This is the second of two tutorials where we will be using MeaningCloud Extension for RapidMiner to extract insights that combine structured data with unstructured text. Read the first one here. To follow these tutorials you will need to have RapidMiner Studio and our Extension for RapidMiner installed on your machine (learn how here).
In this RapidMiner tutorial we shall attempt to extract a rule set that will predict the positivity/negativity of a review based on MeaningCloud’s topics extraction feature as well as sentiment analysis.
To be more specific, we will try to give an answer to the following question:
- Which topics have the most impact in a customer review and how do they affect the sentiment of the review that the user has provided?
For this purpose, we will use a dataset of food reviews that comes from Amazon. The dataset can be found here.
Importing and retrieving the data
This initial part of the tutorial is exactly the same as in our previous RapidMiner tutorial. So please follow the instructions there to import the data set, changing the format some of the columns, store the data set and retrieve it into the Process modeller.
You should end up seeing something like this on your Process modeller:
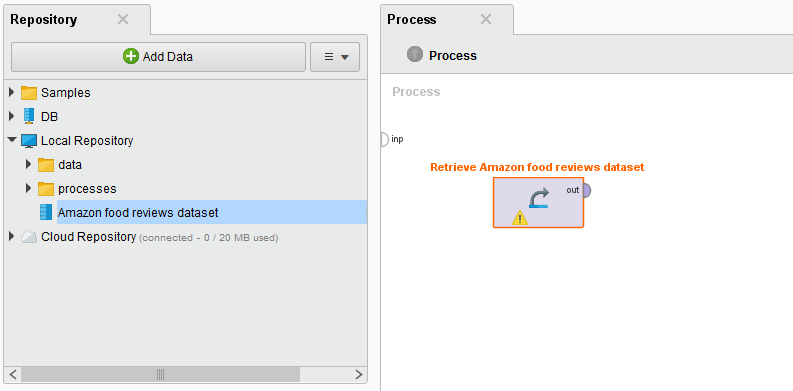
Sentiment analysis and selection of needed attributes
Now, once we have the dataset successfully loaded into our process the next step is to perform the sentiment analysis – we shall do this by using the MeaningCloud extension for RapidMiner (initially, make sure that you have the extension itself installed). Again, this is something that we already did in our previous tutorial.
Find the “Sentiment Analysis” operator and connect it in the process. Do not forget to enter your License Key as a parameter. Also, in the Parameters section choose the Attribute – Text as well as the language that is used in the text (English – en).
After we have added the “Sentiment Analysis” operator to the process we will need to select the attributes that we will use for the modelling part – we need the “Select Attributes” operator for this purpose. Drag this operator in the process modeller and connect it to the “Sentiment Analysis” operator that we mentioned previously. In the parameters section, select attribute filter type as subset and use the button Select Attributes… to access the selector dialog. Here, select the following attributes: HelpfulnessDenominator, HelpfulnessNumerator, Text and Polarity(Text). Your dialog should now look like this:
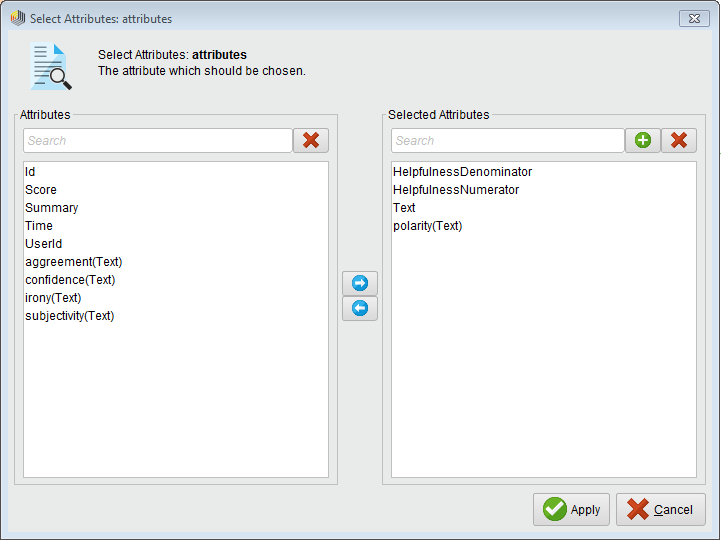
You may have noticed that we will not use the Score variable in the prediction. The Score and the Polarity (our class label) attributes are highly correlated which means that in our extracted rule model the Score variable will have a high impact on the classification – this is not something we desire. It is a better idea to base our model on the actual text content (topics extracted) as well as on the helpfulness of the review.
Topic extraction and sentiment analysis
After selecting the needed attributes, we will again use the MeaningCloud extension to extract the important topics from the review text. To achieve this, find the “Topics Extraction” operator and connect it to the “Select Attributes” (used in the previous step) operator in the process. Again, do not forget to enter your License Key as a parameter. Additionally, in the Parameters section choose Text as Attribute, the Text language that is used (English – en) and the Output language that you would prefer – also English in our case – from the suitable dropdowns:
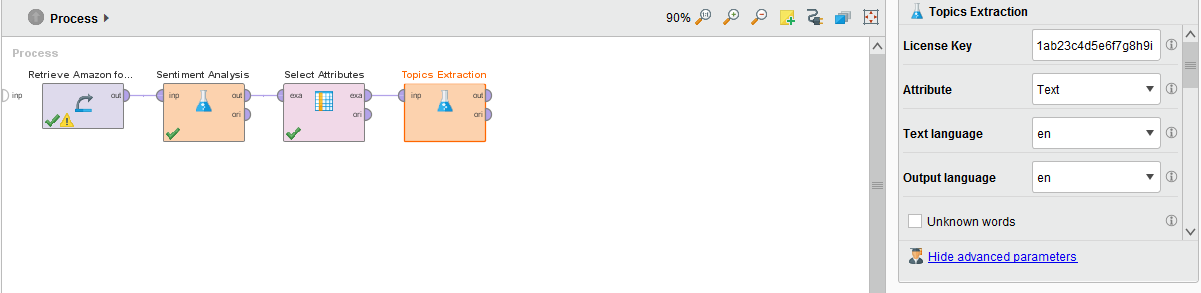
Data preprocessing
The model that we would like to extract from this dataset is a set of rules using the “Rule Induction” operator that is a part of the core of RapidMiner. However, before we can do the actual modelling, we will first need to do some preprocessing on the data that we now have after performing the topics extraction and the sentiment analysis. First, we need to exclude any examples in the dataset that may not have received a sentiment from the API (due to missing or uninterpretable text etc.) – this is achieved using the “Filter Examples” operator by adding the following filter (don’t forget to connect the operator to the output of the topics extraction operator):
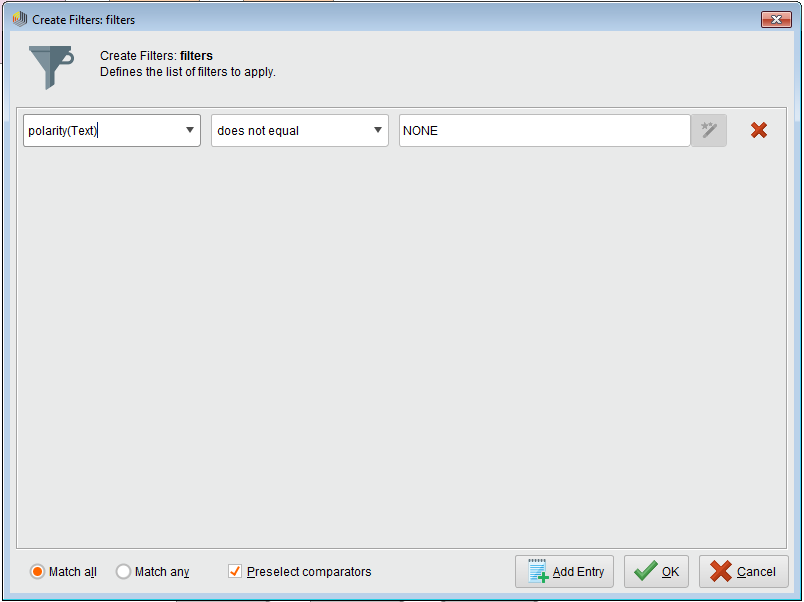
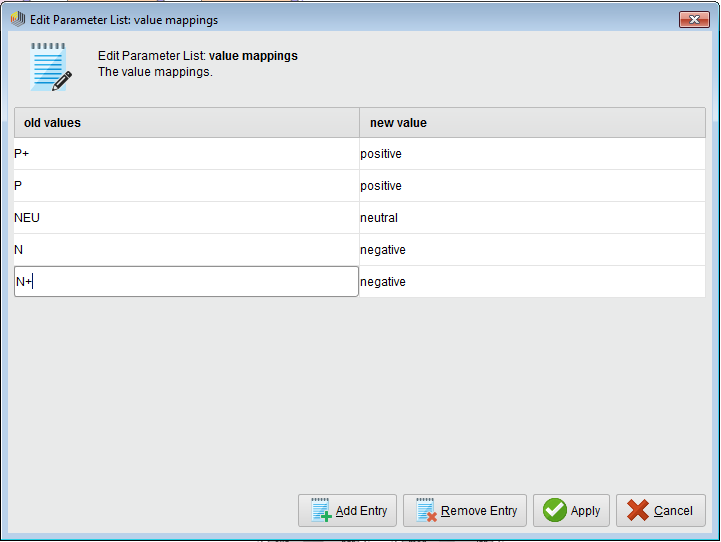
Now, since we are only interested in the positivity/neutrality/negativity of the reviews, we can merge the polarity classes that represent negative(N and N+)/positive(P and P+) sentiment into a single classes called negative and positive, appropriately. We will additionally give the NEU class the name neutral for consistency. We can use the “Map” operator for this purpose – with the following parameters:
attribute filter type – single
attribute – polarity(Text)
value mappings:
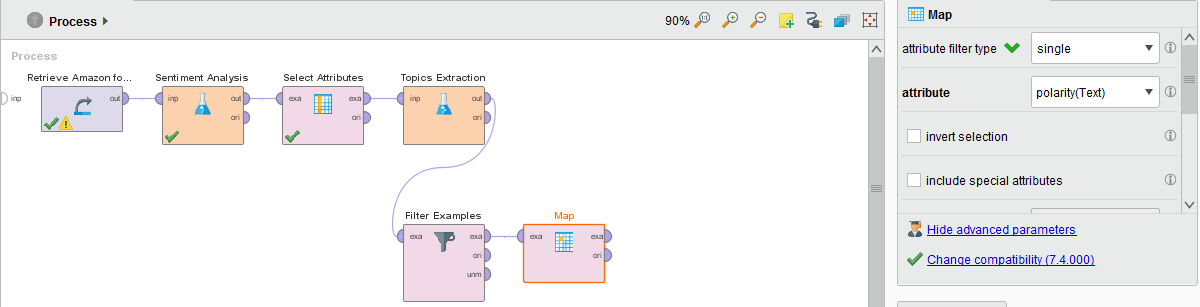
Your process should now have the following outline:
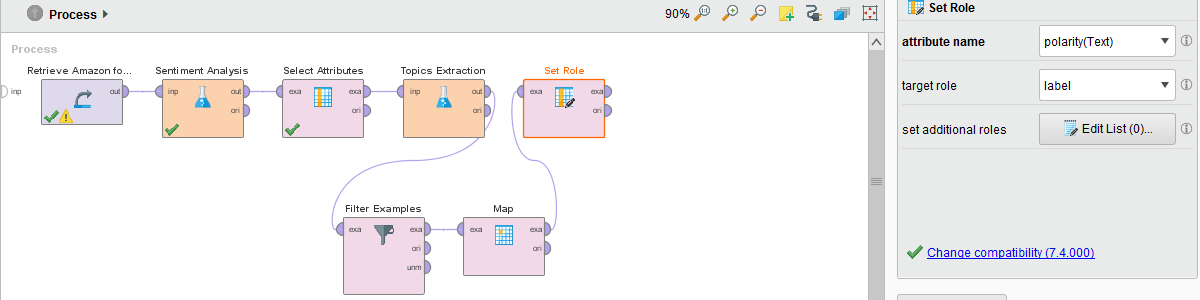
As a next step, we need to denote which is the label (category) column in the dataset. This is achieved using the “Set Role” operator by selecting polarity(Text) as the attribute name and label as the target role from the dropdown in the Parameters section. Your process outline should now look like this:
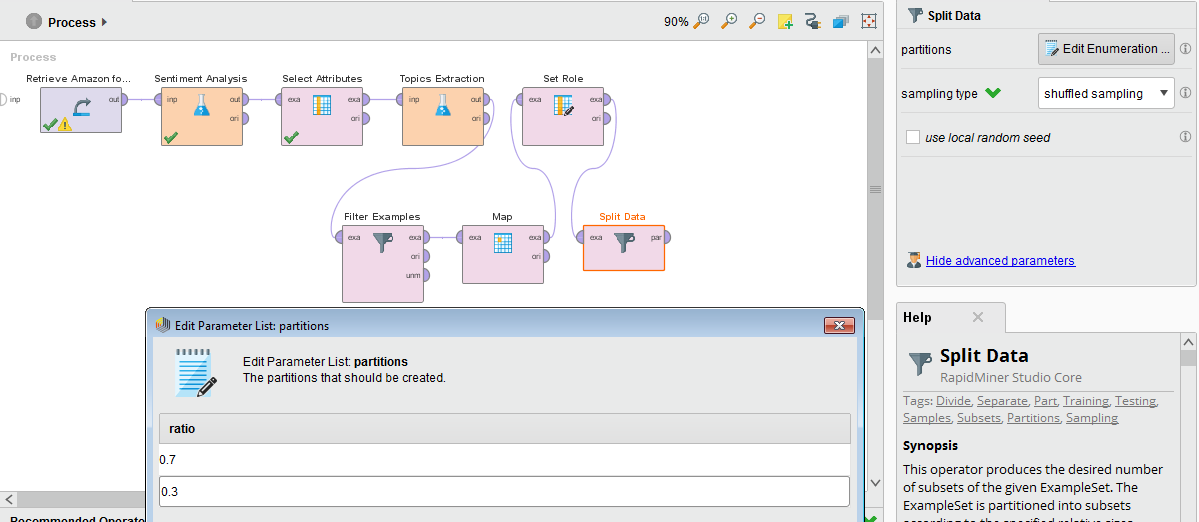
The last thing that we need to do to prepare our data for modelling is to split the dataset itself into two parts – the first of which we will use for the actual training of the model, and the second part that we will use to evaluate the performance of the model. This can be achieved by using the Split Data operator. Add it to your process and in its parameters section choose sampling type shuffled sampling from the dropdown. In the partitions parameter open the Edit Enumeration… and add a new entry by clicking on the Add Entry button at the bottom of the window. Next, enter 0.7 in the first row and 0.3 in the second row in the ratio table:
Now, we are finally ready to proceed to the most interesting part and train our model!
Modelling
To successfully predict the sentiment (negative, neutral and positive) we will use a technique called “Rule Induction” – available in RapidMiner through the operator with the same name. This is a standard machine learning technique which uses the RIPPER (Repeated Incremental Pruning to Produce Error Reduction) algorithm. We will not go into details on how this works, but if you are interested feel free to read the operator’s documentation or take a look at the paper “Fast Effective Rule Induction (1995)” by William W. Cohen.
Add the operator to your process and connect it to the first output port of the Split Data operator – this is important, the order of the output ports of the Split Data operator respects the order of the data that we split in the previous step. You do not need to adjust anything in the parameters of the operator, just leave everything as it is.
Now, in order to see how well our model performs, we shall use the “Apply Model” operator along with the “Performance” operator. Drag these operators into the process and connect the model output port (named mod) to the mod input port of the “Apply Model” operator; connect the second output port of the “Split Data” operator to the second input port of the Apply Model operator (called unl). Finally, connect the lab output port of the “Apply Model” operator to the lab input port of the “Performance” operator:
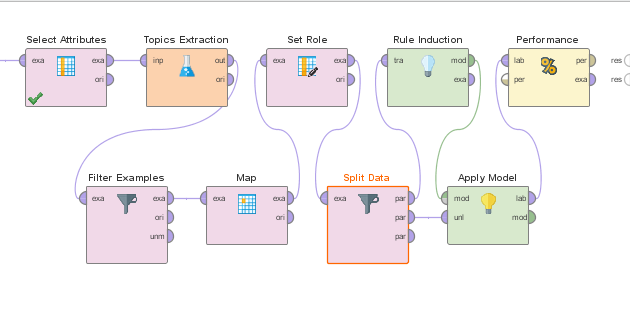
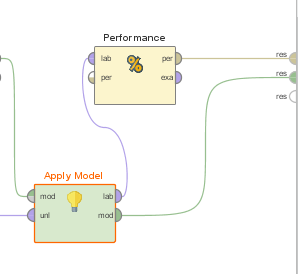
The final step here is to connect everything to the result ports of the process: 1) connect the per output port of the “Performance” operator to the first result port of the process; 2) connect the mod output port of the “Apply Model” operator to the second result port of the process:
Import the process
Don’t want to go through all the process creation steps? Just download the process specification Amazon fine food reviews dataset here and import it into RapidMiner by using the File, Import Process option.
Execute the process
Let’s now run the process and see the results of our work until now! Click on the Play button on RapidMiner button bar. Be aware that the execution may take quite some time, so be patient!
Results and conclusions
Once the execution is finished, we will get two different tabs with the results: one with the rules model from the “Rule Induction” operator, and another one with the performance vector from the Performance operator:
1) Extracted rules:
if HelpfulnessDenominator ≤ 0.500 and con_food ≤ 0.500 then positive (39 / 339 / 39) if con_product ≤ 0.500 and HelpfulnessNumerator > 1.500 and ent_tea > 0.500 then positive (1 / 25 / 2) if con_$ ≤ 0.500 and HelpfulnessNumerator > 0.500 and con_mistake ≤ 0.500 then positive (49 / 340 / 52) if HelpfulnessNumerator ≤ 0.500 and HelpfulnessDenominator ≤ 5 and con_chip ≤ 0.500 and con_restaurant ≤ 0.500 and con_beef ≤ 0.500 and ent_Science ≤ 0.500 and con_baby ≤ 0.500 and con_world ≤ 0.500 and con_pill ≤ 0.500 and ent_Food_and_Drug_Administration ≤ 0.500 and ent_HAM_Base ≤ 0.500 and con_consumer ≤ 0.500 and con_book ≤ 0.500 then positive (8 / 74 / 3) if con_snack > 0.500 then positive (0 / 3 / 0) if HelpfulnessDenominator > 11.500 and HelpfulnessNumerator > 13 then neutral (3 / 1 / 0) if HelpfulnessDenominator > 4.500 and HelpfulnessDenominator ≤ 7.500 then negative (0 / 0 / 3) if con_can > 0.500 and con_scratch ≤ 0.500 then positive (0 / 3 / 0) if HelpfulnessNumerator ≤ 2.500 and con_baby ≤ 0.500 then neutral (13 / 6 / 10) if HelpfulnessNumerator ≤ 9 then positive (2 / 7 / 2) else negative (0 / 0 / 1) correct: 811 out of 1025 training examples.
What we can see from the Rule Induction operator output is the total set of rules that we have managed to extract from our dataset along with the correctly classified training set examples. Here, it is easy to see how each concept and/or entity relates to the classes.
For example, let us look at the third extracted rule more closely:
if con_$ ≤ 0.500 and HelpfulnessNumerator > 0.500 and con_mistake ≤ 0.500 then positive (49 / 340 / 52)
Here, the first part (con_$ ≤ 0.500) states that the text analyzed should not have the concept of dollars ($) in it; the second part (HelpfulnessNumerator > 0.500) states that at least one user should have found the review helpful; and the third part (con_mistake ≤ 0.500) states that there should not be a mention of the concept of mistake in the review text – in this case the review is positive (which was the case for 340 out of 441 cases). It is quite interesting to see that in most cases when people don’t talk about the money in a product review, the review tends to be positive.
Another very simple rule that I am sure most people would agree with is:
if con_snack > 0.500 then positive (0 / 3 / 0)
When people talk about snacks, the review tends to be positive – well, who doesn’t like snacks?!
Going back to the point that we were interested in at the beginning of this tutorial:
- Which topics have the most impact in a customer review and how do they affect the sentiment of the review that the user has provided?
We can with quite a bit of certainty say that the absence of the concepts of “money” and “mistakes” make the list along with the presence of the “tea” entity and of course, “snacks”!
2) Performance view:
The second tab that we get as a result is the PerformanceVector view:
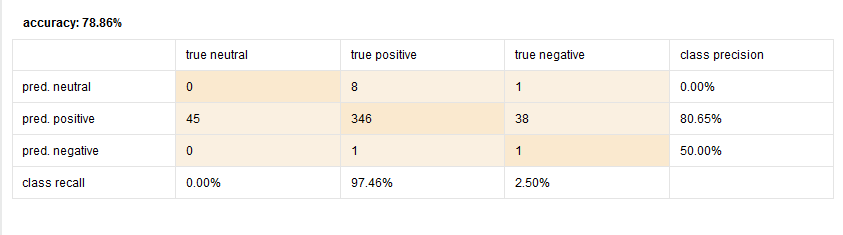
As we can see from the PerformanceVector, we have actually achieved an accuracy of 78.86% which is quite impressive – good work!
An ending note
You may have noticed that most of the examples that have been classified correctly are within the positive category. These results are quite nice, but one way to get even better results is to make a custom dictionary when extracting the topics and performing the sentiment analysis using MeaningCloud – more information about this feature can be found on the MeaningCloud website.

One thought on “RapidMiner: Impact of topics on the sentiment of textual product reviews”
Hi Antonio,
I’m getting to grips with this masterwork!
I’m using RapidMiner 9.51 community (record limit 10,000) on Windows 10, and a reasonable speed PC with good memory. I’ve let RapidMinder auto downsize the several hundred thousand original Amazon dataset to the limit, 10,000 limit, but would that be any reason to stop Rapid Miner from completing? It is 27 minutes so far…
I look forward to your thoughts. I’m sure this’ll be impressive when I’ve ironed out any mis-steps!
With kind regards
Chris Clark