Integrations with third-party software are something extremely useful: they allow you to use technology outside the tool you are using, giving you additional features outside its core functionality or just providing auxiliary tools to make your day to day easier.
One of the downsides is that you are limited by the functionality the integration provides. Usually, this is not much of a problem as standard integrations tend to cover the most common use cases, but in the case of tools that can be used in many scenarios, these uses cases may not be exactly what you need or want for your application.
MeaningCloud is not an exception to this. We provide many different APIs, each one of them with several types of analyses and with tons of possible applications. It’s not surprising that not all of them are included in MeaningCloud’s extension for RapidMiner.
If you want something like the global polarity Sentiment Analysis provides, then the extension for RapidMiner has you covered, but it may not be the case for other analyses. It can go from wanting to use a MeaningCloud API not included in the extension such as the Summarization API or to something as small as needing the label of the resulting categories in an automatic classification process instead of the code the extension provides.
Last year, RapidMiner published a new Python scripting extension: Execute Python. This operator allows you to run a Python script in RapidMiner, which enables you to include any processing you want and can code in a Python script in your RapidMiner process.
Using this new functionality and MeaningCloud’s Python SDK, we can create a Python script to use any of MeaningCloud APIs directly from RapidMiner. The SDK enables us to work with the API output easily and to extract whatever information we want to add to our RapidMiner processes.
Let’s see how we can do this!
1. Configuring Python in RapidMiner
The first step to be able to use an operator that runs Python scripts is, as you can guess, configuring Python in the environment where you have RapidMiner installed. This is what RapidMiner tells us about this step:
The [Execute Python] operator supports conda (anaconda) virtual environments, virtualenvwrapper virtual environments and you can select a Python binary, by specifying the full file system path to it as well. For more information on how to select the required Python, see the Parameters section of this help page. Note, that you may need to configure the extension. For this go to Settings -> Preferences menu (on Mac OS choose RapidMiner Studio -> Preferences). In the appearing settings panel select the Python Scripting tab. Edit the settings here, if required.
You can find here detailed information about configuring it in different environments.
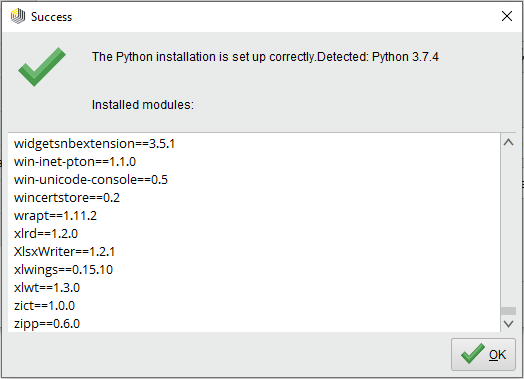
Once you’ve done this, the “Test” button available in the Preferences section should provide a list of the packages installed for the Python installation. The image above shows what this test looks like.
2. Developing a Python script that calls MeaningCloud
2.1 Defining the functionality
The objective of our script is to take a collection of texts (that we are loading from an Excel sheet) and for each one of them finds their global polarity, the most relevant named entities and concepts in them, and their IAB 2.0 classification. As we are working in RapidMiner, the result of our process will be an example set where four new columns will appear: Polarity, Entities, Concepts, and IAB2. Each one of them will contain the corresponding analysis for the text.
As far as data is concerned, in this tutorial we are going to use a classic: the restaurant reviews we’ve used in previous tutorials. This Excel sheet contains London restaurant reviews extracted from Yelp. There are two columns in it: “Restaurant” with the name of the restaurant the review refers to, and “Review” with the text of the review. There are a total of 30 reviews in the sheet.
2.2 Technical requirements
RapidMiner gives us a number of indications we have to follow in our Python script for it to run successfully in the operator:
- It must have a method with the name ‘rm_main‘ with as many arguments as connected input ports or alternatively a *args argument to use a dynamic number of attributes.
- The return values of the method ‘rm_main‘ are delivered to the connected output ports.
- Entries from the data type ‘pandas.DataFrames’ are converted to example sets.
There are two main takeaways from this: the main flow of our script will be called ‘rm_main‘, and we are going to use the pandas library, so we will need to have it installed in our environment.
We also know that we want to make requests to MeaningCloud’s APIs, so we will need:
- To have an account in MeaningCloud (if you don’t have one already!).
- To make requests to the MeaningCloud APIs that give us the analyses we want to obtain. In other words:
- Sentiment Analysis to extract the global polarity of the text.
- Topics Extraction to obtain the most relevant named entities and concepts.
- Deep Categorization to get the IAB 2.0 classification.
There are different ways of making requests to an API in Python, but as we are working with MeaningCloud’s APIs, we will use the Python SDK we’ve developed precisely for this.
Much the same way as the pandas library, we will need to install the meaningcloud-python package. Both dependencies are easily installed with the following commands:
pip install pandas pip install MeaningCloud-python
2.2 Writing the code
We know what we want to do, and we know some of the structure we need to implement it. The only thing left to do is to start coding!
These are some of the considerations we’ve taken into account:
- For named entities, we will include their ontology type in parentheses.
- For IAB 2.0 categories, we will extract the category label.
- When the result may contain several values, we will separate them using commas.
Below you can check the script we’ve come up with:
3. Run the process
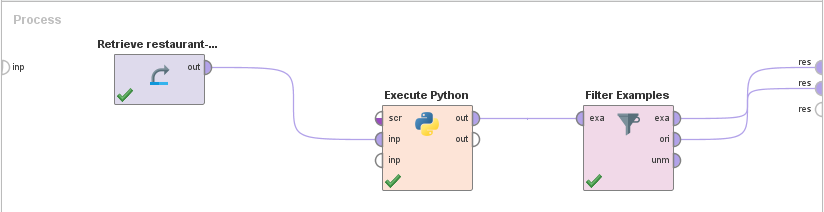
Now that we have the script we want to run, configuring the process to do it is very easy. We just have to:
- Set the Excel sheet we want to analyze as input.
- Load the script in the “script file” parameter of the Execute Python operator.
- (Optionally) Connect a filtering operator such as “Filter Examples“.
- Connect the output port.
This is what our process looks like:
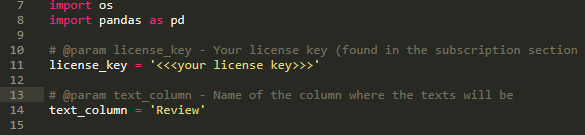
In the script, we will have to configure only two things:
- Your license key, which you can copy from the subscription section.
- The name of the column where the texts you want to analyze are (for our example Excel sheet, the column name is “Review”).
When these two fields are configured, we just have to start the execution and wait for the texts to be processed. If you have open the log tab, you will see the progress of the script or any errors that may occur during the execution.
This is what our results (without filtering) look like:

Once we have the results, we can do keep working with them, extracting statistics, visualizations, etc.
These are some of the charts we obtained using both the results extracted directly from the script as well as filtered results to obtain charts without empty values:
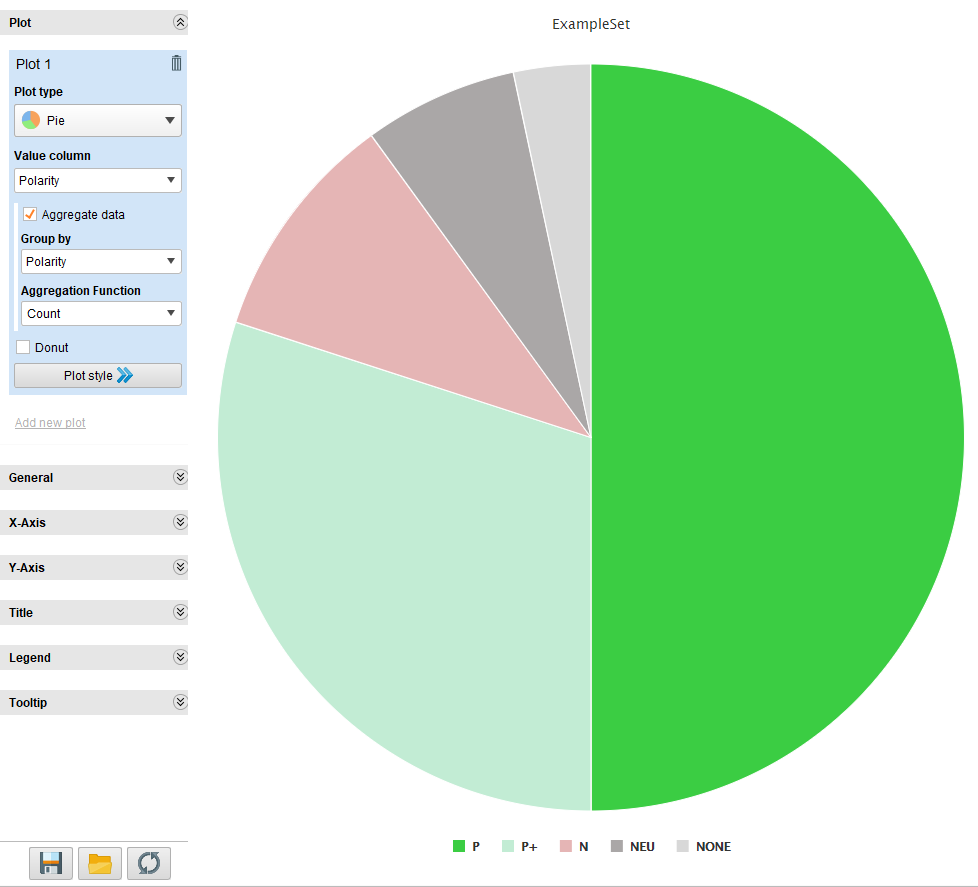
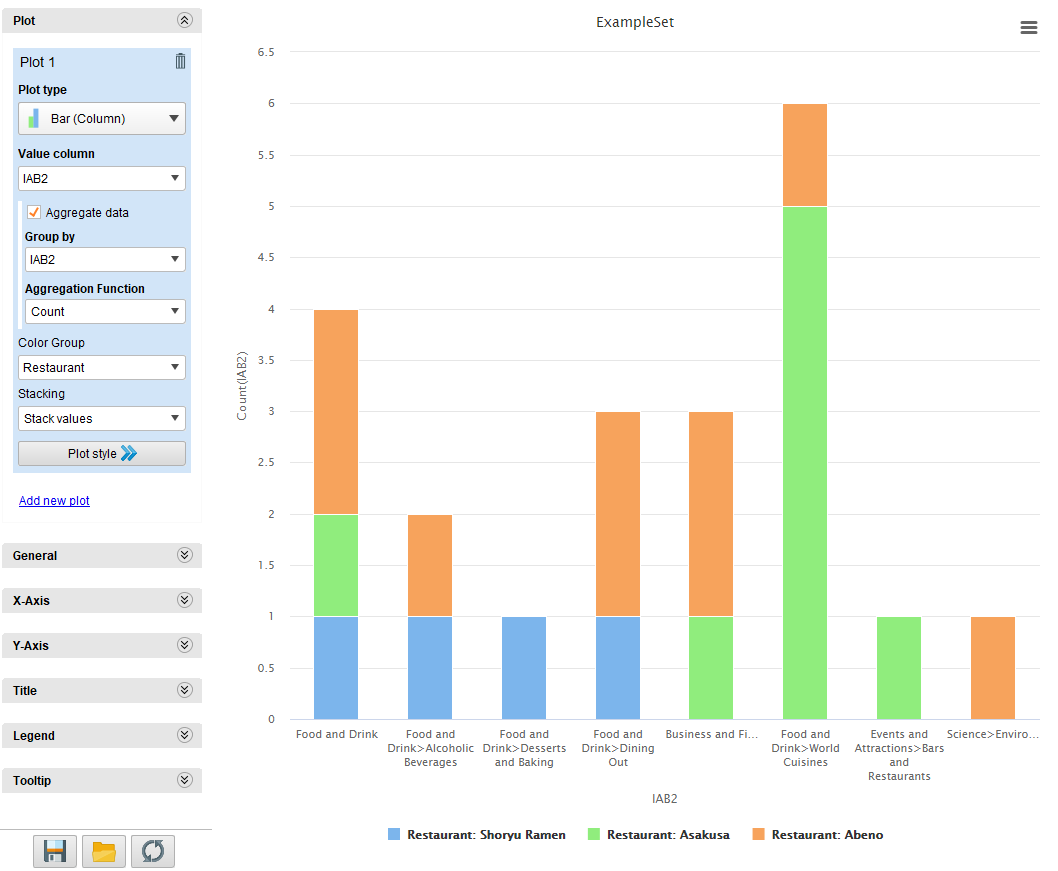
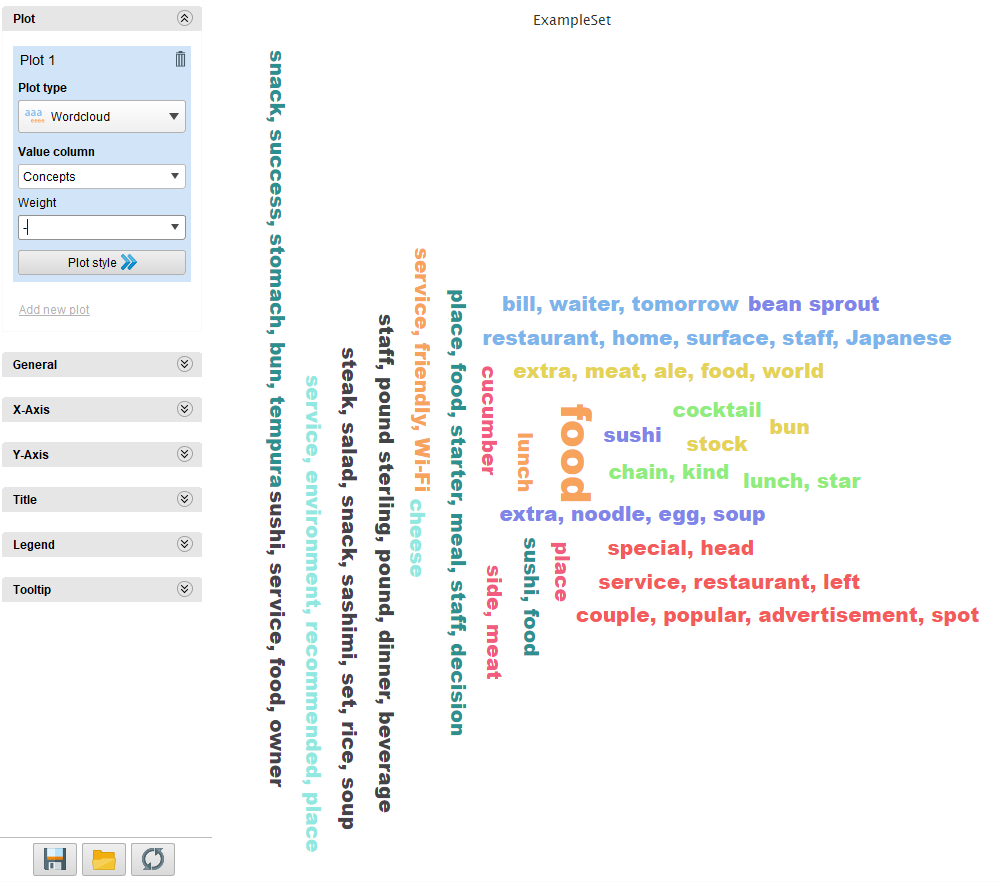
And that’s it! Easy peasy!
By combining MeaningCloud’s Python SDK and RapidMiner’s Python scripting extension, we can easily connect all the analyses (and customization features!) MeaningCloud provides. The SDK also provides an easier way of working with the APIs response, helping us reach easily the information we need from the MeaningCloud APIs and giving us a limitless integration with a powerful analytics/visualization tool such as RapidMiner.
If you have any questions, we’ll be happy to answer them at support@meaningcloud.com.
