One of the questions we get most often at our helpdesk is how to apply the text analytics functionalities that MeaningCloud provides to specific scenarios.
Users know they want to incorporate text analytics into their processes but are not sure how to translate their business requirements into something they can integrate into their pipeline.
If you add the fact that each provider has a different name for the products they offer to carry out specific text analytics tasks, it becomes difficult not just to get started, but even to know exactly what you need for your scenario.

In this post, we are going to explain what our different products are used for, the NLP (Natural Language Processing) tasks they are tied to, the added value they provide, and the requirements they fulfill.
[This post was last updated in October 2018 to include our new functionalities.]
Topics Extraction
Topics Extraction is MeaningCloud’s product for “automatically extracting structured information from unstructured and/or semi-structured machine-readable documents” [1]. In other words, Topics Extraction extracts specific pieces of information from collections of text, anything from names of people to locations or amounts of money.
There are a number of ways to refer to this task some, such as Named Entity Recognition are derived from its most popular subtasks. However, the objective is the same: extracting structured information from text.
Let’s take a look at the following text, taken from an article in the New York Times:
It’s Official: Simone Biles Is the World’s Best Gymnast
RIO DE JANEIRO — Simone Biles, already considered the world’s greatest female gymnast before even competing in the Olympics, emphatically confirmed her standing on Thursday by winning the women’s individual all-around gold medal at the Rio Games.
Wearing a stars-and-stripes leotard, Biles, 19, joined Mary Lou Retton, Carly Patterson, Nastia Liukin and Gabby Douglas as American all-around winners.
The American Aly Raisman, 22, won the silver, and Aliya Mustafina, 21, of Russia won bronze.
Victory in this event brings lucrative endorsements and widespread adoration, a popularity bonanza fueled by a prime-time showcase of athletic artistry. At 4 feet 9 inches, with size 5 feet, Biles is someone that young viewers can relate to. Then she performs, and her abilities are unimaginable.
Her ascent has been sudden to those who follow gymnastics only ever four years. At the last Summer Games, in London in 2012, Douglas was the show-stopper. Biles arrived here from Texas and gave the Rio Games a performance for the ages. Whether you know an Amanar from an aardvark, you watch her not because the result is in doubt but rather to witness something without equal.
So, how does this text look when we extract its information using our Topics Extraction API?
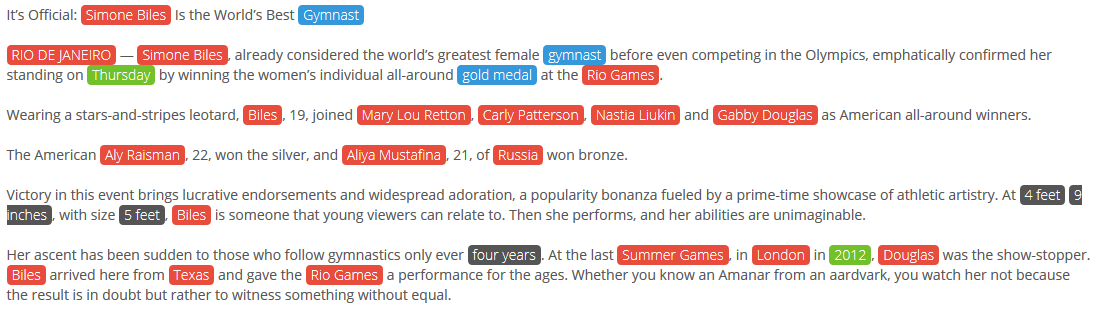
At first, it may seem that it’s just a matter of finding the names that appear in the text, but there’s a little more to it. There are many ways to refer to the same person, nicknames and variants of their name that you need to take into account. For instance, in this text the concept of “Simone Biles” appears five times, two with her full name, and three only using her last name.
But names or named entities, as they are often called are not the only thing we may want to extract. In the text we can also see quantities, dates, and keywords. Depending on the scenario you are working on, you will need to extract different types of structured information.
Sometimes, identifying all the named entities in a text is more than enough. For those instances, entities have a type associated, so you can choose to extract only locations, people, organizations, etc. You can check all the different types we detect in our ontology.
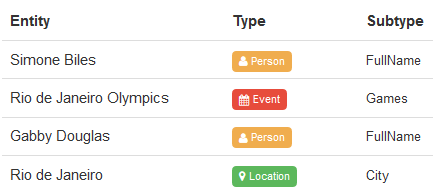
You can also define your own entries with their corresponding types through our customization engine. By using user dictionaries you will be able to extract the entities/concepts specific to your domain using your own ontology.
These are some scenarios in which Topics Extraction can be applied:
- Automatic tag suggestions for news articles or blog posts and semantic publishing
- Popularity analysis according to mentions
- Key data entity extraction
Text Classification/Deep Categorization
Text Classification and Deep Categorization are MeaningCloud’s products for document categorization or document classification, which is the task of “assigning a document to one or more classes or categories” [2]. In this case, instead of extracting something from a text, we analyze it and decide into which available category/categories it should be classified into.
This task assumes that we have a number of categories defined beforehand, and that we know the criteria that determines whether a text should be categorized into any of them. In MeaningCloud, we refer to this definition of both the categories and their criteria as classification models or deep categorization models.
So, why two products to implement the same functionality? The short answer is performance and precision. The long answer is that depending on the scenario we are working on, the criteria we will need to define our categories can be very different.
Taxonomies with very different categories do not need very language dependent criteria, and so they benefit from a classification engine with a statistical component and less language features available in the criteria definition. These two features have a high impact on the performance, providing great results for very large taxonomies. This is what you can do with the Text Classification API.
On the other hand, there are scenarios where being able to define the most detailed language features is key to correctly categorizing texts. For those instances we need to access all the information provided from our morphosyntactic analysis, which is exactly what you can do with Deep Categorization API. Think for example of a Voice of the Customer or Voice of the Employee scenarios where details such as the tense of the verb the client/employee is using can change what they are saying.
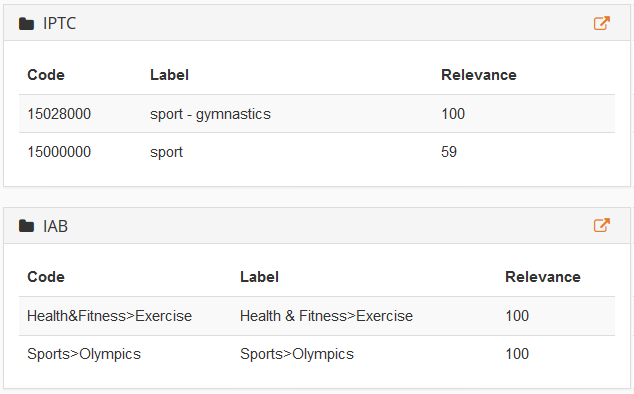
Our Text Classification API provides several generic predefined models such as IAB (a standard from the advertisement industry) or IPTC (an international standard to classify news). The Deep Categorization API provides the latest version of the IAB standard (IAB 2.0) as well as several models for Voice of the Customer and Voice of the Employee.
Going back to the example we used before, in the image on the right, we can see how our text is classified by the two predefined models we have mentioned for Text Classification.
Document classification/categorization gives us an idea of what a text is about according to specific criteria. This may apply to an article, a tweet or to the feedback you obtain from a customer.
In some instances, this generic criteria may not fit your needs, so for those cases you can define your own classification model through the use of our customization engine.
These are some scenarios in which Text Classification/Deep Categorization can be applied:
- Automatic tag suggestions for news articles or blog posts.
- Complete characterization (visual sorting) of user feedback according to different criteria.
Sentiment Analysis
Sentiment Analysis is MeaningCloud’s product for sentiment analysis or opinion mining, which is the task of “identifying and extracting subjective information in source materials” [3]. One of the most basic tasks in sentiment analysis is classifying the polarity of a given text at the document, sentence, or feature/aspect level.
Our Sentiment Analysis API combines the complete morphosyntactic analysis carried out by our core engine with sentiment information, which allows us to extract a sentiment analysis at every level.
We can obtain a global polarity of the text, or we can go in deeper and see the polarity expressed in each one of the sentences that make up the text.

On the right, we can see the global analysis we obtain for the text we’ve used as an example before. We have a polarity value with a level of confidence, an agreement/disagreement value to indicate if within the text all the polarities detected within the text per sentence/segment agree, a subjectivity value, and an irony value.
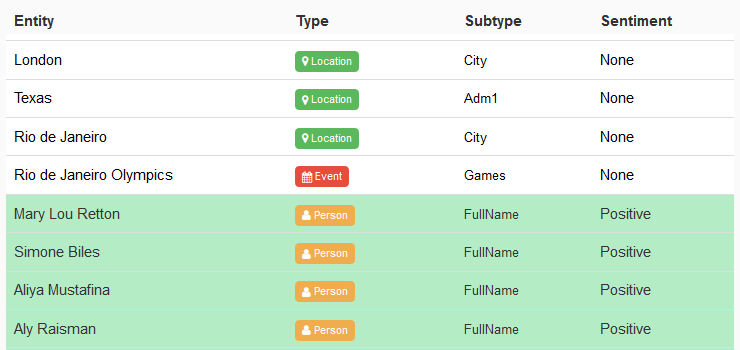
MeaningCloud also offers the possibility of combining this analysis with the Topics Extraction feature, allowing you to obtain the polarity associated to the entities and the concepts in the text. This is usually referred to as aspect-level sentiment analysis.
On the right, we see some of the entities detected. In the image, the entities detected with a positive polarity are shown in green—the athletes that have won medals—while the ones with no polarity are shown in blank rows.
Just like the other products we’ve mentioned, Sentiment Analysis can be customized through our customization engine, both the sentiment associated to terms, as well as the entities and concepts to analyze at an aspect level.
These are some scenarios in which Sentiment Analysis can be applied:
- Customer satisfaction analysis
- Popularity analysis
- Voice of the Costumer
Other products
Text Clustering
Text Clustering provides cluster analysis, the task of “grouping a set of objects in such a way that objects in the same group (called a cluster) are more similar (in some sense or another) to each other than to those in other groups (clusters)” [4].
In this case, the objects in question are texts, and the different types of analysis provided can help us discover patterns in them, either to visually sort the data or to learn new information about it and use it as feedback for other types of analysis. A possible use of Text Clustering is to apply it over the texts we are classifying using Text Classification in order to identify new categories to add to our model.
On the right, we can see the result we would obtain if we analyze the text we have used as an example with the next two paragraphs in the same article. The three texts are grouped into two different clusters: “Rio Games” and “Performs”, which fit their overall themes quite well.

Language Identification
Language Identification is MeaningCloud’s product for “determining which natural language given content is in” [5]. Though it is usually considered an auxiliary task, it’s no less important.
Any of the previously mentioned analysis need to know the language of the content to analyze. If you are working in a single language, this is not an issue, but nowadays, multilingual scenarios such as Twitter are more and more common, so having an API to carry out this task is extremely useful.
Lemmatization, PoS and Parsing
Lemmatization, PoS (part of speech) and Parsing provide a complete morphosyntactic analysis of a text:
- Lemmatization—the task of “grouping together the different inflected forms of a word so they can be analyzed as a single item” [6]
- PoS tagging or grammatical tagging—the task of “marking up a word in a text (corpus) as corresponding to a particular part of speech” [7]
- Parsing or syntactic analysis—the task of “analyzing a string of symbols, either in natural language or in computer languages, conforming to the rules of a formal grammar” [8]
On the right, there’s the morphosyntactic tree obtained from one of the sentences from the example text.
As you can probably guess from the image, this morphosyntactic tree is also combined with the Topics Extraction and Sentiment Analysis.
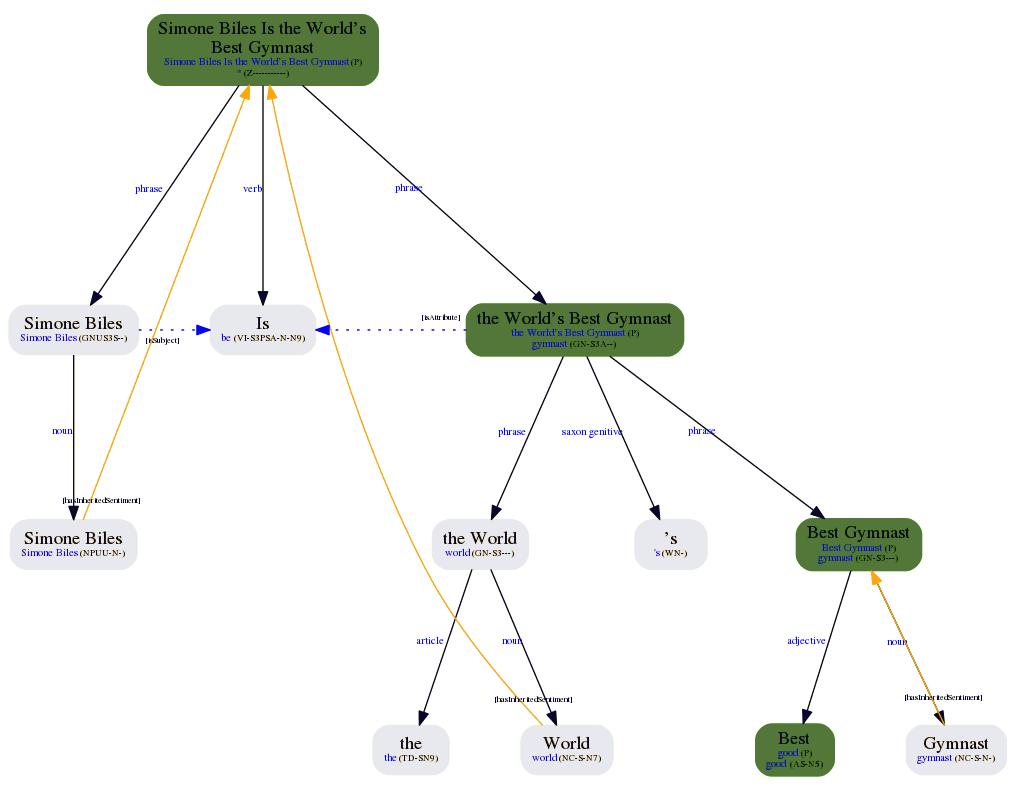
This provides an extremely powerful API, where you can combine sentiment analysis with morphological, syntactical and semantic information. The output is quite complex but it provides a myriad of possibilities for post-processing, including pattern extraction.
Summarization
Summarization is MeaningCloud’s product for “shortening a text document […] in order to create a summary with the major points of the original document” [9].
This task is one of NLP’s classics, one of significant complexity and extremely useful applications. There are two main approaches: extractive and abstractive. In the first one, the summary is extracted exclusively from the content of the text (for instance, selecting keywords that appear in it or some of its sentences) while abstractive summaries create a summary from scratch.
Our API extracts a summary with the number of sentences defined in the API request. If we use the Summarization Test Console to input the text we’ve been using throughout the post and set the number of sentences to 2, this is the result obtained:
RIO DE JANEIRO — Simone Biles, already considered the world’s greatest female gymnast before even competing in the Olympics, emphatically confirmed her standing on Thursday by winning the women’s individual all-around gold medal at the Rio Games. Biles arrived here from Texas and gave the Rio Games a performance for the ages.
Document Structure Analysis
Document Structure Analysis is MeaningCloud’s product for analyzing the structure of a document, which includes webpages or any text with standard markup language. This task is something that’s gained notoriety with the need to process large documents. Processing these type of documents is always costly, so for those scenarios where you are only interested in parts, it’s useful to have an a priori idea of their contents to know where to focus.
Corporate Reputation
Corporate Reputation is not a classic NLP task but a combination of several tasks focused on a specific application. “Reputation of a social entity (a person, a social group, an organization) is an opinion about that entity, typically a result of social evaluation on a set of criteria” [10].
By combining Topics Extraction, Sentiment Analysis and Text Classification, we are able to analyze the sentiment associated to organizations mentioned in a text according to the different categories defined in a reputation model.
This is a small summary of our main capabilities, which can be used through our APIs or using any of our integrations—including our Excel Add-in—if you don’t feel like coding. If you don’t see how they can apply to your scenario or have any questions about it, just drop us a line and we will be happy to help.

2 thoughts on “Text Analytics & MeaningCloud 101”
I am a Research Scholar and working with tourist blogs. I need to perform sentimental analysis on the tourist blogs and find their sentiments related to certain features of the destination. Can you please tell me how can I use your product for my research?
You can find a number of tutorials on how to use our different APIs (incluing Sentiment Analysis) here: https://www.meaningcloud.com/blog/category/meaningcloud/tutorials