MeaningCloud and University of Jaen have been the organizers of TASS, the Workshop on Semantic Analysis in Spanish language at SEPLN (International Conference of the Spanish Society for Natural Language Processing), again in 2018.
During the years, the research has extended to other tasks related to the processing of the semantics of texts that attempt to further improve natural language understanding systems. Apart from sentiment analysis, other tasks attracting the interest of the research community are stance classification, negation handling, rumor identification, fake news identification, open information extraction, argumentation mining, classification of semantic relations, and question answering of non-factoid questions, to name a few.
TASS 2018 was the 7th event of the series and was held in conjunction with the 34rd International Conference of the Spanish Society for Natural Language Processing, in Seville (Spain), on September 18th, 2018. Four research tasks were proposed. MeaningCloud sponsored this edition with prizes for the best systems in each of the tasks. A comprehensive description paper is (to be) published in Procesamiento del Lenguaje Natural journal, vol 62: TASS 2018: The Strength of Deep Learning in Language Understanding Tasks.
Task 1 and 2: Sentiment Analysis at global and aspect level
These tasks were renovated editions of the same task in previous editions: Task 1 focused on sentiment polarity categorization at global (tweet) level and Task 2 focused at sentiment polarity at aspect level. A new corpus was developed for the tasks, InterTASS, which included tweets written in different varieties of Spanish. Participants were provided with training and development corpora, both annotated with 4 different levels of opinion intensity (P, N, NEU, NONE), and, in Task 2, also with the aspect, the sentiment polarity and the sequence of context tokens. Participants were also provided with several test corpora to be used for evaluation. These tasks were organized by Universidad de Jaen (Spain).
The main challenges faced were the lack of context (tweets are short), the use of informal language (misspellings, emojis, onomatopeias are common), multilinguality (tweets written in Spanish from Spain, Peru and Costa Rica) and the need for generalization, as several datasets with different coverage, quality and extension, created since 2012, will be used for evaluation.
Five systems were presented for Task 1. Most of them made use of deep learning algorithms, combining different ways of obtaining the word embeddings. Only one system participated in Task 2. Detailed descriptions of the approaches and results can be accessed at the Proceedings of TASS 2018: Workshop on Semantic Analysis at SEPLN (TASS 2018) and also at Procesamiento del Lenguaje Natural journal, vol 62.

Example of tweets (Task 1 and 2)
Task 3: eHealth Knowledge Discovery
Task 3 proposed to model the human language in a scenario in which Spanish electronic health documents could be machine readable from a semantic point of view. This task focused on the categorization of semantic relations in the health domain, specifically, the development of semantic sequential tagging systems to automatically extract a large variety of knowledge from eHealth documents written in Spanish. Organizers were University of Alicante (Spain) and University of Habana (Cuba).
The input was a corpus of documents taken from MedlinePlus and manually annotated for this purpose. The task includes the identification of key phrases in the corpus, the classification of key phrases (assigning a label to each of them), and finally, setting the semantic relationships among the recognized entities. Six registered participants successfully concluded their participation. The best performing submissions included classic supervised learning, deep learning and knowledge-based techniques, showing that a variety of approaches, on the whole, deal effectively with the health knowledge discovery problem. More information about the approaches and results can be found in the workshop proceedings and the SEPLN journal.
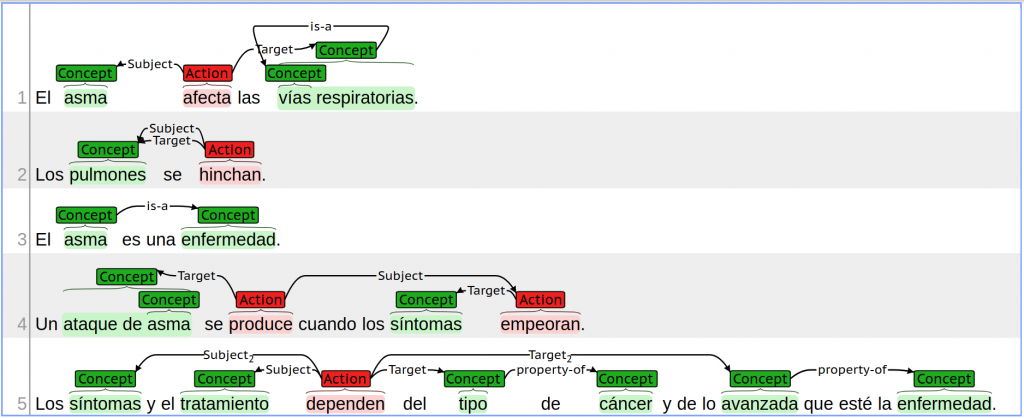
Example of classification of key phrases (Task 3)
Task 4: Emotional Categorization of News Articles
Task 4 focused on the identification of the emotions of news in the context of brand safety. When you read news about natural disasters, you usually feel negative emotions, and when you read news about the last championship won by your favorite football team, you usually feel positive emotions. If you want to promote your brand, you want the ads of your brand to be close to news that arouse positive emotions. Specifically, the objective was the development of systems that can classify whether a piece of news is safe (it can arouse positive emotions, so it is safe for the brand to place their ads in that page) or unsafe (it can arouse negative emotions so it could have some negative impact in the reputation of the company). This task was organized by MeaningCloud (Spain) and Universidad de Jaen (Spain).
Task 4 attracted the attention of seven teams. The best system proposed an ensemble classification system, which was composed of several and heterogeneous base systems and a genetic programming system that optimized the contribution of each base system in the final classification. Most of the other systems used deep neural networks. Again, detailed information about the approaches and results can be found in the workshop proceedings and the SEPLN journal.

Example of emotional categorization (Task 4)
Conclusion
The submitted systems are in line with the state-of-the-art in other similar workshops, and most of them are grounded in Deep Learning and the use of hand-crafted linguistic features. Therefore, TASS may be considered as a reference forum for setting up the state-of-the-art during all these years in semantic analysis in Spanish.
