Accuracy Measures of Commercial Sentiment Analysis APIs
Our clients frequently ask, “what’s the precision of MeaningCloud technology?” How does it compare with other commercial competitors and with state-of-the-art technology? And they demand precise numbers.
That’s not an easy question to answer. Even when there are milliards of research studies on this issue. For the sake of simplicity, let’s concentrate on the well-studied scenario of accuracy measures in Sentiment Analysis.
The academic approach
Most of the researchers do their work on publicly available annotated data sets from Twitter, movie reviews (IMDb), hotel reviews (TripAdvisor), restaurant reviews (Yelp), etc. Some of these datasets have been used in competitive research challenges (as SemEval) for years.
The methodology is almost always the same: you have developed a (more or less) new algorithm or problem approach. Then, you take a random sample from one of those data sets (typically 75-80%), train your system, and evaluate results with the remaining (20-25%) test set. The most rigorous researchers will repeat this process multiple times (cross-validation) to provide an average accuracy that considers the variability introduced by sampling. These days, lots of research combine results from different models (through ensemble, bagging, and boosting methods). Depending on the data set, it is not difficult to find papers whose authors claim accuracies over 90%. And there is nothing wrong with it. The limit has more to do with the consistency in manual tagging of the data set, the breath of the domain, the average size (in words) of the verbatims, the amount of irony present in the collection, etc. Researchers call this phenomenon overtraining or overfitting: constructing a model that corresponds too closely to a particular set of data and may therefore fail to fit additional data or predict future observations reliably.
Do you change the data set? No problem; you train a new model by applying your learning method, and you may reach similar accuracy levels again and again (considering the mentioned limits).
The commercial approaches to Sentiment Analysis
But what when you get more than 1 million requests per day (as we are receiving in our MeaningCloud platform) to analyze the sentiment in one piece of text that can be from one word or symbol to the thousands, from unknown users all around the world, about any domain? That’s a different problem.
Most of the commercial systems rely on machine learning (and deep learning in particular) from multiple tagged datasets (as mentioned above), including public product or service reviews that have a text part plus some quantitative evaluation (stars or marks). They feed their systems with as many datasets as they can.
All the machine learning techniques bear the burden of the bias present in the training sets. For example, it is well-known the case reported in 2017 (Google’s Sentiment Analyzer Thinks Being Gay Is Bad). Google was able to solve this issue in a few weeks. In any case, bias is the reason why commercial ML-based sentiment analysis systems may need some pre- or post-filtering. This additional processing is necessary to avoid that gender, race, religion, sexual orientation and similar factors lead to a socially unacceptable negative sentiment analysis result when applied to a particular piece of text.
Of course, machine learning is not the only method for sentiment analysis. There are also other ways to attack the problem that do not require a training set. One of them uses sentiment lexicons (sometimes with some minimum linguistic processing) that include words tagged with an intrinsic polarity (positive or negative).
In the case of MeaningCloud, we rely on linguistic parsing (morphological, syntactic, and semantic) of the text to be analyzed, plus a rule-based component. Rules contain a word or expression indicating polarity, the concept, action, or entity to which it qualifies, and its context. This approach permits to attach the polarity to one particular entity or concept (what is called aspect-based sentiment analysis) and, at the same time, identify related aspects as the objective/subjective point of view or ironic tone of the text. Of course, we use ML techniques in the background to extract candidates to feed our linguists’ workflow.
External evaluations of MeaningCloud’s accuracy
But let’s go back to the initial question. What’s our accuracy, after all?
A recent master’s thesis by Paolo Romeo compares three commercial tools (Google Cloud NLP API, Amazon Comprehend, and MeaningCloud) with other traditional machine learning approaches. The test set for comparison is the well-known Sentiment140 database, with 1.6 M tweets (half positive, half negative, 15 words per tweet on average). As you can see, MeaningCloud shows the lowest accuracy (67.3%), just 9% below the best performant system. I judge this as an excellent result for MeaningCloud. Our solution was the only one in the comparison where the test set was not part of the system’s training, as it happened with all the others (including Google and Amazon systems). The Sentiment140 database is, by far, the largest tagged sentiment analysis database, being the first source of reference for all the practitioners in the field, having been used extensively for training. Therefore, it was expected that Google and Amazon systems delivered results similar to other algorithms trained ad-hoc with the same dataset.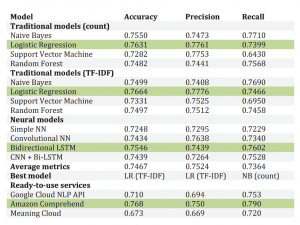
This research work shows something evident: general Sentiment models can never outperform systems trained with the very same dataset used for testing.
A more thorough evaluation was made recently at Universiti Malaysia Pahang by Nor Saradatul Akmar Zulkifli. This study compared the Python NLTK library, an academic system (Miopia), and MeaningCloud. The authors analyzed the sentiment of the reviews and comments on social media content in English with the three approaches. 2400 datasets from Amazon, Kaggle, IMDb, and Yelp were used to measure the accuracy with the following results: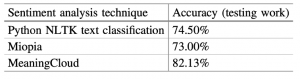
This research work reveals the consistent results (accuracy over 82%) obtained by MeaningCloud across domains and use cases. Comparison is not always easy, as researchers have to make some assumptions regarding the outcomes produced by different classifiers and differences in the coding of datasets. I would say that in general evaluations without specific training or adaptation, accuracies above 70% may be “good enough”. If you want to know everything about the metrics managed by researchers (accuracy, precision, recall, F1, LBA…), read the post “Performance Metrics for Text Categorization” by our Chief Innovation Manager Julio Villena.
The power of customization in NLP
We know that there is no one-size-fits-all in PLN in general, nor in Sentiment Analysis.
A recent paper by Alejandro Rodriguez (Technical University of Madrid) revealed that none of the commercial tools tried in their work (IBM Watson, Google Cloud, and MeaningCloud) did provide the accuracy level they were looking for in their research scenario: sentiment analysis of vaccine and disease-related tweets. By applying ML techniques, through the combination of results from the three systems, they were able to get an improved accuracy. As we mentioned above, there is always room for improving accuracy by combining some base classifiers at the cost of building a training set and developing a meta-model to learn from the correct and failed decisions of the base tools.
However, I’m afraid that this approach is not the most effective nor efficient way to improve results in such scenarios. At MeaningCloud, we put a lot of effort to empower our users with the tools that permit a quick path to accuracy improvement in any domain. In particular, you can:
- Declare or import ontologies of your domain (be groups of illnesses, adverse effects of drugs, genres of movies, types of touristic venues, etc.), linking them to our upper-level ontology.
- Add your own domain dictionaries, including diseases, people, companies, places…, and linking them to elements in your ontology (or in MeaningCloud’s ontology).
- Add or tune the sentiment rules according to the use of specific terms or expressions that appear typically in the verbatims you are dealing with.
Of course, that is work that we also carry out for our clients when required (and there is a value in it). And we also have ready-made resources (packages) for specific industries or business areas (as finance and health).
I have tried to address this repetitive question about our accuracy in a thorough (and honest) way in this post. Do not forget, please, to check out our posts on the subject of customization, as well as our tutorials:
https://www.meaningcloud.com/blog/category/meaningcloud/customization
https://www.meaningcloud.com/blog/category/meaningcloud/tutorials
References
[1] Paolo Romeo: “Twitter Sentiment Analysis: a Comparison of Available Techniques and Services”, Master Thesis, Technical University of Madrid, 2020.
[2] Nor Saradatul Akmar Zulkifli and Allen Wei Kiat Lee: “Sentiment Analysis in Social Media Based on English Language Multilingual Processing Using Three Different Analysis Techniques”, International Conference on Soft Computing in Data Science, SCDS, Springer, 2019.
[3] Alejandro Rodriguez et al.: “Creating a Metamodel Based on Machine Learning to Identify the Sentiment of Vaccine and Disease-Related Messages in Twitter: the MAVIS Study”, 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), 2020.
