Back when we were called Textalytics, we published a tutorial that showed how to carry out feature-level sentiment analysis for a specific domain: comic book reviews.

Marvel’s Black Widow #1
Since then, besides changing our name, we have improved our Sentiment Analysis API and how to customize the different analyses through our customization engine. In this post we are going to show you how to do a feature-level sentiment analysis using MeaningCloud.
One of the main changes in the latest release of our API is the possibility of using custom dictionaries in the detailed sentiment analysis provided by the Sentiment Analysis API. We are going to use comic book reviews to illustrate how to work, but the same process applies to any other fields where sentiment comes into play, such as hotel reviews, Foursquare tips, Facebook status updates or tweets about a specific event.
How do we do this?
The first step is, of course, to create an account in MeaningCloud if you haven’t already. Once you have done so, you have everything you need to take a first look at the results Sentiment Analysis provides. There are two ways you can do this: by using the test console provided, or by downloading a starting client in your favorite language from the SDK section.
The following script is an example of how a basic call to the API would be done in PHP:
In the response received, there are three main types of data:
- Global analyses of the text, which include polarity, irony and subjectivity detection.
- In-depth analysis at sentence level, with a detailed breakdown of the polarity terms found and the entities and concepts in each sentence.
- Aggregated analysis of the sentiment associated to the entities and concepts found in the text (feature-level sentiment analysis).
This post focuses on this last part, which is what in a sentence such as “It didn’t appeal to me, and while I thought the execution was delivered well and the dialogue was great, the overall story, in this particular issue, was so-so.” allows to identify that the polarity associated to “execution” is different from the one associated to “story” or “issue“.
Dealing with entities specific to your own domain
Secret identities are par for the course in the comic book domain, which in terms of name recognition means that, to detect correctly all the references to an entity, all the possible aliases of a characters have to be known. Comic book characters are counted in the thousands, so finding an API whose resources contain this kind of information is not very probable (unless you are Marvel, of course). The following text has been extracted from a review of Black Widow #1:
I could go on and on about this book. This was everything I wanted in a BLACK WIDOW comic. Nathan Edmondson comes out of the gate running. He has a great take on Natasha and reading this issue will immediately make you want more. Phil Noto’s art is insanely good. He creates a fantastic mood full of energy and makes Natasha look great without over sexualizing her. This is a comic anyone can easily dive into. Buy an extra copy or two and give them to your friends or loved ones. This is the book Black Widow and comic fans deserve. How many days until issue two?
In this text we have the example of Natasha Romanoff, code name “Black Widow”. The following is the sentiment analysis associated to entities that we’d obtain with a basic call:
Entities – Polarity (type)
==================
· Natasha – P+ (Top>Person>FirstName)
· Black Widow – NONE (Top)
· Nathan Edmondson – NONE (Top>Person>FullName)
· Phil Noto – NONE (Top>Person>FullName)
Black Widow and Natasha are detected as two different entities, and in a scenario where what we want to find is the aggregated polarity of the entity, we need to be able to detect all its appearances. With this in mind, our customization engine gives the possibility of specifying entities which includes among other attributes, their aliases. In this case what we want is to know that Black Widow and Natasha Romanoff are the same person, so what we will do is create a user dictionary — which we will call “comics-dict” — and then create an entry in it:
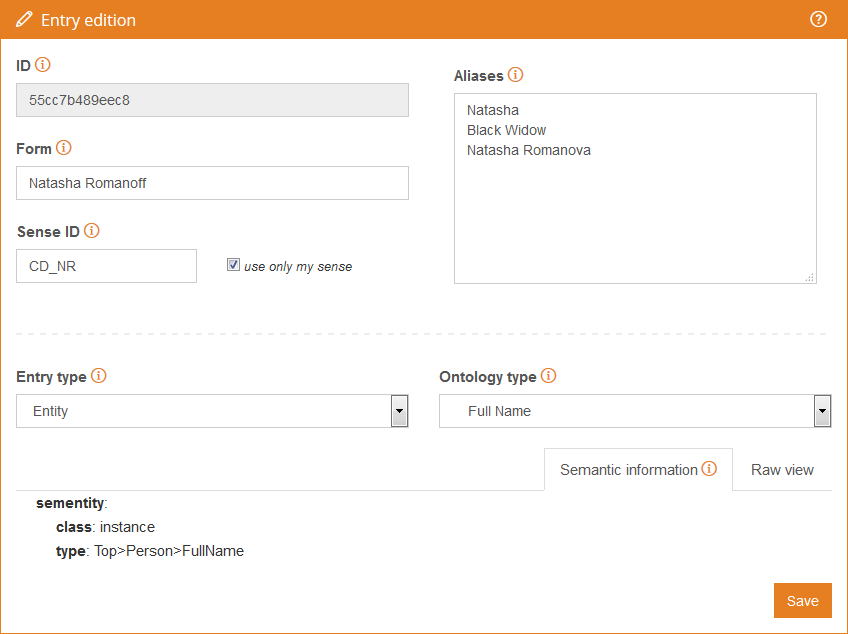
With the entry created, we can check how the output of Sentiment Analysis changes by adding the following line to the script included at the beginning.
$parameters[‘ud’] = “comics-dict”;
Through this parameter we are telling the Sentiment Analysis API to use the dictionary we have just created. With it the script will return all the entity appearances unified, and their aggregated polarity calculated:
Entities – Polarity (type)
==================
· Natasha Romanoff – P+ (Top>Person>FullName)
· Nathan Edmondson – NONE (Top>Person>FullName)
· Phil Noto – NONE (Top>Person>FullName)
Analyze the sentiment of your own concepts
The same thing can be done with concepts. In this case we want to check the review of Secret Avengers #16, and what it says about different aspects of the comic:
This was one of the most intriguing, dynamic storylines of the past year and it even had the decency to resolve itself in a satisfactory, satisfying way. The characters are hardly unscathed, but most of them may never remember exactly how they were scathed, as it were. There’s an amazing image of Maria Hill near the end of this issue where she gets a closeup that sums up so very much of this title. She knows what she has to do, but she hates that she has to do it. That’s the thinking that permeated the entire run.
Again, if we just carry out the basic call to Sentiment Analysis, we’ll see the sentiment associated to the basic concepts detected:
Concepts- Polarity (type)
==================
· character – P (Top>Person)
In the same way we did for entities, we will add to the dictionary we have created the concepts whose polarity we want to analyze. This feature is especially useful when we are working in domains where the concepts we are interested in are too generic to appear in the basic extraction (such as “image” or “issue” in this example), or in those domains imbued with technical language not contemplated by most APIs (for instance, the medical field).
And this is the result we obtain:
Concepts- Polarity (type)
==================
· character – P (Top>Person)
· image – P (Top>ComicAspect)
· issue – NONE (Top>Top>ComicAspect)
· storyline – P+ (Top>ComicAspect)
The same methodology we’ve applied to detect superheroes and different concepts specific to comics can be used to analyze easily and in-depth any domain where the objective is to extract information from a limited set of resources. A very common example would be analyzing cell phone reviews, where we’d have to add as entities the different models we are interested in, and the different features (screen, battery, etc.) as concepts.
Now you have both the tools and the knowledge to extract sentiment in any domain!
