
Finding committed employees is one of public and private organizations’ top priorities. Thus, listening to the Voice of the Employee by systematically collecting, managing and acting on the employee feedback on a variety of valuable topics is essential.
The relationship between Voice of the Employee (VoE) and Engagement is very similar to the one between Voice of the Customer (VoC) and Customer Experience. VoC provides information to improve customer experience. Voice of the Employee promotes employees’ engagement in the company and their work. See: Voice of the Employee, Voice of Customer and NPS
Voice of the Employee collects the needs, wishes, hopes, and preferences of the employees of a given company. VoE considers specific needs, such as salaries, career, health, and retirement, as well as implicit requirements to satisfy the employee and gain the respect of colleagues and managers.
Voice of the Employee Resources
VoE programs typically use a variety of methods to collect and analyze employee feedback, including surveys like eNPS, exit interviews, performance evaluations, employee forums, social networks, or focus groups.
Numerical or quantitative studies are essential to conducting a rigorous study, but people do not usually talk in numbers. In order to listen to the Voice of the Employee, we need to pay attention to what they actually say with their own words.
Thus, it is important to convert the VoE into important ideas and practices so that managers can motivate their employees’ engagement, increase productivity and boost profit.
Organizations often have data overload. That’s why VoE needs to use analysis platforms like MeaningCloud to extract the real hidden value of employees’ words. For this purpose, VoE analysis uses text analytics, sentiment analysis, and user profiling APIs. These technologies allow us to listen, analyze and measure information to improve the work environment.
VoE Data Analytics in MeaningCloud
Natural language processing is a real challenge because when used naturally by humans, language is full of ambiguity, polysemy, and synonyms that involve subtle connotations, irony, etc.
Even a text analysis performed by human experts is not perfect because of linguistic ambiguity; only 85-95% of their analyses coincide.
The quality of a text analysis system depends on both the technology and algorithms used and the linguistic resources (dictionaries, ontologies, morpho-syntactic analysis) incorporated into the process.
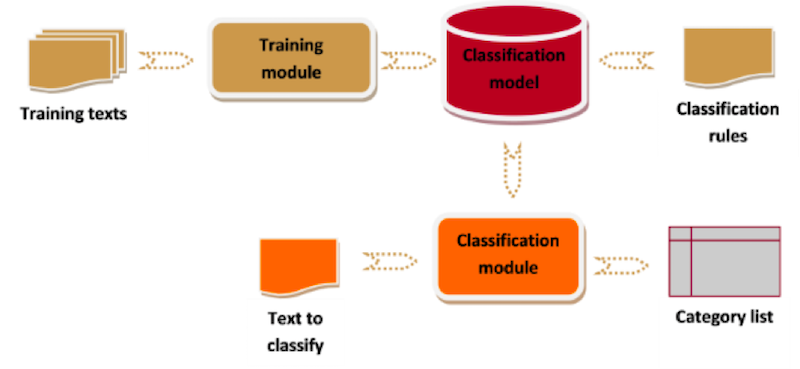
Data mining processes involve series of tasks which include classification or categorization. That is, assigning a text to one or more categories within a defined taxonomy and taking into account the source content as a whole. It also requires prior training of a classification model with the desired taxonomy that you’d like to use. This classification is used to identify possible topics in the text.
A classification model contains a list of categories, as well as resources needed to classify the documents within the defined classes. For example, a model could sort the reasons for leaving a company that employees mention in exit interviews.
The quality of the analysis is evaluated by looking at two factors: accuracy (the number of detected elements that are relevant) and exhaustiveness (the number of relevant elements that are detected). In general, accuracy and exhaustiveness are antagonists: improvements in one could worsen the other. The key to optimizing the application is to find a balance between both aspects.
MeaningCloud can help extract insights from the employees’ feedback with People Analytics, a text analytics solution for human resources.
MeaningCloud Classification Model for VoE
A classification model contains a list of the categories (taxonomy), as well as the resources needed to classify documents into the defined classes.
The classification process is based on a hybrid process that combines classification algorithms such as Support Vector Machines, which use example texts and linguistic rules to train the application and obtain the highest accuracy.
The workflow is shown in the following figure:
Text-based data sources are a key factor for any organization to understand the “whys”
Finding committed employees is one of public and private organizations’ top priorities. MeaningCloud can help extract insights from the employees’ feedback with People Analytics, a text analytics solution for human resources.
Listening to the Voice of the Employee (VoE) by systematically collecting, managing and acting on the employee feedback on a variety of valuable topics is essential. Since everyone wants to understand employees better, text-based data sources are a key factor for any organization to understand the “whys” and act on them to make improvements.

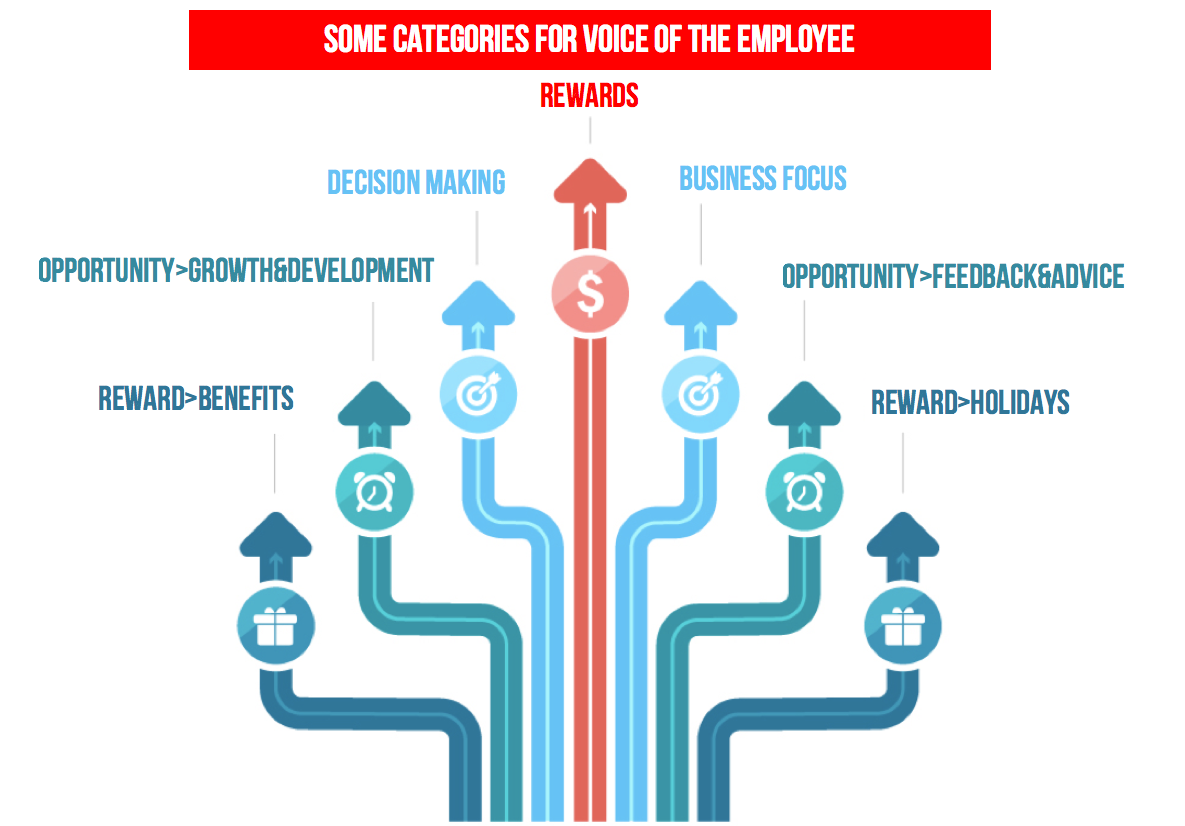
Taxonomy: Categories for Voice of the Employee
Reward Reward>Benefits Reward>Salary Reward>Holidays Opportunity Opportunity>Growth&Development Opportunity>Training Opportunity>Feedback&Advice Reward>Benefits Reward>Salary Reward>Holidays Opportunity Opportunity>Growth&Development Opportunity>Training Opportunity>Feedback&Advice Work Work>Collaboration&Cooperation Work>WorkEnvironment Work>Adaptability Work>Autonomy Work>Resource Work>Equipment Work>Process Work>Technology Work>Premises Policies&Practices Policies&Practices>Communication Policies&Practices>CustomerFocus Policies&Practices>Ethics Policies&Practices>CorporateCulture Policies&Practices>Innovation Policies&Practices>ContinuousImprovement Policies&Practices>EmployeeMotivation Policies&Practices>Work/LifeBalance Policies&Practices>CompanyCommitment 35 Policies&Practices>StaffManagement Management Management>DecisionMaking Management>BusinessFocus People People>EmployeeSatisfaction People>Engagement People>Loyalty People>Expertise People>Supervisor People>Co-Worker People>Teamwork People>InformationTechnology People>Department
Each category includes additional documents for training the algorithm learn for that particular category. The model also includes rules based on linguistic resources that improve accuracy for each category.
Many different machine learning algorithms have been applied to Natural Language Processing (NLP). Systems based on machine learning algorithms have many advantages over hand-made rules. They can be made more precise simply by providing more input data. Research is increasingly focused on statistic models, which take probabilistic decisions based on assigning real weight to each input characteristic. The advantage of these models is that they can express the relative certainty of all possible answers instead of just one, generating more reliable results.
Although NLP algorithms are used, linguistic resources are still essential for increasing the accuracy of the model. Machine learning algorithms can reach an accuracy threshold of 60-70%.
So, it is necessary to use linguistic resources to solve the difficulties of natural language. For example, if the name of a given programming language that the candidate mentions in his curriculum is not included in the resources, it won’t be detected in the analysis. On the other hand, if you’d like to identify what organization’s departments are mentioned, the text classification model must include particular categories representing each department.
Likewise, it is essential to apply rules to solve problems with ambiguity, polysemy and irony.
