Nei nostri post precedenti abbiamo parlato dell’analisi del testo in francese e in portoghese utilizzando gli strumenti di Text Mining di MeaningCloud. Per concludere questa serie linguistica, oggi vediamo che tipo di analisi possiamo eseguire in italiano.
La lingua italiana viene parlata in diversi stati europei, tra i quali l’Italia, la Repubblica di San Marino, la Città del Vaticano, la Slovenia, la Croazia e la Svizzera, con un totale di quasi 70 milioni di parlanti. Poiché gli italiani sono emigrati in tutto il mondo, la loro lingua è presente anche dall’altra parte dell’oceano. In Sud America, per esempio, è la seconda lingua più parlata in Argentina. Negli Stati Uniti, nonostante non sia una delle lingue ufficiali, molti cittadini sono di origine italiana e quindi parlano italiano in patria. Per questo motivo abbiamo deciso di includere nel nostro pacchetto di lingue standard una lingua così diffusa.

Analogamente ai nostri post precedenti, spiegheremo da un punto di vista linguistico che cos’è l’analisi del testo (o Text Mining) e quali funzionalità fornisce MeaningCloud in italiano.
L’analisi del testo consiste nell’estrarre informazioni utili dai testi o classificarli secondo uno scopo specifico. MeaningCloud offre un ampio ventaglio di funzionalità chiave di Text Mining: estrazione di informazioni specifiche, analisi del sentimento, classificazione del testo, raggruppamento tematico, identificazione della lingua, lemmatizzazione, analisi sintattica, riassunto, analisi della struttura del documento, reputazione aziendale e categorizzazione profonda. Oggi vi spieghiamo come funziona ognuno di questi servizi, cosa possono fare per voi e come sfruttarne appieno il potenziale.
Estrazione di informazioni
Cominciamo con l’estrazione di informazioni (Topic Extraction). Questa funzionalità è capace di estrarre gli elementi del testo che corrispondono alle seguenti categorie predefinite:
- Entità: nomi di persone, organizzazioni, luoghi, ecc.
- Concetti: parole chiave significative
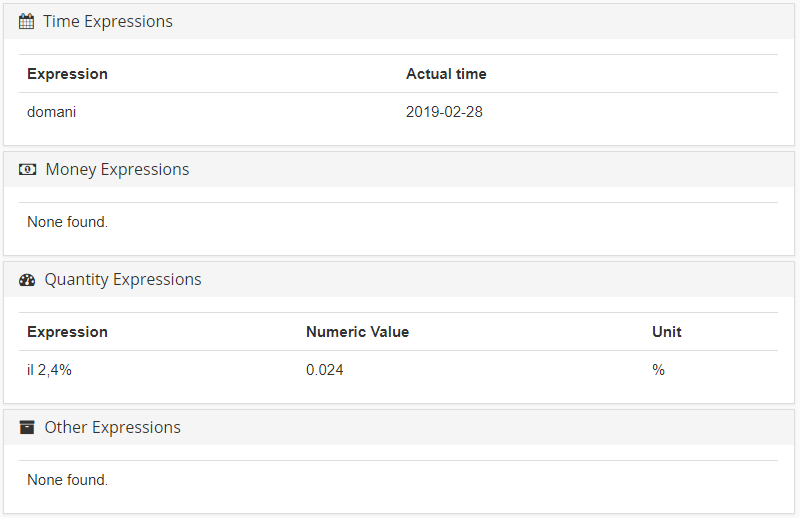
- Espressioni temporali, come “il 3 ottobre 2018”
- Quantità monetarie, come “48€”
- Espressioni di quantità, come “9 cani”
- Altre espressioni: elementi alfanumerici, come numeri d’identificazione o identità, numeri di telefono, ecc.
Si tratta della miglior soluzione per individuare parole chiave a diversi livelli. Per vedere come funziona, abbiamo selezionato questo testo come esempio:
Tria torna a Roma: «La Ue stia tranquilla». Juncker: «Euro a rischio»
MILANO – Riflettori puntati sul ministro dell’Economia, Giovanni Tria, andato a Lussemburgo per l’Eurogruppo, ma tornato in serata a Roma per dedicarsi alla chiusura della Nota di aggiornamento al Def, disertando quindi la riunione dell’Ecofin di domani. Il problema è il deficit dell’Italia sul quale è intervenuto il presidente della commissione Jean-Claude Juncker: «L’Italia si sta allontanando dagli obiettivi di bilancio concordati a livello europeo, abbiamo appena risolto la crisi della Grecia, non voglio ritrovarmi nella stessa situazione, una crisi è abbastanza. Se l’Italia vuole un trattamento speciale, sarebbe la fine dell’euro. Per questo dobbiamo essere molto rigidi».
Un’analisi che Tria respinge al mittente: «Non ci sarà nessuna fine dell’euro – replica il ministro dell’Economia – Ho parlato con i commissari Moscovici e Dombrovskis, non con Juncker. Sarà una sua opinione». Quindi la replica alle critiche per il rapporto deficit-pil previsto dall’Italia: il 2,4% «è un numero che non corrisponde esattamente ad alcune regole europee ma fa parte della normale dinamica europea, è sempre accaduto a molti Paesi nel corso degli ultimi decenni, se andate a vedere il numero di Paesi che sono in regola con tutte le regole europee sono pochissimi. Non significa che non bisogna cercare di rispettarle ma ci sono delle situazioni economiche in cui bisogna fare delle valutazioni».
Vediamo come funziona l’estrazione di informazioni:

Come abbiamo già detto, questa soluzione riconosce non solo le entità, ma anche le date, le quantità e le espressioni monetarie. Inoltre, Topics Extraction è capace di disambiguare le entità individuate e di collegare i risultati a Wikipedia come fonte di informazione esterna. In questo modo, dato che Wikipedia contiene identificatori univoci che corrispondono ad entità del mondo reale, abbiamo accesso ad una quantità ancora maggiore di informazioni relative al nostro testo.
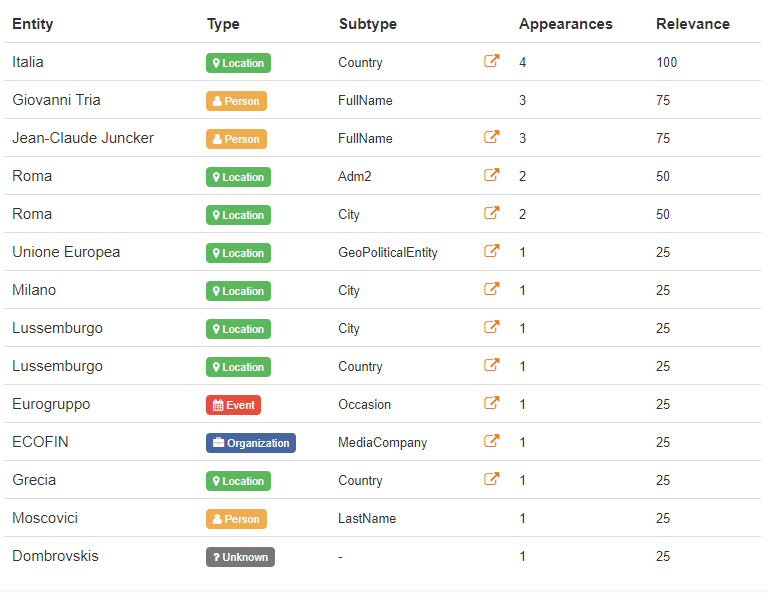
Per quanto riguarda l’estrazione delle entità, ognuna di esse viene associata ad un tipo (luogo, organizzazione, prodotto, ecc.) per facilitare la selezione di quelle in cui si è più interessati. Per questo scopo, utilizziamo la nostra estesa ontologia.
Infine, offriamo uno strumento di personalizzazione che peremtte di creare dizionari dell’utente per sfruttare pienamente l’estrazione di informazioni. I dizionari personalizzati consentono di adeguare questa funzionalità ad un’ontologia specifica, adatta alle vostre esigenze. Stessa potenza, risultati più precisi.
Classificazione automatica del testo
Se quello che cercate è un servizio di classificazione automatica del texto secondo uno schema di categorie, MeaningCloud ha la solutione perfetta per voi. Questo strumento funziona con diversi modelli generici di categorie predefinite o, come li chiamiamo noi, modelli di classificazione. Due di questi modelli sono IAB (uno standard addottato dall’industria pubblicitaria) e IPTC (standard internazionale per la classificazione di notizie).

Questa funzionalità rappresenta la maniera più rapida di capire di cosa parla un testo. È possibile classificare testi di differente lunghezza, spaziando da un semplice tweet a un intero articolo di cronaca.
Se proviamo a classificare il testo visto in precedenza, il modello IPTC ci dà come risultato «Economia, affari e finanza – Economia» e «Politica – Bilancio Statale», che rispecchia perfettamente la tematica trattata.
Come abbiamo visto per l’estrazione di informazioni, anche la classificazione automatica permette di definire modelli di classificazione propri utilizzando il motore di personalizzazione. Vi consigliamo di dare un’occhiata anche al nostro tutorial su come creare un modello personalizzato su Excel.
Analisi del sentimento
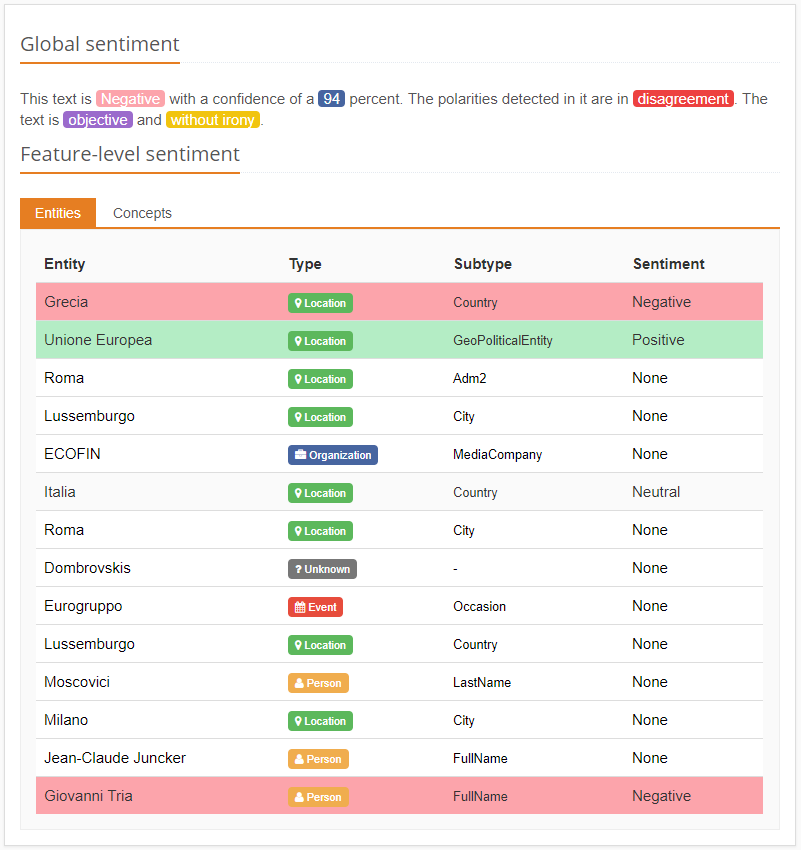
L’analisi del sentimento o d’opinione (Sentiment Analysis in inglese) estrae dal testo informazioni soggettive e la sua polarità, sia a livello globale che dettagliato. MeaningCloud è in grado di cogliere le diverse sfumature del sentimento e distingue sei livelli di polarità: fortemente negativa, negativa, neutra, positiva, fortemente positiva e senza sentimento.
Grazie alla combinazione dell’analisi morfosintattica con le informazioni sulla polarità, la nostra soluzione per l’analisi del sentimento permette di individuare il sentimento e il tipo di opinione non solo a livello globale, ma anche a livello di frase, favorendo una comprensione più profonda della polarità del testo analizzato.
Anche lo strumento di analisi del sentimento può essere personalizzato grazie al nostro motore di personalizzazione, sia per definire una polarità specifica per certi termini, che per decidere quali entità o concetti analizzare nel dettaglio.
Se desiderate vedere in quale scenario utilizziamo l’analisi del sentimento, date un’occhiata al nostro tutorial su come adattare l’analisi del sentimento al tuo settore.
Raggruppamento tematico
Il raggruppamento tematico, conosciuto come Text Clustering, serve a formare gruppi (o cluster) di testi in base al grado di affinità che esiste tra di essi. In altre parole, la nostra soluzione di Text Clustering è in grado di organizzare automaticamente i documenti secondo criteri di dipendenza. Questo tipo di analisi permette di scoprire legami formati da elementi comuni presenti nei testi analizzati.

Possiamo vedere che «Ministro dell’Economia» appare sia nel secondo paragrafo che nel quinto, mentre la parola «Europee» relaziona il terzo con il sesto.
Oltre a raggruppare testi simili, il Text Clustering può anche essere utilizzato per scoprire elementi comuni significativi tra testi apparentemente non correlati tra loro.
Identificazione della lingua
MeaningCloud offre un servizio fondamentale per un mondo sempre più globalizzato: l’identificazione della lingua. Questa funzionalità è in grado di individuare la lingua in cui è scritto un testo scegliendo tra 160 possibilità diverse. Sebbene questo scopo possa sembrare poco significativo, in realtà acquisisce importanza se lo applichiamo in un contesto quotidiano multilingue, dove è necessario sapere in che lingua dobbiamo svolgere gli altri processi linguistici computazionali previsti.

Lemmatizzazione, analisi sintattica e «parsing»
Lemmatizzazione, analisi sintattica e parsing è la soluzione di MeaningCloud per determinare la struttura grammaticale di un testo, ed esegue le seguenti operazioni:
- La lemmatizzazione riconduce la forma flessa di una parola alla sua forma neutra, chiamata lemma; in questo modo, ogni termine viene analizzato come elemento unico.
- IlTagging morfosintattico (PoS tagging) assegna ad ogni parola la corrisponente categoria grammaticale. Questa taggatura è particolarmente utile quando si creano modelli di riconoscimento fissi.
- L’analisi sintattica, (parsing) analizza ogni elemento della frase e specifica la sua funzione.
Ecco un esempio di come appare un’analisi sintattica completa della nostra API Lemmatization, PoS and Parsing:
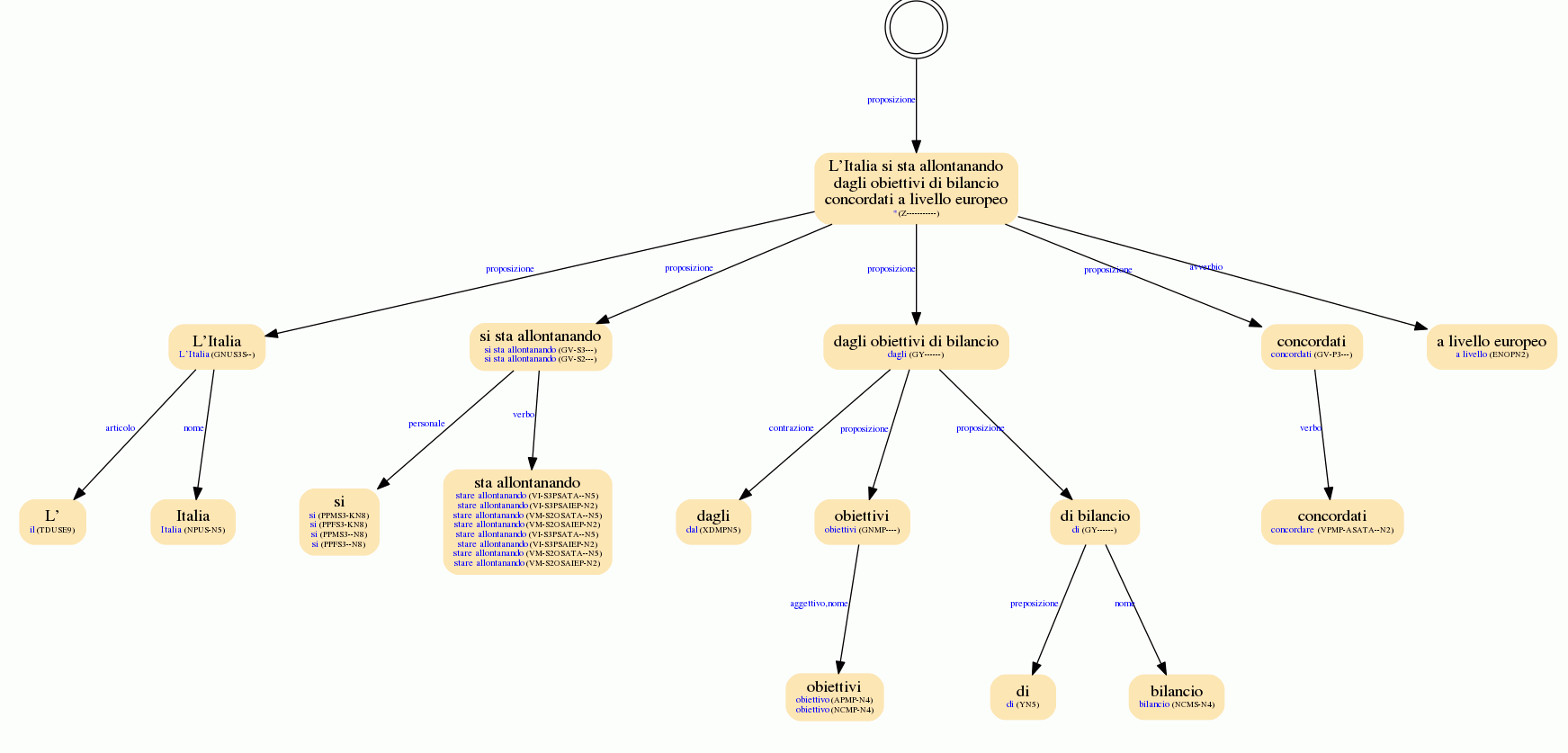
Questo servizio di MeaningCloud fornisce informazioni morfologiche, sintattiche e semantiche contemporaneamente. Ciò consente di combinare un’enorme quantità di informazioni e di individuare i modelli che si adattano al vostro caso d’uso specifico.
Per esempio, se desiderate individuare quali aziende investono denaro in altre aziende, è possibile combinare il rilevamento di entità ed espressioni monetarie per trovare le aziende e le quantità di denaro; le informazioni morfologiche sono fondamentali per restringere il campo a quei casi in cui il testo indica che il denaro è stato investito, mentre le informazioni sintattiche conosentono di sapere chi ha fatto l’investimento e chi ha ricevuto i fondi. Si tratta di una soluzione molto versatile che permette di effettuare ricerche approfondite.
Riassunto automatico
La soluzione di MeaningCloud per riassumere automaticamente un testo è in grado di mostrare il contenuto globale di un documento. Summarization (così si chiama la API) seleziona le frasi più important di un testo e ne crea il riassunto; uno dei suoi punti di forza è che è indipendente dalla lingua, per cui funziona con documenti in qualsiasi idioma.
La nostra funzionalità di riassunto automatico inoltre permette di selezionare il numero di frasi in cui si vuole riassumere un documento. Il riassuno di una frase del testo d’esempio che abbiamo già visto in precedenza sarebbe il seguente:

Analisi della struttura del documento
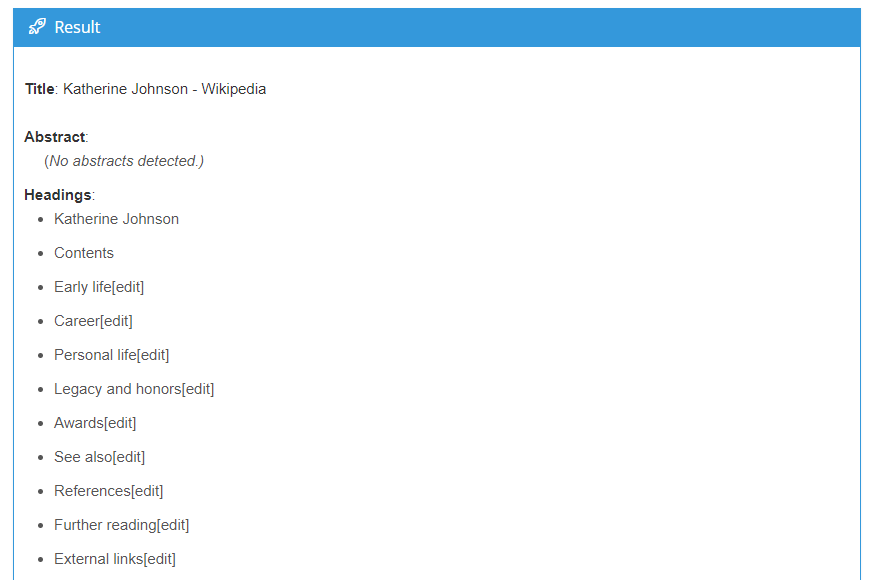
Come abbiamo visto per l’estrazione di informazioni, che identifica elementi informativi specifici, l’analisi della struttura del documento localizza ed estrae le differenti sezioni di un documento definite dal linguaggio di markup (per esempio, file in PDF, Microsoft Word o pagine di Wikipedia). L’analisi della struttura del documento di MeaningCloud riconosce titoli, intestazioni, abstract, sommari, email…
Negli ultimi tiempi, si parla sempre di più dell’estrazione di informazioni da documenti ufficiali standardizzati (come rapporti finanziari o appalti pubblici): vengono resi pubblici regolarmente e possono contenere informazioni per noi importanti. Si tratta generalmente di documenti grandi, perciò conoscerne la struttura permette di individuare le sezioni interessanti senza dover leggere il documento intero.
Altri prodotti
MeaningCloud fa un ulteriore passo avanti e offre anche due servizi di analitica del testo più complessi: reputazione aziendale e categorizzazione profonda. Il primo è disponibile solo in spagnolo, mentre il secondo sia in spagnolo che in inglese. Vi invitiamo a scriverci se vi piacerebbe disporre di queste funzionalità in italiano.
Reputazione aziendale
Reputazione aziendale analizza il sentimento e le opinioni associate alle organizzazioni menzionate in un testo secondo le diverse categorie definite in un modello di reputazione. Quest’ultimo si basa su numerose variabili o dimensioni reputazionali, come l’innovazione, la responsabilità sociale, ecc.
Questo servizio complesso combina in un solo prodotto tre dei nostri servizi: estrazione di informazioni, analisi del sentimento e classificazione automatica del testo. Per conoscere meglio i processi di questa soluzione, cliccate qui.
Categorizzazione profonda
La categorizzazione profonda assegna una o più categorie ad un testo grazie ad una serie di regole di classificazione dettagliate ed esaustive. La differenza tra categorizzazione profonda e classificazione automatica risiede nelle prestazioni e nella precisione. Mentre la seconda tecnologia utilizza tassonomie poco dipendenti dalla lingua del testo ed ha una spiccata componente statistica – vantaggiosa nel caso di tassonomie estese –, la prima si basa su criteri linguistici precisi e ricorre all’analisi sintattica. L’API di categorizzazione profonda costituisce la spina dorsale dei nostri pack verticali, come l’analisi della Voce del Cliente o della Voce del Dipendente i cui testi, scritti da clienti o impiegati, affrontano diverse questioni di natura commerciale. Offriamo questi servizi per diversi settori: commercio al dettaglio, banche, telecomunicazioni, turismo, ecc., che richiedono criteri di analisi altamente specifici.
Un’altra differenza tra la categorizzazione profonda e la classificazione automatica è che quest’ultima utilizza los standard di classificazione IAB 1.0, mentre la prima adotta la versione 2.0, molto più precisa e attuale.
Tutti i servizi che abbiamo decritto sono disponibili attraverso le nostre API o grazie alle nostre integrazioni per Excel, Zapier o Google Sheets. Se desiderate saperne di più, non esitate a scriverci: saremo felici di aiutarvi!
