In one of our previous posts we talked about Financial Compliance, FinTech and its relation to Text Analytics. We also showed the need for normalized facts for mining text in search of suspects of financial crimes and proposed the form SVO (subject, verb, object) to do so.

Financial crime
Thus, we had defined clause as the string within the sentence capable to convey an autonomous fact. Finally, we had explained how to integrate with the Lemmatization, PoS and Parsing API in order to get a fully syntactic and semantic enriched JSON-formatted tree for input text, from which we will work extracting SVO clauses.
In this post, we are going to continue with the extraction process, seeing in detail how to work to extract those clauses from the response returned by the Parsing API.
JSON tree structure
First, let us get familiar with the tree structure obtained from the API response. The parser groups chunks of tokens around the concept of phrase to be PoS-tagged. You can read more about what we use to tag the different parts of speech in the morphosyntactic tagsets section of the documentation.
Let’s take a look at the following example:
Someone reported that the judge condemned Hoax LLC for defrauding customers.
This is a fragment of the output returned by the API:

We notice how the embedded clause stating the judge’s judgement over Hoax LLC is included in the broader statement of the reported sentence. If we check the “tag” field in the response (contained within the field “analysis_list“), we can see that both are tagged as clauses: the first position is a ‘Z’, which we know from the morphosyntactic tagset for English that that’s what we use precisely to PoS-tag clauses.
So, we will need to list all tokens tagged with ‘Z’ and recursively remove embedded clauses out from their container main clauses. We can do this by checking the second position in the tag, the ‘clause type’: main clauses will not have a clause type defined.
If we don’t remove the main clauses, we will come up with overlapping strings representing the clauses.
Normalizing clauses under the form SVO
Every clause can be represented under the form SVO, but we have to take into account that grammatical subject (the phrase that is in morphological agreement with the verb) is not always the logical subject of the action (as in passive voice sentences). That’s why we need to identify the voice of a clause first (passive or active voice) in order to extract subject and direct object later.
In the syntactic tree, the clause verb carries on that kind of information as well the ID pointing to its grammatical subject or direct object in the JSON field ‘syntactic_tree_relation_list’ under the field ‘id‘.
If we search for phrases corresponding with those identifiers we will extract subject and object for each verb.
For instance, for the above mentioned example:
INPUT TEXT: Someone reported that the judge condemned Hoax LLC for defrauding customers.
Clause 0: Someone reported
Subject: Someone – Is proper noun:false
Verb: report – voice:active
Object: that the judge condemned Hoax LLC for defrauding customers – Is proper noun:true
————Clause 1: that the judge condemned Hoax LLC for
Subject: the judge – Is proper noun:false
Verb: condemn – voice:active
Object: Hoax LLC – Is proper noun:true
The following image shows where we can find the information we’ve just referred to in the syntactic tree:
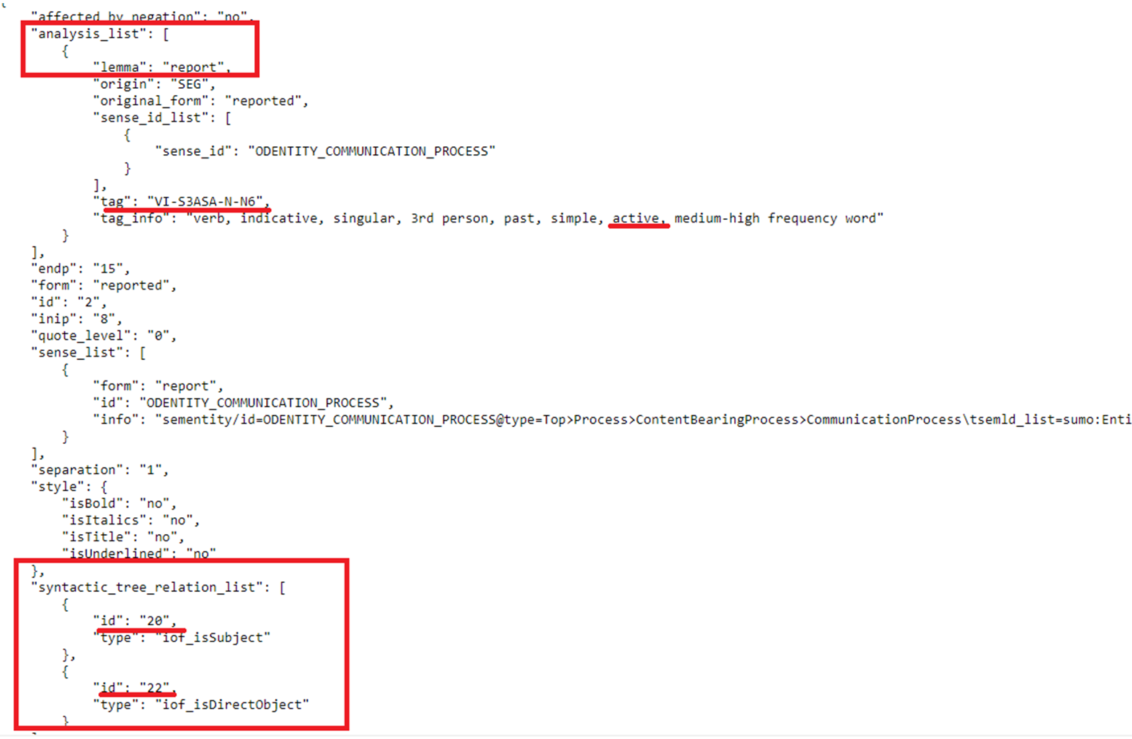
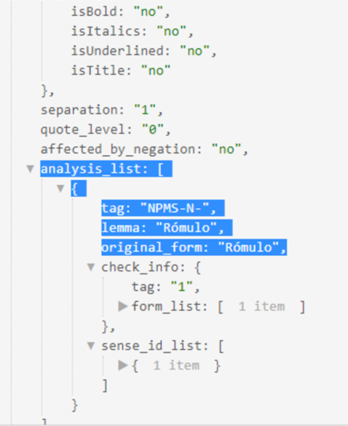
Take into account that for verbs in passive voice, the logical subject in SVO slots should be extracted from the AgentComplement, while the grammatical subject should be represented in fact as the direct object in the normalized slots.
In this image, you can see how the information mentioned would appear for the following sentence:
Rome was built by Romulo.
Finally, as we are interested only in financial compliance reporting suspicious activities from persons or companies, we need to be able to check if the Subject slot is a proper noun. As we did to identify clauses, we will use the morphological information included in the tag field to do it.
The morphosyntactic tagset for English tells us that proper nouns are tagged with ‘NP’ in the first and second positions of the tag (the part of speech position and the noun type position), so we will select every token contained in the phrases that satisfies that condition.
That way we won’t detect false positive actions as in next example, where there is no suspect at all for financial crimes:
A surprisingly poor quality of the products defrauded customer’s expectations.
Financial compliance rules based on SVO slots
At this point, we are ready to model simple financial compliance rules based on SVO slots. Basically, we will populate a list of hints, including:
Criminal offenses (lemmatized nouns)
['bribery', 'fraud', 'evasion', 'money laundering', 'embezzlement', 'drug', 'narcotic', 'narcotics', 'smuggling', 'bankruptcy']
Criminal actions (lemmatized verbs)
['scam', 'bribe', 'defraud', 'evade', 'bankrupt', 'skim']
Performative verbs
['make', 'commit', 'plan', 'organize', 'do', 'carry out', 'implement', 'articulate', 'scheme', 'run', 'elaborate']
Accusation verbs
['accuse', 'investigate', 'condemn', 'process', 'implicate', 'involve', 'suspect', 'relate']
Then, we will observe just three patterns covering most productive variations of linguistic utterances:
- A company or person committed a criminal action
if a_clause.verb.lemma is not None and
a_clause.verb.lemma.lower() in actions[language] and
a_clause.subject is not None and
a_clause.subject.is_proper_noun:
result.append("FINANCIAL COMPLIANCE DETECTED - person or company committed an action")
if a_clause.verb.lemma is not None and
a_clause.verb.lemma.lower() in performative_verbs[language] and
a_clause.subject is not None and
a_clause.subject.is_proper_noun and
a_clause.object is not None and
a_clause.object.lemma in offenses[language]:
result.append("FINANCIAL COMPLIANCE DETECTED - person or company commit offense")
if a_clause.verb.lemma is not None and
a_clause.verb.lemma.lower() in accusative_verbs[language] and
a_clause.object is not None and
a_clause.object.is_proper_noun:
if any(a_clause.contains_lemma(an_offense) for an_offense in offenses[language] + actions[language]):
result.append("FINANCIAL COMPLIANCE DETECTED - person or company is accused of offense or action")
An example based on real news
We will test the entire pipeline with a real-world news on economics. Eventually, we may want to input the financial compliance model with real-time news feeds. For example, let us take the text of the following recent news:
Pensacola stock broker defrauded widow of $1 million in insurance proceeds
We get the following output, where clause 31 has been detected as the target of our financial compliance model. Below you can see some of the clauses detected, and you can find here the complete results:
Clause 0: Escambia County Circuit Judge Thomas Dannheisser presided over the trial,
Subject: Escambia County Circuit Judge Thomas Dannheisser – Is proper noun:true
Verb: preside – voice:active
Object: None
————
Clause 1: which was prosecuted by Assistant State Attorney Russell Edgar.
Subject: Assistant State Attorney Russell Edgar – Is proper noun:true
Verb: prosecute – voice: passive
Object: County Circuit Judge Thomas Dannheisser – Is proper noun:true
————
…
————
Clause 30: referred by the FBI
Subject: None
Verb: refer – voice:active
Object: None
————
FINANCIAL COMPLIANCE DETECTED – person or company committed an action
Clause 31: that Ronald Ball had defrauded a physician’s widow of more than $1 million of life insurance proceeds.
Subject: Ronald Clark Ball – Is proper noun:true
Verb: defraud – voice:active
Object: a physician’s widow of more than $1 million of life insurance proceeds – Is proper noun:false
————
Clause 32: An Escambia County Jury convicted Ronald Clark Ball of nine felony charges, including three counts of grand theft, two counts of money , two counts of racketeering
Subject: An Escambia County Jury – Is proper noun:true
Verb: convict – voice:active
Object: Ronald Clark Ball – Is proper noun:true
————
…
Conclusions
All throughout this post, we have shown how certain real-world problems based on texts can be approached using text analytics, more specifically the complete morphosyntactic tree provided by Lemmatization, PoS and Parsing API.
This API provides a huge amount of raw information that can be used for a myriad of applications, including the one we’ve described in this post: modeling clauses of the form SVO (subject, verb, object). This powerful approach exceeds the mere domain of financial compliance and can be applied to several challenging linguistic problems around information extraction.
