What is Financial Compliance and what is FinTech?

Financial crime
Financial crime has increasingly become of concern to governments throughout the world. The emergence of vast regulatory environments furthered the degree of compliance expected even from other non-governmental organizations that conduct financial transactions with consumers, including credit card companies, banks, credit unions, payday loan companies, and mortgage companies.
Technology has helped financial services address the increased burden of compliance in innovative ways which have also yielded other benefits, including improved decision-making, better risk management, and an enhanced user experience for the consumer or investor.
The rapid development and employment of AI (Artificial Intelligence) techniques within this specific domain have the potential to transform the financial services industry.
FinTech (Financial Technology) solutions have recently arised as the new applications, processes, products, or business models in the financial services industry, composed of one or more complementary financial services and provided as an end-to-end process via the Internet. You can find additional interesting information in this article.
What does Financial Compliance have to do with Text Analytics?
Significant growth in the volume and variety of data is due to the accumulation of unstructured text data—up to 80% of companies data is unstructured text. Companies collect massive amounts of documents, emails, social media, and other text-based information to get to know their customers better, offer customized services, or comply with federal regulations. However, most of this data is unused and untouched, as it cannot be treated as structured data.

Insights extraction
Powerful text-analytics applications in the finance industry allow focus on compliance and fraud prevention, with the power of understanding text just as native speakers do. For example, all electronic communications at financial institutions (email, chats and instant messages, etc) could be monitored to reduce the risk of market manipulation, fraudulent account activities, anti-trust/collusion, outside business activities, illegal political contributions, and sharing sensitive customer information.
The purpose of NLP (Natural Language Processing) in this use-case is to understand the content of communication threads through semantic interpretation, and to identify relationships and entities across threads in order to decide whether or a given message breaks compliance.
Moreover, a more straightforward yet more powerful implementation for those techniques is applying Financial Compliance over news feeds on economics, searching for any suspicious piece of information involving Persons or Organizations that might have committed financial offences. This use-case could help credit card companies and banks process huge amount of unstructured information. For example, in this scenario a bank could receive directly from the news (in real-time or from past articles) hints to clarify whether or not someone is a Politically Exposed Person (PEP), or a credit card company could deny financial services to someone allegedly involved in money laundering.
Modeling facts in Text Mining: SVO (Subject Verb Object) slots or ‘Who Did What’ clause by clause
The detection of those patterns for financial compliance are particularly though as they are heavily syntax-based. If someone committed a financial crime, natural languages gives several syntactic forms to the native speaker in order to express that fact. For example, in the case of English:
- Someone committed a financial crime: active voice, the suspect is the grammatical subject, preceding the verb
- A financial crime was committed by someone: passive voice, the suspect is an agent complement following the verb
- Someone accused someone else for committing a financial crime: the suspect is the direct object of an investigation verb
- Someone said someone else committed a financial crime: the suspect is the grammatical subject of an embedded clause, so there are two different facts in the same sentence with different grammatical subjects
At this point, we have shown what a productive NLP approach on this coverage should entail. It is pointless to model a pattern of mere raw combination of accusations, offences or persons mentioned in the sentence, specially in constituent-free-order natural languages (those ones that allows changes in canonical order of presentation for Subject, Verb, Object, as Spanish and remaining Romance languages do).
The most effective approach should work on the premise of detecting ‘who’ ‘did’ ‘what’ for every utterance included in the text. That is precisely the definition of clause: the minimum piece of text within sentences that while not necessarily grammatically autonomous can convey an autonomous fact.
If we were given with a reliable way of identifying those facts regardless the grammatical form they adopt in the text, we will just be able to write financial-compliance-based rules for detecting the alleged suspects of having committed financial crimes in rules as simple as the following sample code.
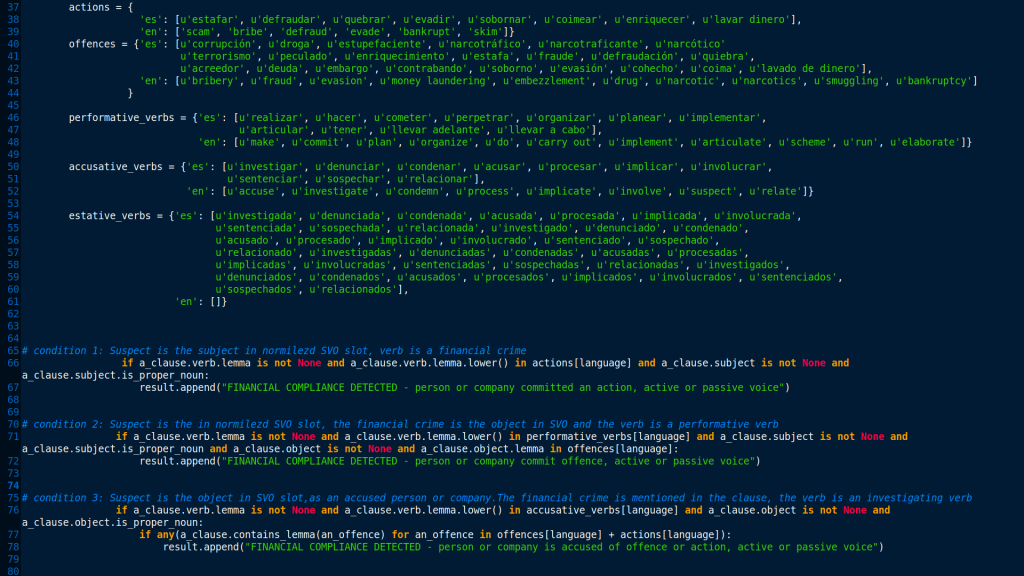
Sample code fragment
In order to do so, we need to extract first every clause in the text and normalize them under the form SVO or ‘who’ ‘did’ ‘what’ slots in canonical order. The kind of NLP engines that allows that are called parsers and the process requires full-parsing capabilities.
Extracting clauses through MeaningCloud full-parsing API
MeaningCloud offers public APIs to build a stack of powerful NLP products on top. You may check APIs test consoles and documentation in the APIs section of the developer area. The public APIs are free with a maximum of 20,000 requests on a monthly basis; you may get your API license key by registering at MeaningCloud or just by logging-in through your LinkedIn or GitHub accounts.
As stated before, we will use MeaningCloud’s Lemmatization, Pos and Parsing API for modeling clauses and financial compliance. The test console provided for the API will work as a test environment and will let you get familiar with the API input and output, as well as its operating parameters.
First, we will build an API connector to invoke MeaningCloud API with the following parameters enabled (request_params variable):
tt=a, to extract all topic typesverbose=y, to get the verbose outputlang=en, to analyze text in English
You can find all the necessary information about the request parameter in the documentation.
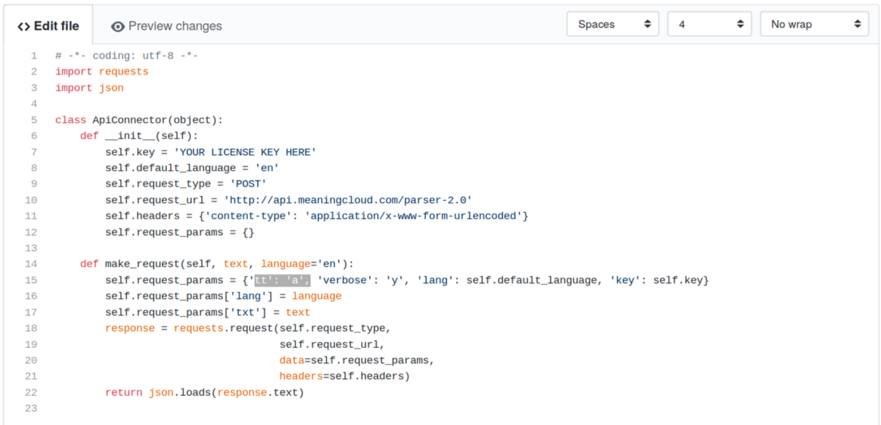
In the Dev Tools section you can find examples of how to do a request to the API in different programming languages.
Once the API connection has been established, you should be able to input text and get a fully-syntactic-and-semantic-featured tree as a JSON-formatted output.
This output is quite large as it describes a tree structure where each node contains all the morphological, syntactic and semantic information associated to the node (or token).
A complete description of the response and all the possibles fields you may find in it can be seen in the response section of the documentation.
Conclusion
In this post, we have covered how certain real-world problems based on texts can be approached under the premise of understanding natural language the way native speakers do, specifically through the format “who” “did” “what”.
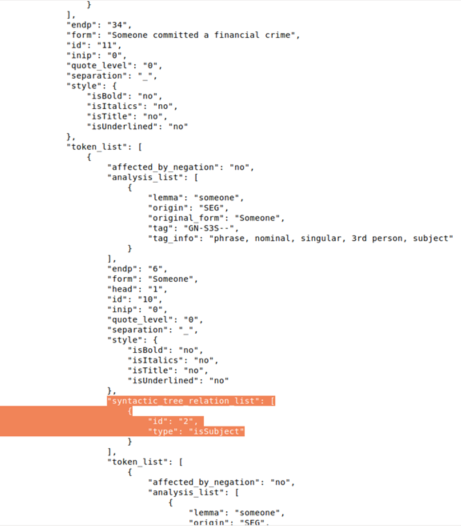
JSON tree detail
MeaningCloud offers a powerful API to implement that premise by modeling clauses of the form SVO (subject, verb, object) for every clause or fact that the text conveys. Stay tuned for a new post that will show how to convert that syntactic tree into normalized clauses of the form SVO and then, how to define straightforward financial-compliance-based rules.
