If you love politics, regardless of your party or political orientation, you may know that election periods are exciting moments and having good information is a must to increase the fun. This is why you follow the news, watch or listen to political analysis programs on TV or radio, read surveys or compare different points of view from one or the other side.

American politics
Starting with this, we are publishing a series of tutorials where we will show how to use MeaningCloud for extracting interesting political insights to build your own political intel reports. MeaningCloud provides useful capabilities for extracting meaning from multilingual content in a simple and efficient way. Combining API calls with open source libraries in your favorite programming language is so easy and powerful at the same time that will awaken for sure the Political Data Scientist hidden inside of you. Be warned!
Our research objective is to analyze mentions to people, places, or entities in general in the Politics section of different news media. We will try to carry out an analysis that can answer the following questions:
- Which are the most popular names?
- Does their popularity depend on the political orientation of the newspaper?
- Is it correlated somehow to the popularity surveys or voting intentions polls?
- Do these trends change over time?
Before we begin
This is a technical tutorial in which we will develop some coding. However, we will try to guide you through the whole process, so everyone can follow the explanations and understand the purpose of the tutorial.
For the sake of generality and better understanding, we will focus on U.S. Politics in English, but obviously you can easily adapt the same analysis for your own country or (MeaningCloud supported) language.
And last but not least, this tutorial will use PHP as programming language for the code examples. However, any non-rookie programmer should be able to translate the scripts into any language of their choice.
Step 1: Getting a MeaningCloud license
The first step is, of course, to create an account in MeaningCloud if you haven’t already. Once you have done so, you can take a first look at the different APIs. There are two ways you can do this: by using the test console provided, or by downloading a starting client in your favorite language from the SDK sections.
Specifically, for our analysis, we will focus on the Topics Extraction API, which allows you to tag in any type of content names of people, places or organizations (known as named entities), in order to make it more findable and linkable to other contents.
Step 2: Selecting the information sources
As stated before, we will analyze articles in English about U.S. Politics. We have selected the Politics section of the following newspapers: The Washington Post, The Washington Times, The New York Times and Los Angeles Times. If you miss any of your interest, please feel free to add it to the list!
A possible solution to access this information could be to get the articles published in the web pages through web scraping, but it would be like using a sledgehammer to crack a nut! In this case, the easiest way is to use the RSS feeds available.
These are the RSS feeds provided by these media:
- The Washington Post: http://www.washingtonpost.com/rss
- The Washington Times: http://www.washingtontimes.com/feeds/
- The New York Times: http://www.nytimes.com/rss
- Los Angeles Times: http://www.latimes.com/rss
We selected the specific feeds of the Politics sections, one in The Washington Post, two in The Washington Times (including “Political Theater”), another one in The New York Times and two other in the Los Angeles Times (“Politics” and “Politics Now”).
Step 3: Downloading content from a RSS feed
Time for coding! PHP does not provide any native functionality for downloading RSS feeds, apart from the basic XML DOM management. However, there are lots of open-source alternatives. Among all, we have a preference for SimplePie, a superfast, easy-to-use RSS and Atom feed parser written in PHP that we use in different projects. Simply go to “Downloads” and get the minified version (currently version 1.3.1).
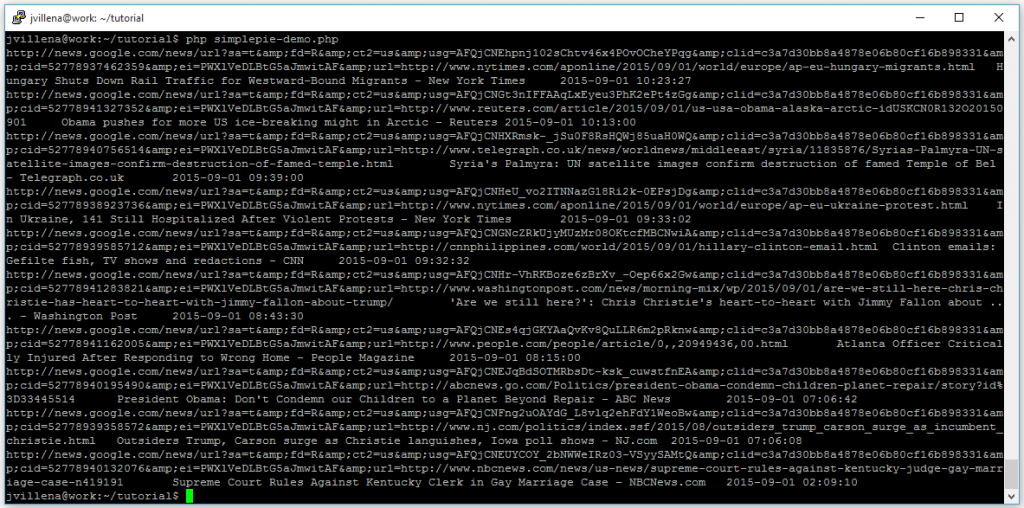
The following program shows how to read and display the contents of any given RSS feed, in this case Google News in the United States. We have written a function that encapsulates the functionality for creating the SimplePie object with the appropriate settings and downloading the items.
This figure shows the output after running this program. We will use this same process the RSS feeds we selected in the Step 2.
Step 4: Getting the topics
The next step is to call MeaningCloud’s Topics Extraction API to analyze and extract the named entities; the following program shows how we implemented this part. To run this code, you just need to copy a valid license key for accessing the API into the appropriate place.
Although the API call can be done using GET method, that is, through the native function file_get_contents in PHP, in general we recommend to use a POST request to avoid problems with request limits in HTTP. This functionality is implemented in the auxiliary postRequest function.
The function getEntities builds the API call with the necessary parameters, namely:
- key: MeaningCloud license key
- lang: language of the text, ‘en‘ for English
- tt: topic type, ‘e‘ for entities
- txt: actual text
- txtf: text format, ‘markup‘ if the text can contain HTML tags, as it is the case of news feeds
Quite easy, isn’t it?
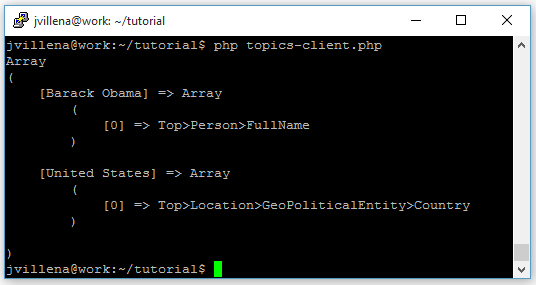
The function decodes the API’s response to JSON and stores the entities into an associative array indexed by form and including the semantic type of the entity. The output after running this program is shown in the figure on the right.
Step 5: Bringing it all together
Let’s bring it all together! The basic idea is: i) for each feed, get all items; ii) for each item, get entities; iii) for each entity, aggregate the information; iv) when finished, sort the data and print everything.
The complete program is shown next.
Some considerations:
- Items in RSS feeds contain title and content. Both are used to build the call to the Topics Extraction API, in HTML format.
- Language technologies are not perfect, and sometimes false positives or invalid entities are detected. The program uses the $STOPENTITIES array to ignore some listed entities from the API output that appear often in the domain we are working on.
- Because of the items’ limited amount of text content (just the title and one brief sentence in many occasions), sometimes the detected entities include partial identifications. For instance, given the text “Clinton awaits Biden’s answer on a presidential run, but she could be waiting awhile”, the API detects two surnames, “Clinton” and “Biden”, but is not able to relate them to Hillary Rodham Clinton and Joseph “Joe” Biden Jr. as no context is provided. The program uses the $MATCHING array to indicate the correct identification of the entities detected. Another possibility would be to define a user dictionary with the entities we want to focus on, and add there all their possible aliases. You can see an example on how to work with user dictionaries and aliases in this tutorial.
- For each entity, the program stores the list of its semantic entity types ($info array) and the list of URLs where it appears ($links array).
- Finally, the array is sorted by descending number of links (i.e. the most frequent entity appears first) and then printed on screen.
An actual example of the whole output after running the program is included here.
Step 6: Your own Politics Intel Report
So, not that we have results, how do we interpret them?
At the time of running this tutorial, 13:00 UTC on September 1st 2015, Hillary Clinton was mentioned in 16.9% of the articles, Barack Obama in 15.4% and Donald Trump in 13.9% (with the total of articles run totaling around 125). Is it in line with popularity rankings? And with the voting intention polls?
The following two tables show the complete ranking of people and other entities obtained from the texts.
| Person | Mentions | % |
| Hillary Clinton | 22 | 16.92% |
| Barack Obama | 20 | 15.38% |
| Donald Trump | 18 | 13.85% |
| Jeb Bush | 15 | 11.54% |
| Bernard Sanders | 6 | 4.62% |
| Rand Paul | 4 | 3.08% |
| Chris Christie | 4 | 3.08% |
| Joe Biden | 4 | 3.08% |
| Joseph Curl | 3 | 2.31% |
| Jorge Ramos | 3 | 2.31% |
| Scott Walker | 3 | 2.31% |
| Other Entity | Type | Mentions | % |
| GOP | PoliticalParty | 9 | 6.92% |
| White House | Facility | 8 | 6.15% |
| House of Representatives | Government | 4 | 3.08% |
| Supreme Court | 4 | 3.08% | |
| State Department | 3 | 2.31% | |
| Obamacare | Doctrine>Plan | 3 | 2.31% |
| Black Lives Matter | 3 | 2.31% | |
| Planned Parenthood | Top | 3 | 2.31% |
| Wall Street | StockMarket | 2 | 1.54% |
| Affordable Care Act | 2 | 1.54% | |
| Univision Commun | MediaCompany | 2 | 1.54% |
| Columbia University | 2 | 1.54% |
How often the different entities appear in the texts is just the tip of the iceberg. For instance, just think of the relationships and patterns you can find analyzing co-appearances.
| Location | Mentions | % |
| United States | 12 | 9.23% |
| Iowa | 9 | 6.92% |
| Texas | 5 | 3.85% |
| America | 5 | 3.85% |
| Alaska | 5 | 3.85% |
| Alabama | 4 | 3.08% |
| Florida | 4 | 3.08% |
| Washington | 4 | 3.08% |
| Wisconsin | 3 | 2.31% |
| New Hampshire | 3 | 2.31% |
On the right is the list of the top trending locations. Obviously the United States and America are often mentioned, but what are the reasons for the others? Are the states with earlier caucuses/primaries mentioned more often? Or is their importance in next year’s presidential election more important?
And what about the differences among newspapers? The exercise is left to you, but we can tell you in advance that Hillary Clinton is the most popular for The Washington Post and The New York Times, but The Washington Times clearly prefers Barack Obama. Jeb Bush is the winner in the Los Angeles Times and runner-up in The Washington Post, but the other two newspapers somewhat ignore him. Does this give you any hints?
Imagine that this run is repeated daily during several months and the set of popularity reports are compared: a trend analysis would be a piece of cake!
Step 7: What’s next?
Can you think of which concepts are associated with each politician? Do they speak more about internal affairs, economy, social issues…? In the next tutorial we will focus our attention on analyzing the key messages of the campaign. Stay tuned!
What information consumes is rather obvious: it consumes the attention of its recipients. Hence a wealth of information creates a poverty of attention, and a need to allocate that attention efficiently among the overabundance of information sources that might consume it.
Herbert Simon, Computers, Communications and the Public Interest (1971)

{kind=link}