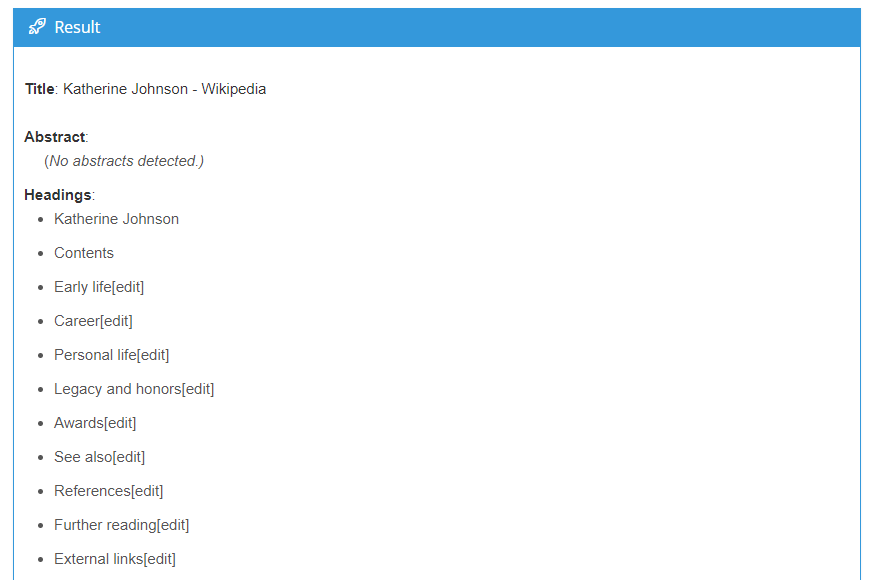
Similarly to Topics Extraction, which extracts specific pieces of information, Document Structure Analysis identifies and extracts different sections of a given document with markup content (as in PDFs, Microsoft Word files or Wikipedia pages). MeaningCloud’s Document Structure Analysis targets titles, headings, abstracts, and emails.
More and more, tasks focused on extracting detailed information from standard official documents (such as financial reports or public tenders) are gaining notoriety. They are published periodically and contain important information you may want to extract. They are in general large documents, so knowing their structure can help you go to the section you are interested in without having to go through the whole document.
Other products
MeaningCloud goes a step further and provides two uncommon text analytics service: Corporate Reputation and Deep Categorization. The first one is available in Spanish and the second one is available in both Spanish and English at this moment in time. Let us know if you are interested in seeing these functionalities work in Portuguese in the near future.
Corporate Reputation
Corporate Reputation aims to analyze the sentiment and opinion associated with the organizations mentioned in a text according to the different categories defined in a reputation model. This reputation model takes into account several reputational dimensions or variables, such as innovation, social responsibility, etc.
This complex service combines the capacity of three of our products in one: Topics Extraction, Sentiment Analysis, and Text Classification. You can learn more about its underlying processes here.
Deep Categorization
Deep Categorization assigns one or more categories to a text, using a detailed and comprehensive set of rules. It allows you to identify very specific scenarios using a combination of morphological, semantic and text rules. Deep Categorization differs from Text Classification in performance and precision. Whereas the latter works with little language-dependent taxonomies and a significant statistical component – which leads to great performance results for large taxonomies -, the former employs language-detailed criteria as the key element, together with our morphosyntactic analysis. The Deep Categorization API is the foundation for our Vertical Packs, including Voice of the Customer and Voice of the Employee. These two cases concern texts written either by customers or employees addressing several business-related issues. Moreover, we offer this service for different industries: retail, banking, telecommunication, hospitality, etc. All of them are highly specialized due to in-depth rules concerning each field.
Another difference between Deep Categorization and Text Classification is that the latter works with the classification model IAB 1.0 while Deep Categorization functions with its version 2.0, which leads into more refined results.
All these services can be accessed through our APIs or by using any of our convenient integrations, including our handy Add-in for Excel, our resourceful App for Zapier or our brand new Google Sheets add-on. If you have any further question, please, feel free to drop us a line! We will be happy to help.
