We continue with the #ILovePolitics series of tutorials! We will show how to use MeaningCloud for extracting interesting insights to build your own Political Intel Reports and, at the same price, turning you into a Data Scientist giant in the field of Social Media Analytics.

Political issues
Politics and Social Media Analytics
Our research objective is to study and compare the discourse of different politicians during the electoral campaign, using their messages in Twitter. We are going to compare tweets by the four most popular (mentioned) politicians in our previous tutorial: Barack Obama (@barackobama), Hillary Clinton (@HillaryClinton), Donald Trump (@realDonaldTrump) and Jeb Bush (@JebBush).
- What are their key messages?
- What do they focus on?
- Are really there different ways of doing politics?
Before we start, three remarks: 1) we will focus on U.S. Politics, in English language, but the same analysis can be adapted for your own country or language as long as it is supported in MeaningCloud, 2) this is a technical tutorial: we will develop some coding, but in general, everyone can understand the purpose of this tutorial, and 3) although this tutorial will use PHP, any non-rookie programmer can translate the programs to any language.
Step 1: Getting a MeaningCloud license
By now you should have already created an account in MeaningCloud and gotten a license key for the APIs. Here we will use the Text Classification API, which allows you to categorize your texts into a hierarchical classification or taxonomy, in order to filter, sort, or group them, facilitate the search and navigation, or simply extract their meaning.
Step 2: Obtaining the tweets
Tweets can be obtained using one or another of the APIs offered by Twitter, depending on what data you are looking for. All the information is in the Twitter Developers site. The REST APIs give access to read and write Twitter data as a result of a call to one of the endpoints, whereas the Streaming APIs work by continuously delivering content pushed into an open listening connection.
In our case, we want to download the most recent tweets by a given user, so among all choices, the most suitable API is the REST GET statuses/user_timeline API.
Once upon a time, version 1.0 REST APIs allowed a number of unauthenticated requests to the APIs. Alas, not any more and so in version 1.1 we need an access license. This can be obtained for free: first create an application in Application Management, signing in with a Twitter account, then go to “manage keys and access tokens” to create your access token that is needed to make API requests. Once you do this, you must end up with four different values:
- Consumer Key (API Key): 8xMr********T4Q7
- Consumer Secret (API Secret): 8KCW****************rfll
- Access Token: 2313******-nYjx****************HGNo
- Access Token Secret: Gat3********************************A5SQ
There are many PHP libraries to deal with OAuth and work with the Twitter APIs. One of the most popular is tmhOAuth by @themattharris (which is excellent and we highly recommend). However, as we just need the basic functionality, an easier choice is Twitter-API-PHP by @j7mbo, a very simple and actively maintained wrapper for the Twitter v1.1 REST API that uses cURL for authenticated requests. Take a look at the examples, really easy, isn’t it?
The following program shows the very basic client that we have written to get the most recent N tweets by a given user. The Twitter Auth information is defined in the $TWITTER_AUTH array, containing the four values above, and the getTweetsByUser function is the one that actually makes the call to the API using the screen_name (Twitter user) and count (number of tweets to get) parameters and returns a JSON array with all tweets.
The information returned for each tweet is quite extensive. Here we are interested just in the $tweet[‘text’] content…  However, if you are not familiar with these APIs, just print_r($tweet) to check the amazing bunch of information returned!
However, if you are not familiar with these APIs, just print_r($tweet) to check the amazing bunch of information returned!
Step 3: Classifying
Next step is to call MeaningCloud’s Text Classification API to categorize the texts by assigning each tweet to one or several predefined categories from a given model. The following program shows how we implemented this part. To run this code, you just need to copy a valid license key for accessing the API into the appropriate place.
In our case, we will use IPTC model for classification. The International Press Telecommunications Council (IPTC) is an international consortium of the world’s major news agencies, news publishers and news industry vendors. The IPTC model allows to standardize the categorization of news articles and is used by virtually every major news organization in the world. Our model is built for the categories defined by the edition released in December 2010 of the IPTC’s subject code taxonomy, which contains 1388 non-deprecated categories.
Although it is defined for news classification, it can be also used to detect what people are talking about.
Going back to the code, we have defined the auxiliary postRequest function (reused from a previous tutorial) to make a POST request to a given API access point. The main function, getCategories, which receives the text, its language and the classification model to use, builds the actual API call and reads the JSON response into a PHP data structure.
The parameters for the class-1.1 API are:
- key: MeaningCloud license key
- model: classification model to use as $model_$language, ‘IPTC_en‘ for IPTC in English
- txt: actual text
- title: content description
The output of the program is shown in the image on the right.
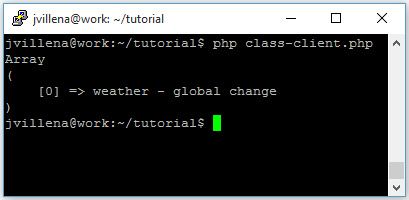
If you’ve read the code in detail you may have found a bit strange that we are passing the text in both the txt and the title parameters. The title parameter is used to give extra information to the classification engine, indicating that those terms are more relevant for the classification process than the terms appearing in the text. The typical use is the case of a news article, with the title and the content, in the two different parameters. However, when the text is short, as in the case of tweets, one trick is to pass the text in both the txt and title parameters, to boost the terms of the tweet, like giving importance and forcing the classification engine to use all the terms in the whole tweet. This way, the results give a lower rate of “uncategorized” tweets.
Step 4: Bringing it all together
Take a look at the complete program where we combine everything we’ve seen.
The idea is first to download the 100 most recent tweets by each of the four Twitter accounts and then, make a call to the API is to get the categories ($iptc array) for each tweet ($tweet object). In some cases, no category can be detected (an “unknown” tweet), because the text is ambiguous, the model needs some improvements, or there is no category in IPTC for that topic! In these cases, we discarded the tweet for the stats.
In most cases, one or several categories are detected. For the sake of simplicity of the analysis, instead of storing the complete 3-level IPTC code, we just keep the 1st level (top level subject codes). Then we aggregate the information into the $categories array considering the tweets belonging to each of these top level categories.
Last, but not least, the array is sorted by descending number of tweets matching every category and then everything is printed on the screen.
An actual example of the whole output when running the program is included here.
Step 5: Your own Intel Report
How do we understand these results?
At the time of running this tutorial, 12:00 UTC on November 6th 2015, these were the hot topics in the 100 most recent tweets of each politician with the percentage they represent of the total of tweets, and of the total of tweets with a known category (NU = Not Unknown).
| Topic | Tweets | % NU | % TOTAL |
| politics | 30 | 42.25% | 30% |
| unrest, conflicts and war | 12 | 16.9% | 12% |
| labour | 11 | 15.49% | 11% |
| social issue | 9 | 12.68% | 9% |
| economy, business and finance | 9 | 12.68% | 9% |
| sport | 8 | 11.27% | 8% |
| arts, culture and entertainment | 8 | 11.27% | 8% |
| weather | 6 | 8.45% | 6% |
| crime, law and justice | 5 | 7.04% | 5% |
| human interest | 4 | 5.63% | 4% |
| environmental issue | 3 | 4.23% | 3% |
| health | 3 | 4.23% | 3% |
| education | 3 | 4.23% | 3% |
| disaster and accident | 2 | 2.82% | 2% |
| lifestyle and leisure | 2 | 2.82% | 2% |
| Topic | Tweets | % NU | % TOTAL |
| politics | 20 | 37.74% | 20% |
| social issue | 16 | 30.19% | 16% |
| crime, law and justice | 7 | 13.21% | 7% |
| economy, business and finance | 6 | 11.32% | 6% |
| unrest, conflicts and war | 5 | 9.43% | 5% |
| sport | 3 | 5.66% | 3% |
| labour | 3 | 5.66% | 3% |
| arts, culture and entertainment | 3 | 5.66% | 3% |
| education | 2 | 3.77% | 2% |
| health | 1 | 1.89% | 1% |
| disaster and accident | 1 | 1.89% | 1% |
| environmental issue | 1 | 1.89% | 1% |
| weather | 1 | 1.89% | 1% |
| Topic | Tweets | % NU | % |
| politics | 29 | 45.31% | 29% |
| arts, culture and entertainment | 14 | 21.88% | 14% |
| social issue | 12 | 18.75% | 12% |
| human interest | 7 | 10.94% | 7% |
| economy, business and finance | 5 | 7.81% | 5% |
| labour | 2 | 3.13% | 2% |
| sport | 2 | 3.13% | 2% |
| education | 1 | 1.56% | 1% |
| lifestyle and leisure | 1 | 1.56% | 1% |
| crime, law and justice | 1 | 1.56% | 1% |
| science and technology | 1 | 1.56% | 1% |
| Topic | Tweets | % NU | % |
| politics | 17 | 30.36% | 17% |
| education | 10 | 17.86% | 10% |
| sport | 9 | 16.07% | 9% |
| economy, business and finance | 7 | 12.5% | 7% |
| disaster and accident | 4 | 7.14% | 4% |
| arts, culture and entertainment | 7.14% | 4% | |
| labour | 3 | 5.36% | 3% |
| crime, law and justice | 3 | 5.36% | 3% |
| human interest | 2 | 3.57% | 2% |
| social issue | 2 | 3.57% | 2% |
| religion and belief | 1 | 1.79% | 1% |
| environmental issue | 1 | 1.79% | 1% |
| lifestyle and leisure | 1 | 1.79% | 1% |
In the analysis we’ve found that 39% of the tweets are unknown, so we will not take them into account for our analysis. The reason for these many tweets classified as unknown comes from the fact the analysis is carried out with a generic model which does not take into account something that we see more and more these days in tweets: hashtags that provide context. A clear example of this are some of Obama’s tweets using the hashtag #GetCovered, which is the only indication in the tweet that it’s related to health issues.
Taking that into account, there are several things we can remark on from the results:
- Unsurprisingly, the most frequent topic is politics.
- The categories human interest and arts, culture and entertainment in many cases seem to emerge when the tweet refers to a meeting, convention or political event or a TV/radio program, so they could be merged and renamed as political campaign.
- Many tweets are incorrectly identified as sport when guns are mentioned or when the politicians that are campaigning mention touring a state.
If we take a closer look and combine what we know about the different politicians, we observe the following:
- Donald Trump is definitely the most “political animal” among the candidates, as he has the most tweets identified as related to politics. We can also see that the sudden interest in arts, culture and entertainment is not related to his candidacy, but to the recent publication of his new book.
- Jeb Bush has a high number of tweets related to the education and sport categories, which is unsurprising as in recent events he has mentioned his proposal for an education reform. He’s also been to a rally event, and in a tri-state tour, which explains the high rank of the sport category.
- Hillary Clinton‘s discourse is focused on social issues (30%), which may be related to the priorities of some of the demographics segments in which she traditionally polls higher. It’s followed by crime, law and justice, which has re-appeared as the debate on the problem with gun violence in the country gains importance.
- The category religion and belief, only appears in Jeb Bush tweets, which makes sense considering that it’s usually a more significant talking point for republican candidates.
- President Barack Obama‘s most talked about issues are in general related to what he has been up to recently. This time it’s the sport category which comes from his receiving the National Women Soccer Team after their victory in the World Cup. An important issue is also crime, law and justice, again related to the country’s problems with gun violence. The high number of tweets in labour come mostly from labour – collective contract – contract issue-healthcare, which is clearly related health care, one of Obama’s biggest bills passed to day.
Step 6: What’s next?
The analysis we’ve carried out has been done just over a small portion of tweets. If we run this during several months and compare the results, we would be able to obtain a very interesting trend analysis on which issues the different candidates talk about, how their agenda changes with the polling results or by current events, etc. Higher precision can easily be achieved by creating your own classification model and optimizing it for this specific domain instead of using a generic model. The exercise is left to you…
We will be back with more political insights to study in the next tutorial. Stay tuned!

One thought on “#ILovePolitics: Political discourse analysis in social media”
Hello,
How would you modify the script to so that it queries twitter with a keyword? So, instead of searching by username, it uses a keyword phrase instead? Thanks for the wonderful tutorial!