Scenarios that can benefit from unstructured content analysis are becoming more and more frequent: from industry or company news to processing contracts or medical records. However, as we know, this content does not lend itself to automatic analysis.
Text analytics has come to meet this need, providing powerful tools that allow us to discover topics, mentions, polarity, etc. in free-form text. This ability has made it possible to achieve an initial level of automatic understanding and analysis of unstructured documents, which has empowered a generation of context-sensitive semantic applications in areas such as Voice of the Customer analysis or knowledge management.
Entities and categories are not enough
Extracting isolated elements of information from the text is rarely sufficient. When documents are lengthy and complex (such as a contract) it is not enough to assign them a general category that classifies the document as a whole or to extract mentions of people, organizations, concepts, etc. that appear in it. This approach has limitations when it comes to finding or exploiting documents: the insights we draw from them need to be more actionable.
In summary, you need a more powerful analysis when the scenario involves:
- Complex documents with multiple sections or segments
- A need to extract deeper, more detailed data: complex patterns, relationships between elements, etc.
We call this more thorough analysis Deep Semantic Analytics.
Deep Semantic Analytics: Where?
Surely some of these situations are familiar to you:
- Think of a company that provides commercial information about businesses. In order to understand the “universe of companies” in a country, the company must analyze not only millions of structured financial statements, but also reports and financial filings (e.g. 10-K forms in the United States) that describe their activity and business in detail. The company would have to extract deep insights such as shareholder companies (with their participation percentage), investee companies, concentration of sales in certain clients, and so on. This requires a very sophisticated text analytics.
- In applications for news aggregation and monitoring in market and competitive intelligence contexts it is much clearer how this technology can be used. The application could detect not only mentions of certain companies/brands but also market-moving information in the form of complex relationships such as news about mergers and acquisitions, large projects, sale of assets, shortages of raw materials, etc.
- For a health care provider (hospitals, public health care administrations, or pharma companies), unstructured data contained in electronic medical records are a source of extraordinarily valuable information on relationships between symptoms, followed treatments, results, and more. Being able to automatically and massively extract this information from the files and mine it would allow for a better understanding of the prevalence of various diseases and how effective their treatments are.
- Legal documentation (contracts, agreements, cases, and sentences) is the paradigm of unstructured high-value content. Law firms and corporate legal departments would benefit from tools that allowed them to extract complex data such as parties in a contract, the terms of a particular clause, those affected by a legal procedure, and how they are affected. They could analyze, find connections, and understand legal documents better.
Let’s dig deeper into this last case.
What can you do in just a few minutes with a room full of contracts?
For a legal department or a law firm, “due diligence” can mean analyzing thousands of documents (typically contracts and the like) related to a company to get an idea of their situation and detect possible risks as soon as possible.
Traditionally, organizations have performed due diligence tasks in a manual way, categorizing and classifying the different documents with somewhat specialized human resources. This process is laborious, time-consuming, and subject to the mistakes and inconsistencies that are typical of human analysis, which are exacerbated by the burdensome time frames in which the task is to be carried out.
Let’s see how having a tool capable of performing Deep Semantic Analytics can simplify this work. This tool could perform the following tasks on a collection of contracts:
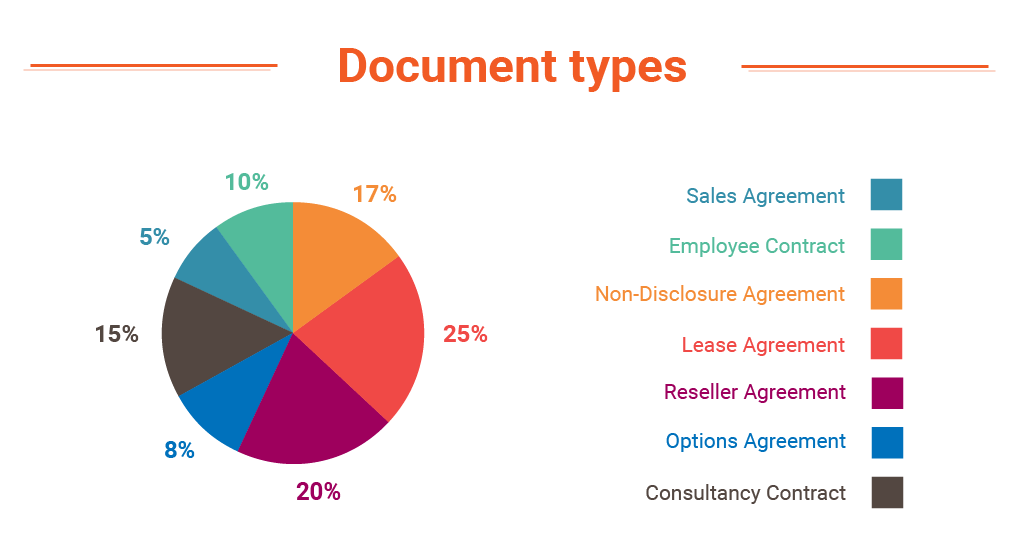
- Sort them by type of document; categorize them into groups such as Sales Agreement, Employee Contract, Non-Disclosure Agreement, Lease Agreement, Reseller Agreement, Options Agreement, Consultancy Contract, etc. (all example of types of documentation we have in our hands).
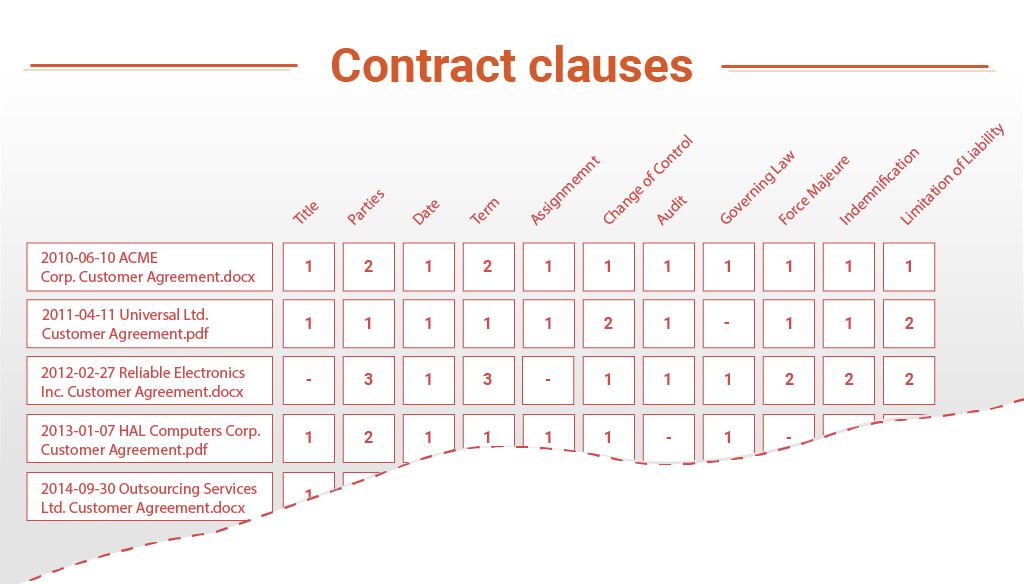
- Analyze them to detect and identify their clauses and other relevant parts, such as Title, Parties, Date, Term, Assignment, Change of Control, Audit, Governing Law, Force Majeure, Indemnification, Limitation of Liability, etc. At this stage, it would be necessary to detect if a clause is present or not, if it is similar to other examples of the same type that are considered acceptable, or if it has peculiarities that deserve a more detailed analysis.
- Within the different clauses, extract the key data and relationships, e.g.:
- In Parties, the complete and detailed identification of the participants.

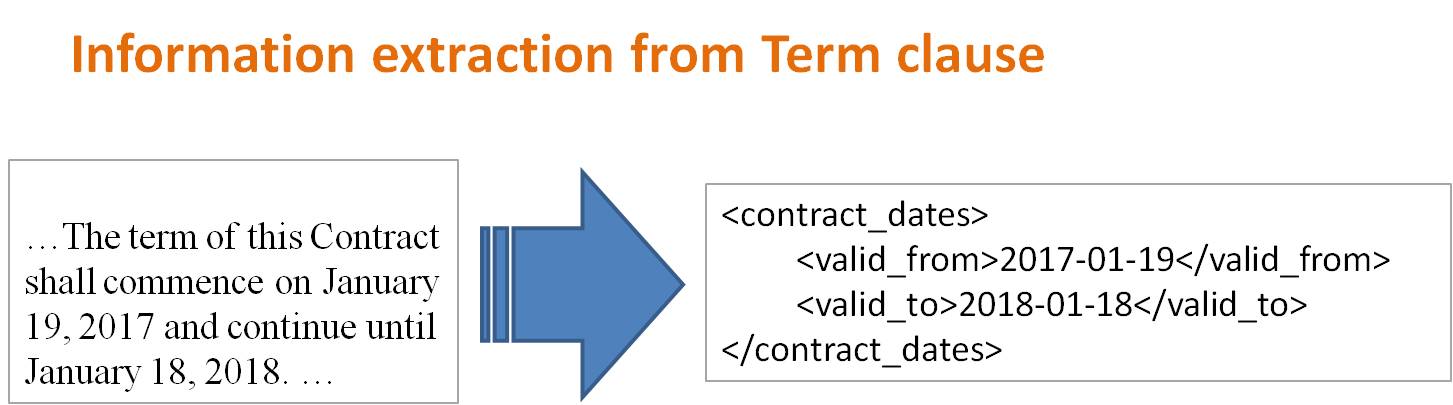
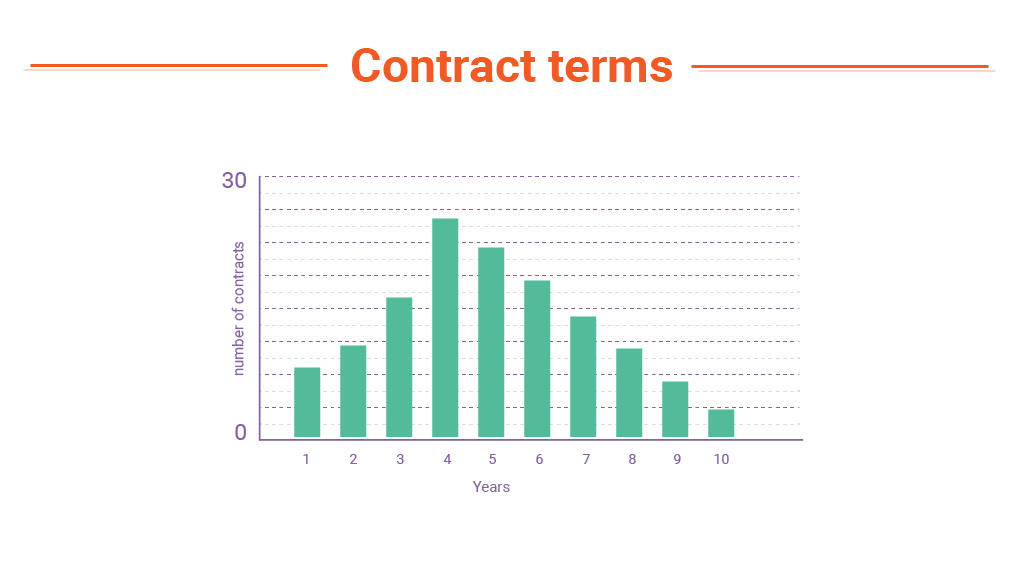
- In Term, the period during which the agreement is effective.
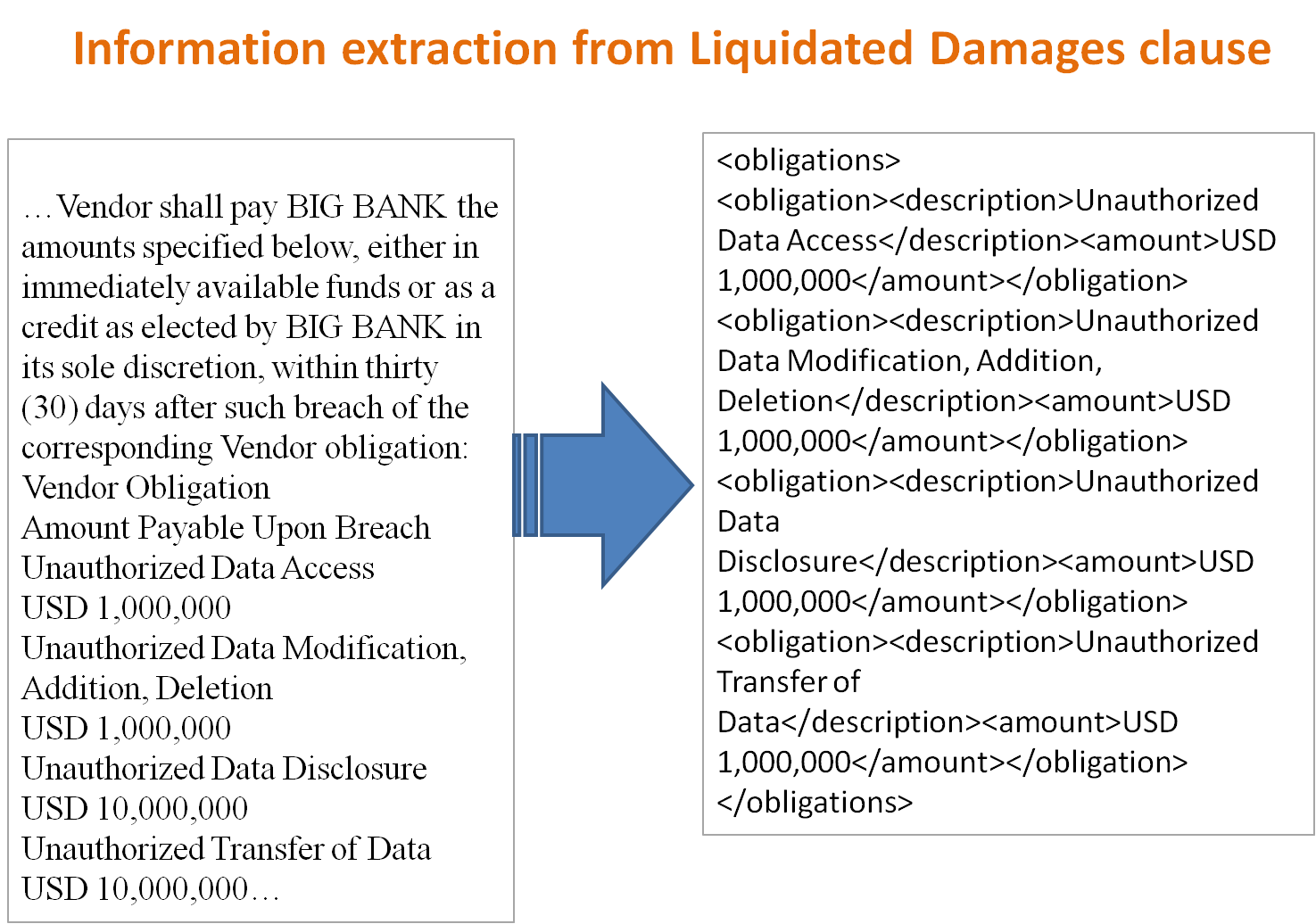
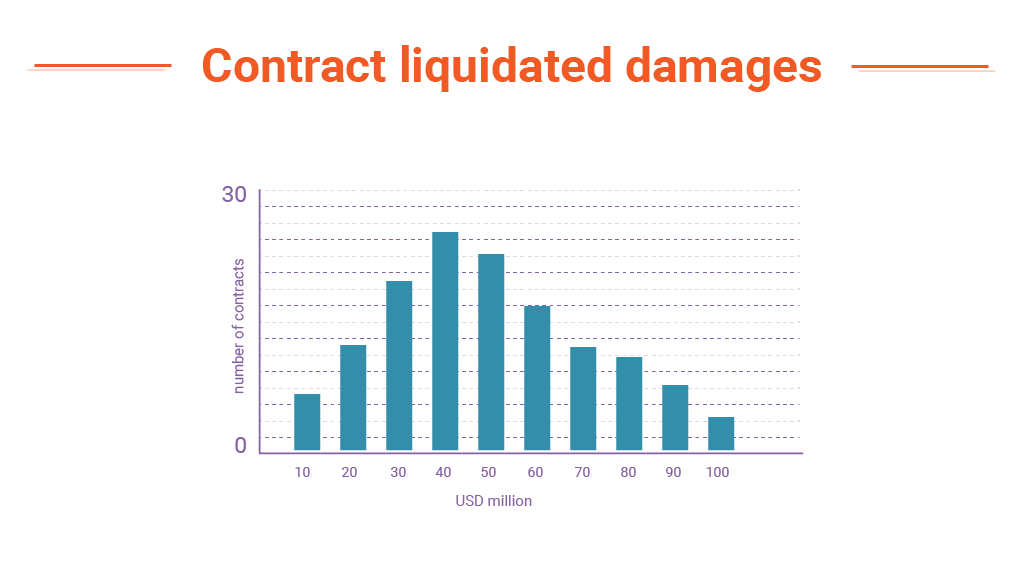
- In Liquidated Damages, the circumstances and amounts of indemnification in each case.
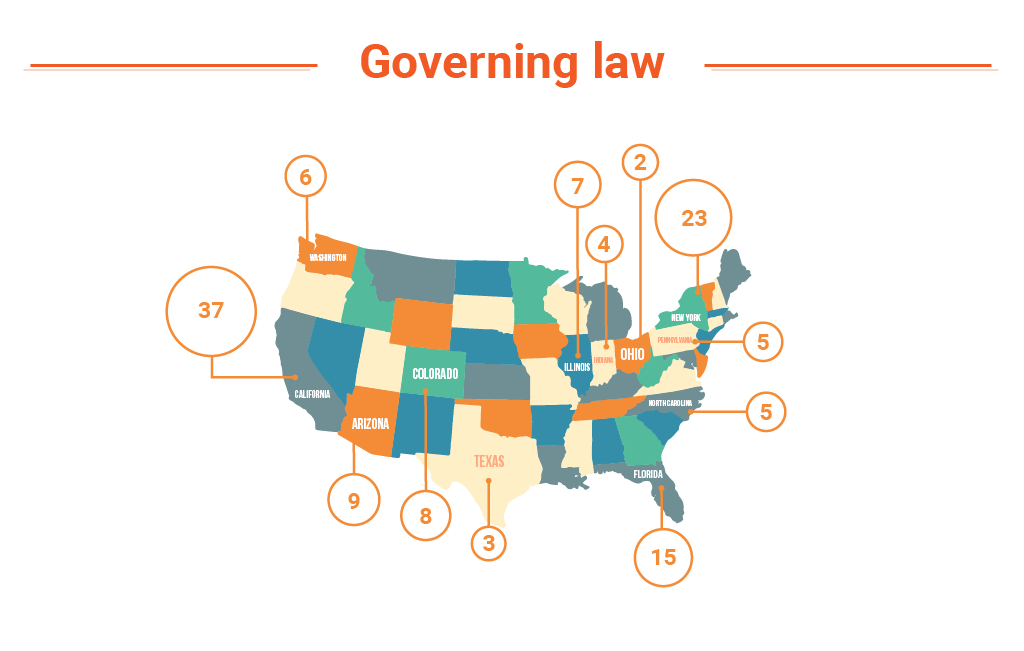
- In Governing Law, the jurisdiction whose laws will govern the interpretation of the terms of the contract.
- And the same for other clauses.
- Get valuable insights from the set of documents. Once all the documents have been analyzed, the individual results can be combined to obtain aggregated insights that give us an idea of the whole, such as the following:
- Chart by document types
- Table of clauses per contract
- Graphical distribution of terms
- Chart of geographical distribution of governing law
- Graphical distribution of liquidated damages
What do we need from a Deep Semantic Analytics solution?
Technology allows us to provide tailor-made solutions to extract defined data from certain types of documents. But when the variety of data and contexts is very broad and when information can be expressed in multiple ways this solution becomes a nightmare, difficult to adapt and maintain. If you are interested in performing Deep Semantics Analytics, your solution should have these characteristics:
- Ability to analyze information in various formats and presentations: text, PDF, Word, free format, tables
- High accuracy in insight extraction, regardless of application domain and specific language: legal, medical, economic, etc.
- Flexibility in the type of insights to be drawn (e.g., relationships between shareholders, indemnity terms) and productivity in their definition, with no need for massive system training or custom low level codifications
- Multilingual: although English is the language of business, news, financial reports, contracts, and clinical records are still being created in the languages of their countries of origin.
- High scalability, availability, and confidentiality: must have an architecture that guarantees smooth growth, continuous operation and information security
- Minimum costs and risk in its adoption: possibility to start using it without large investments, with flexible payment modalities
- Short time-to-benefit: minimize the time from need awareness to the moment when the solution delivers results.
Interested?
At MeaningCloud we are developing tools for Deep Semantic Analytics, which we have already deployed in beta on some clients in different languages: Spanish, English, and others. If you have a use case where you need to extract deep insights from the documents and would like to know if we can help you, do not hesitate to contact us at sales@meaningcloud.com.
